 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiPhys: Multi-Person Physics-aware 3D Motion Estimation
Apr 18, 2024



We introduce MultiPhys, a method designed for recovering multi-person motion from monocular videos. Our focus lies in capturing coherent spatial placement between pairs of individuals across varying degrees of engagement. MultiPhys, being physically aware, exhibits robustness to jittering and occlusions, and effectively eliminates penetration issues between the two individuals. We devise a pipeline in which the motion estimated by a kinematic-based method is fed into a physics simulator in an autoregressive manner. We introduce distinct components that enable our model to harness the simulator's properties without compromising the accuracy of the kinematic estimates. This results in final motion estimates that are both kinematically coherent and physically compliant. Extensive evaluations on three challenging datasets characterized by substantial inter-person interaction show that our method significantly reduces errors associated with penetration and foot skating, while performing competitively with the state-of-the-art on motion accuracy and smoothness. Results and code can be found on our project page (http://www.iri.upc.edu/people/nugrinovic/multiphys/).
Morphological Symmetries in Robotics
Feb 23, 2024We present a comprehensive framework for studying and leveraging morphological symmetries in robotic systems. These are intrinsic properties of the robot's morphology, frequently observed in animal biology and robotics, which stem from the replication of kinematic structures and the symmetrical distribution of mass. We illustrate how these symmetries extend to the robot's state space and both proprioceptive and exteroceptive sensor measurements, resulting in the equivariance of the robot's equations of motion and optimal control policies. Thus, we recognize morphological symmetries as a relevant and previously unexplored physics-informed geometric prior, with significant implications for both data-driven and analytical methods used in modeling, control, estimation and design in robotics. For data-driven methods, we demonstrate that morphological symmetries can enhance the sample efficiency and generalization of machine learning models through data augmentation, or by applying equivariant/invariant constraints on the model's architecture. In the context of analytical methods, we employ abstract harmonic analysis to decompose the robot's dynamics into a superposition of lower-dimensional, independent dynamics. We substantiate our claims with both synthetic and real-world experiments conducted on bipedal and quadrupedal robots. Lastly, we introduce the repository MorphoSymm to facilitate the practical use of the theory and applications outlined in this work.
VQ-HPS: Human Pose and Shape Estimation in a Vector-Quantized Latent Space
Dec 13, 2023



Human Pose and Shape Estimation (HPSE) from RGB images can be broadly categorized into two main groups: parametric and non-parametric approaches. Parametric techniques leverage a low-dimensional statistical body model for realistic results, whereas recent non-parametric methods achieve higher precision by directly regressing the 3D coordinates of the human body. Despite their strengths, both approaches face limitations: the parameters of statistical body models pose challenges as regression targets, and predicting 3D coordinates introduces computational complexities and issues related to smoothness. In this work, we take a novel approach to address the HPSE problem. We introduce a unique method involving a low-dimensional discrete latent representation of the human mesh, framing HPSE as a classification task. Instead of predicting body model parameters or 3D vertex coordinates, our focus is on forecasting the proposed discrete latent representation, which can be decoded into a registered human mesh. This innovative paradigm offers two key advantages: firstly, predicting a low-dimensional discrete representation confines our predictions to the space of anthropomorphic poses and shapes; secondly, by framing the problem as a classification task, we can harness the discriminative power inherent in neural networks. Our proposed model, VQ-HPS, a transformer-based architecture, forecasts the discrete latent representation of the mesh, trained through minimizing a cross-entropy loss. Our results demonstrate that VQ-HPS outperforms the current state-of-the-art non-parametric approaches while yielding results as realistic as those produced by parametric methods. This highlights the significant potential of the classification approach for HPSE.
Estimating 3D Uncertainty Field: Quantifying Uncertainty for Neural Radiance Fields
Nov 03, 2023Current methods based on Neural Radiance Fields (NeRF) significantly lack the capacity to quantify uncertainty in their predictions, particularly on the unseen space including the occluded and outside scene content. This limitation hinders their extensive applications in robotics, where the reliability of model predictions has to be considered for tasks such as robotic exploration and planning in unknown environments. To address this, we propose a novel approach to estimate a 3D Uncertainty Field based on the learned incomplete scene geometry, which explicitly identifies these unseen regions. By considering the accumulated transmittance along each camera ray, our Uncertainty Field infers 2D pixel-wise uncertainty, exhibiting high values for rays directly casting towards occluded or outside the scene content. To quantify the uncertainty on the learned surface, we model a stochastic radiance field. Our experiments demonstrate that our approach is the only one that can explicitly reason about high uncertainty both on 3D unseen regions and its involved 2D rendered pixels, compared with recent methods. Furthermore, we illustrate that our designed uncertainty field is ideally suited for real-world robotics tasks, such as next-best-view selection.
Implicit Shape and Appearance Priors for Few-Shot Full Head Reconstruction
Oct 12, 2023



Recent advancements in learning techniques that employ coordinate-based neural representations have yielded remarkable results in multi-view 3D reconstruction tasks. However, these approaches often require a substantial number of input views (typically several tens) and computationally intensive optimization procedures to achieve their effectiveness. In this paper, we address these limitations specifically for the problem of few-shot full 3D head reconstruction. We accomplish this by incorporating a probabilistic shape and appearance prior into coordinate-based representations, enabling faster convergence and improved generalization when working with only a few input images (even as low as a single image). During testing, we leverage this prior to guide the fitting process of a signed distance function using a differentiable renderer. By incorporating the statistical prior alongside parallelizable ray tracing and dynamic caching strategies, we achieve an efficient and accurate approach to few-shot full 3D head reconstruction. Moreover, we extend the H3DS dataset, which now comprises 60 high-resolution 3D full head scans and their corresponding posed images and masks, which we use for evaluation purposes. By leveraging this dataset, we demonstrate the remarkable capabilities of our approach in achieving state-of-the-art results in geometry reconstruction while being an order of magnitude faster than previous approaches.
PoseFix: Correcting 3D Human Poses with Natural Language
Sep 15, 2023



Automatically producing instructions to modify one's posture could open the door to endless applications, such as personalized coaching and in-home physical therapy. Tackling the reverse problem (i.e., refining a 3D pose based on some natural language feedback) could help for assisted 3D character animation or robot teaching, for instance. Although a few recent works explore the connections between natural language and 3D human pose, none focus on describing 3D body pose differences. In this paper, we tackle the problem of correcting 3D human poses with natural language. To this end, we introduce the PoseFix dataset, which consists of several thousand paired 3D poses and their corresponding text feedback, that describe how the source pose needs to be modified to obtain the target pose. We demonstrate the potential of this dataset on two tasks: (1) text-based pose editing, that aims at generating corrected 3D body poses given a query pose and a text modifier; and (2) correctional text generation, where instructions are generated based on the differences between two body poses.
InstantAvatar: Efficient 3D Head Reconstruction via Surface Rendering
Aug 10, 2023



Recent advances in full-head reconstruction have been obtained by optimizing a neural field through differentiable surface or volume rendering to represent a single scene. While these techniques achieve an unprecedented accuracy, they take several minutes, or even hours, due to the expensive optimization process required. In this work, we introduce InstantAvatar, a method that recovers full-head avatars from few images (down to just one) in a few seconds on commodity hardware. In order to speed up the reconstruction process, we propose a system that combines, for the first time, a voxel-grid neural field representation with a surface renderer. Notably, a naive combination of these two techniques leads to unstable optimizations that do not converge to valid solutions. In order to overcome this limitation, we present a novel statistical model that learns a prior distribution over 3D head signed distance functions using a voxel-grid based architecture. The use of this prior model, in combination with other design choices, results into a system that achieves 3D head reconstructions with comparable accuracy as the state-of-the-art with a 100x speed-up.
On discrete symmetries of robotics systems: A group-theoretic and data-driven analysis
Feb 21, 2023



In this work, we study discrete morphological symmetries of dynamical systems, a predominant feature in animal biology and robotic systems, expressed when the system's morphology has one or more planes of symmetry describing the duplication and balanced distribution of body parts. These morphological symmetries imply that the system's dynamics are symmetric (or approximately symmetric), which in turn imprints symmetries in optimal control policies and in all proprioceptive and exteroceptive measurements related to the evolution of the system's dynamics. For data-driven methods, symmetry represents an inductive bias that justifies data augmentation and the construction of symmetric function approximators. To this end, we use group theory to present a theoretical and practical framework allowing for (1) the identification of the system's morphological symmetry group $\G$, (2) data-augmentation of proprioceptive and exteroceptive measurements, and (3) the exploitation of data symmetries through the use of $\G$-equivariant/invariant neural networks, for which we present experimental results on synthetic and real-world applications, demonstrating how symmetry constraints lead to better sample efficiency and generalization while reducing the number of trainable parameters.
Visual Semantic Relatedness Dataset for Image Captioning
Jan 20, 2023



Modern image captioning system relies heavily on extracting knowledge from images to capture the concept of a static story. In this paper, we propose a textual visual context dataset for captioning, in which the publicly available dataset COCO Captions (Lin et al., 2014) has been extended with information about the scene (such as objects in the image). Since this information has a textual form, it can be used to leverage any NLP task, such as text similarity or semantic relation methods, into captioning systems, either as an end-to-end training strategy or a post-processing based approach.
Belief Revision based Caption Re-ranker with Visual Semantic Information
Sep 16, 2022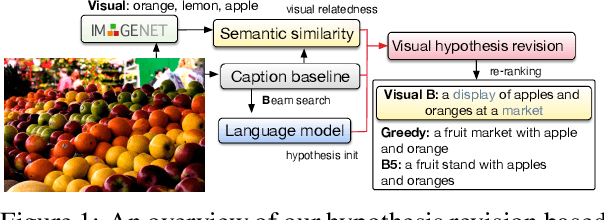
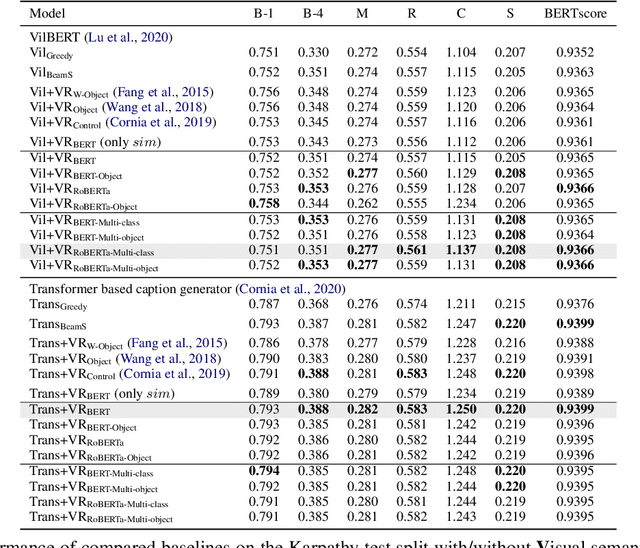
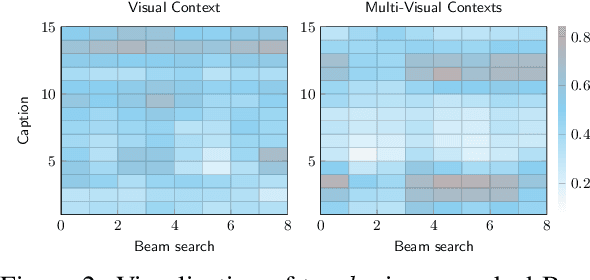
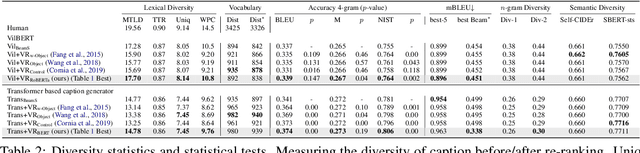
In this work, we focus on improving the captions generated by image-caption generation systems. We propose a novel re-ranking approach that leverages visual-semantic measures to identify the ideal caption that maximally captures the visual information in the image. Our re-ranker utilizes the Belief Revision framework (Blok et al., 2003) to calibrate the original likelihood of the top-n captions by explicitly exploiting the semantic relatedness between the depicted caption and the visual context. Our experiments demonstrate the utility of our approach, where we observe that our re-ranker can enhance the performance of a typical image-captioning system without the necessity of any additional training or fine-tuning.