 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGimbalDiffusion: Gravity-Aware Camera Control for Video Generation
Dec 09, 2025


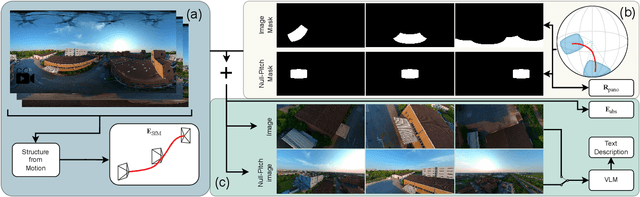
Recent progress in text-to-video generation has achieved remarkable realism, yet fine-grained control over camera motion and orientation remains elusive. Existing approaches typically encode camera trajectories through relative or ambiguous representations, limiting explicit geometric control. We introduce GimbalDiffusion, a framework that enables camera control grounded in physical-world coordinates, using gravity as a global reference. Instead of describing motion relative to previous frames, our method defines camera trajectories in an absolute coordinate system, allowing precise and interpretable control over camera parameters without requiring an initial reference frame. We leverage panoramic 360-degree videos to construct a wide variety of camera trajectories, well beyond the predominantly straight, forward-facing trajectories seen in conventional video data. To further enhance camera guidance, we introduce null-pitch conditioning, an annotation strategy that reduces the model's reliance on text content when conflicting with camera specifications (e.g., generating grass while the camera points towards the sky). Finally, we establish a benchmark for camera-aware video generation by rebalancing SpatialVID-HQ for comprehensive evaluation under wide camera pitch variation. Together, these contributions advance the controllability and robustness of text-to-video models, enabling precise, gravity-aligned camera manipulation within generative frameworks.
SpotLight: Shadow-Guided Object Relighting via Diffusion
Nov 27, 2024Recent work has shown that diffusion models can be used as powerful neural rendering engines that can be leveraged for inserting virtual objects into images. Unlike typical physics-based renderers, however, neural rendering engines are limited by the lack of manual control over the lighting setup, which is often essential for improving or personalizing the desired image outcome. In this paper, we show that precise lighting control can be achieved for object relighting simply by specifying the desired shadows of the object. Rather surprisingly, we show that injecting only the shadow of the object into a pre-trained diffusion-based neural renderer enables it to accurately shade the object according to the desired light position, while properly harmonizing the object (and its shadow) within the target background image. Our method, SpotLight, leverages existing neural rendering approaches and achieves controllable relighting results with no additional training. Specifically, we demonstrate its use with two neural renderers from the recent literature. We show that SpotLight achieves superior object compositing results, both quantitatively and perceptually, as confirmed by a user study, outperforming existing diffusion-based models specifically designed for relighting.
ZeroComp: Zero-shot Object Compositing from Image Intrinsics via Diffusion
Oct 10, 2024



We present ZeroComp, an effective zero-shot 3D object compositing approach that does not require paired composite-scene images during training. Our method leverages ControlNet to condition from intrinsic images and combines it with a Stable Diffusion model to utilize its scene priors, together operating as an effective rendering engine. During training, ZeroComp uses intrinsic images based on geometry, albedo, and masked shading, all without the need for paired images of scenes with and without composite objects. Once trained, it seamlessly integrates virtual 3D objects into scenes, adjusting shading to create realistic composites. We developed a high-quality evaluation dataset and demonstrate that ZeroComp outperforms methods using explicit lighting estimations and generative techniques in quantitative and human perception benchmarks. Additionally, ZeroComp extends to real and outdoor image compositing, even when trained solely on synthetic indoor data, showcasing its effectiveness in image compositing.
PanDORA: Casual HDR Radiance Acquisition for Indoor Scenes
Jul 08, 2024



Most novel view synthesis methods such as NeRF are unable to capture the true high dynamic range (HDR) radiance of scenes since they are typically trained on photos captured with standard low dynamic range (LDR) cameras. While the traditional exposure bracketing approach which captures several images at different exposures has recently been adapted to the multi-view case, we find such methods to fall short of capturing the full dynamic range of indoor scenes, which includes very bright light sources. In this paper, we present PanDORA: a PANoramic Dual-Observer Radiance Acquisition system for the casual capture of indoor scenes in high dynamic range. Our proposed system comprises two 360{\deg} cameras rigidly attached to a portable tripod. The cameras simultaneously acquire two 360{\deg} videos: one at a regular exposure and the other at a very fast exposure, allowing a user to simply wave the apparatus casually around the scene in a matter of minutes. The resulting images are fed to a NeRF-based algorithm that reconstructs the scene's full high dynamic range. Compared to HDR baselines from previous work, our approach reconstructs the full HDR radiance of indoor scenes without sacrificing the visual quality while retaining the ease of capture from recent NeRF-like approaches.