 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLogging Policy Design for Off-Policy Evaluation
May 14, 2026Off-policy evaluation (OPE) estimates the value of a target treatment policy (e.g., a recommender system) using data collected by a different logging policy. It enables high-stakes experimentation without live deployment, yet in practice accuracy depends heavily on the logging policy used to collect data for computing the estimate. We study how to design logging policies that minimize OPE error for given target policies. We characterize a fundamental reward-coverage tradeoff: concentrating probability mass on high-reward actions reduces variance but risks missing signal on actions the target policy may take. We propose a unifying framework for logging policy design and derive optimal policies in canonical informational regimes where the target policy and reward distribution are (i) known, (ii) unknown, and (iii) partially known through priors or noisy estimates at logging time. Our results provide actionable guidance for firms choosing among multiple candidate recommendation systems. We demonstrate the importance of treatment selection when gathering data for OPE, and describe theoretically optimal approaches when this is a firm's primary objective. We also distill practical design principles for selecting logging policies when operational constraints prevent implementing the theoretical optimum.
Prompt-Counterfactual Explanations for Generative AI System Behavior
Jan 06, 2026As generative AI systems become integrated into real-world applications, organizations increasingly need to be able to understand and interpret their behavior. In particular, decision-makers need to understand what causes generative AI systems to exhibit specific output characteristics. Within this general topic, this paper examines a key question: what is it about the input -- the prompt -- that causes an LLM-based generative AI system to produce output that exhibits specific characteristics, such as toxicity, negative sentiment, or political bias. To examine this question, we adapt a common technique from the Explainable AI literature: counterfactual explanations. We explain why traditional counterfactual explanations cannot be applied directly to generative AI systems, due to several differences in how generative AI systems function. We then propose a flexible framework that adapts counterfactual explanations to non-deterministic, generative AI systems in scenarios where downstream classifiers can reveal key characteristics of their outputs. Based on this framework, we introduce an algorithm for generating prompt-counterfactual explanations (PCEs). Finally, we demonstrate the production of counterfactual explanations for generative AI systems with three case studies, examining different output characteristics (viz., political leaning, toxicity, and sentiment). The case studies further show that PCEs can streamline prompt engineering to suppress undesirable output characteristics and can enhance red-teaming efforts to uncover additional prompts that elicit undesirable outputs. Ultimately, this work lays a foundation for prompt-focused interpretability in generative AI: a capability that will become indispensable as these models are entrusted with higher-stakes tasks and subject to emerging regulatory requirements for transparency and accountability.
Beware of "Explanations" of AI
Apr 09, 2025Understanding the decisions made and actions taken by increasingly complex AI system remains a key challenge. This has led to an expanding field of research in explainable artificial intelligence (XAI), highlighting the potential of explanations to enhance trust, support adoption, and meet regulatory standards. However, the question of what constitutes a "good" explanation is dependent on the goals, stakeholders, and context. At a high level, psychological insights such as the concept of mental model alignment can offer guidance, but success in practice is challenging due to social and technical factors. As a result of this ill-defined nature of the problem, explanations can be of poor quality (e.g. unfaithful, irrelevant, or incoherent), potentially leading to substantial risks. Instead of fostering trust and safety, poorly designed explanations can actually cause harm, including wrong decisions, privacy violations, manipulation, and even reduced AI adoption. Therefore, we caution stakeholders to beware of explanations of AI: while they can be vital, they are not automatically a remedy for transparency or responsible AI adoption, and their misuse or limitations can exacerbate harm. Attention to these caveats can help guide future research to improve the quality and impact of AI explanations.
Naive Algorithmic Collusion: When Do Bandit Learners Cooperate and When Do They Compete?
Nov 25, 2024Algorithmic agents are used in a variety of competitive decision settings, notably in making pricing decisions in contexts that range from online retail to residential home rentals. Business managers, algorithm designers, legal scholars, and regulators alike are all starting to consider the ramifications of "algorithmic collusion." We study the emergent behavior of multi-armed bandit machine learning algorithms used in situations where agents are competing, but they have no information about the strategic interaction they are engaged in. Using a general-form repeated Prisoner's Dilemma game, agents engage in online learning with no prior model of game structure and no knowledge of competitors' states or actions (e.g., no observation of competing prices). We show that these context-free bandits, with no knowledge of opponents' choices or outcomes, still will consistently learn collusive behavior - what we call "naive collusion." We primarily study this system through an analytical model and examine perturbations to the model through simulations. Our findings have several notable implications for regulators. First, calls to limit algorithms from conditioning on competitors' prices are insufficient to prevent algorithmic collusion. This is a direct result of collusion arising even in the naive setting. Second, symmetry in algorithms can increase collusion potential. This highlights a new, simple mechanism for "hub-and-spoke" algorithmic collusion. A central distributor need not imbue its algorithm with supra-competitive tendencies for apparent collusion to arise; it can simply arise by using certain (common) machine learning algorithms. Finally, we highlight that collusive outcomes depend starkly on the specific algorithm being used, and we highlight market and algorithmic conditions under which it will be unknown a priori whether collusion occurs.
Causal Fine-Tuning and Effect Calibration of Non-Causal Predictive Models
Jun 13, 2024



This paper proposes techniques to enhance the performance of non-causal models for causal inference using data from randomized experiments. In domains like advertising, customer retention, and precision medicine, non-causal models that predict outcomes under no intervention are often used to score individuals and rank them according to the expected effectiveness of an intervention (e.g, an ad, a retention incentive, a nudge). However, these scores may not perfectly correspond to intervention effects due to the inherent non-causal nature of the models. To address this limitation, we propose causal fine-tuning and effect calibration, two techniques that leverage experimental data to refine the output of non-causal models for different causal tasks, including effect estimation, effect ordering, and effect classification. They are underpinned by two key advantages. First, they can effectively integrate the predictive capabilities of general non-causal models with the requirements of a causal task in a specific context, allowing decision makers to support diverse causal applications with a "foundational" scoring model. Second, through simulations and an empirical example, we demonstrate that they can outperform the alternative of building a causal-effect model from scratch, particularly when the available experimental data is limited and the non-causal scores already capture substantial information about the relative sizes of causal effects. Overall, this research underscores the practical advantages of combining experimental data with non-causal models to support causal applications.
Causal Decision Making and Causal Effect Estimation Are Not the Same... and Why It Matters
Apr 08, 2021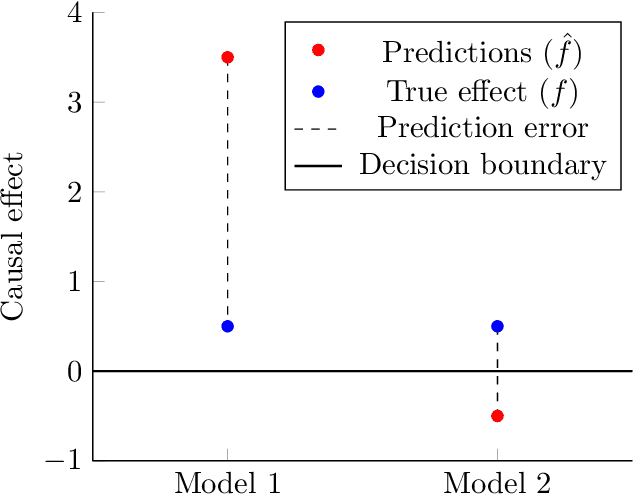
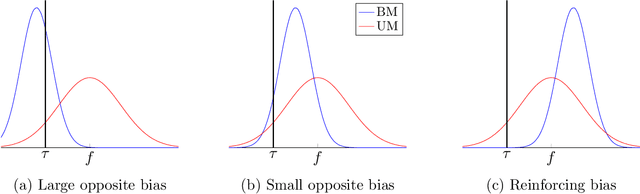
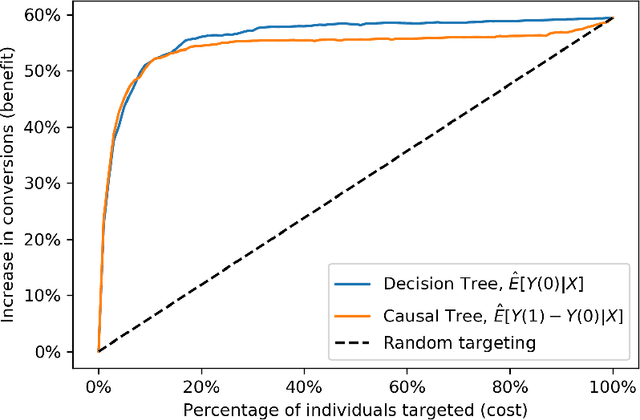
Causal decision making (CDM) at scale has become a routine part of business, and increasingly CDM is based on machine learning algorithms. For example, businesses often target offers, incentives, and recommendations with the goal of affecting consumer behavior. Recently, we have seen an acceleration of research related to CDM and to causal effect estimation (CEE) using machine learned models. This article highlights an important perspective: CDM is not the same as CEE, and counterintuitively, accurate CEE is not necessary for accurate CDM. Our experience is that this is not well understood by practitioners nor by most researchers. Technically, the estimand of interest is different, and this has important implications both for modeling and for the use of statistical models for CDM. We draw on recent research to highlight three of these implications. (1) We should carefully consider the objective function of the causal machine learning, and if possible, we should optimize for accurate "treatment assignment" rather than for accurate effect-size estimation. (2) Confounding does not have the same effect on CDM as it does on CEE. The upshot here is that for supporting CDM it may be just as good to learn with confounded data as with unconfounded data. Finally, (3) causal statistical modeling may not be necessary at all to support CDM, because there may be (and perhaps often is) a proxy target for statistical modeling that can do as well or better. This observation helps to explain at least one broad common CDM practice that seems "wrong" at first blush: the widespread use of non-causal models for targeting interventions. Our perspective is that these observations open up substantial fertile ground for future research. Whether or not you share our perspective completely, we hope we facilitate future research in this area by pointing to related articles from multiple contributing fields.
Methods for Individual Treatment Assignment: An Application and Comparison for Playlist Generation
May 09, 2020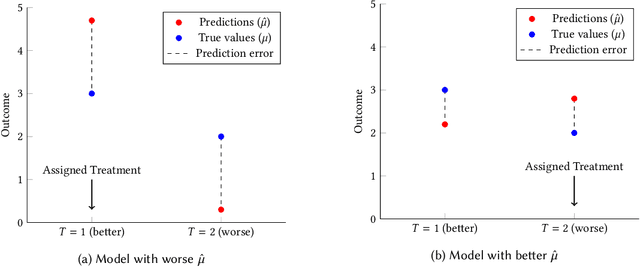
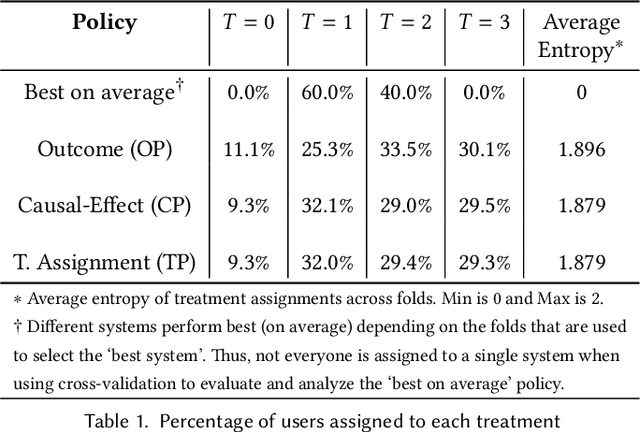
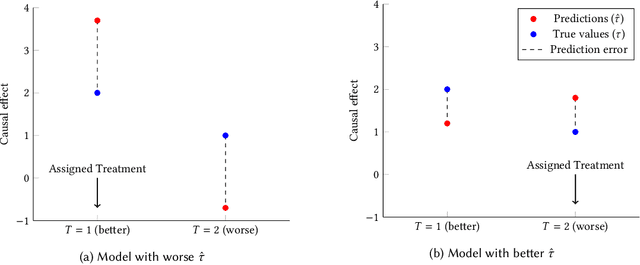
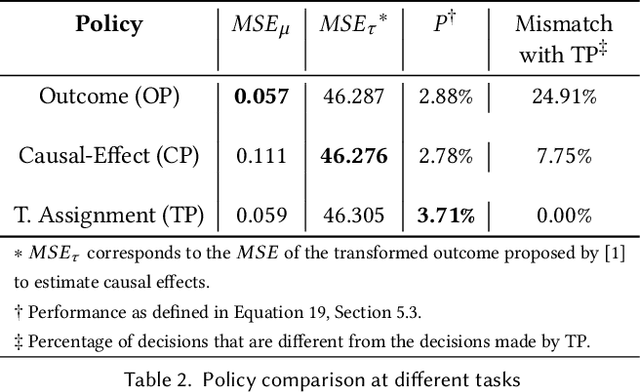
We present a systematic analysis of causal treatment assignment decision making, a general problem that arises in many applications and has received significant attention from economists, computer scientists, and social scientists. We focus on choosing, for each user, the best algorithm for playlist generation in order to optimize engagement. We characterize the various methods proposed in the literature into three general approaches: learning models to predict outcomes, learning models to predict causal effects, and learning models to predict optimal treatment assignments. We show analytically that optimizing for outcome or causal-effect prediction is not the same as optimizing for treatment assignments, and thus we should prefer learning models that optimize for treatment assignments. For our playlist generation application, we compare and contrast the three approaches empirically. This is the first comparison of the different treatment assignment approaches on a real-world application at scale (based on more than half a billion individual treatment assignments). Our results show (i) that applying different algorithms to different users can improve streams substantially compared to deploying the same algorithm for everyone, (ii) that personalized assignments improve substantially with larger data sets, and (iii) that learning models by optimizing treatment assignments rather than outcome or causal-effect predictions can improve treatment assignment performance by more than 28%.
Explaining Data-Driven Decisions made by AI Systems: The Counterfactual Approach
Feb 05, 2020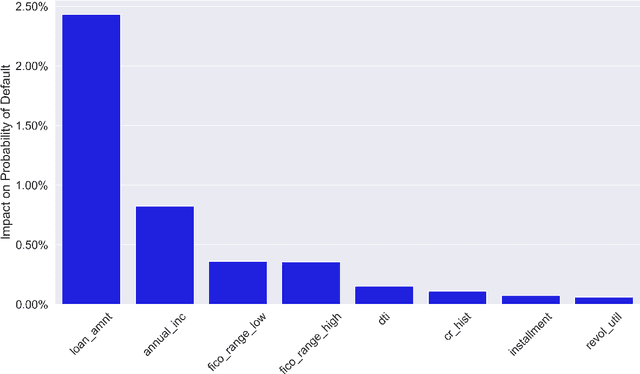

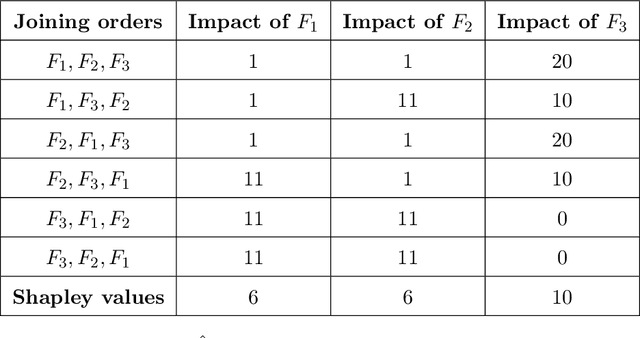
Lack of understanding of the decisions made by model-based AI systems is an important barrier for their adoption. We examine counterfactual explanations as an alternative for explaining AI decisions. The counterfactual approach defines an explanation as a set of the system's data inputs that causally drives the decision (meaning that removing them changes the decision) and is irreducible (meaning that removing any subset of the inputs in the explanation does not change the decision). We generalize previous work on counterfactual explanations, resulting in a framework that (a) is model-agnostic, (b) can address features with arbitrary data types, (c) can explain decisions made by complex AI systems that incorporate multiple models, and (d) is scalable to large numbers of features. We also propose a heuristic procedure to find the most useful explanations depending on the context. We contrast counterfactual explanations with another alternative: methods that explain model predictions by weighting features according to their importance (e.g., SHAP, LIME). This paper presents two fundamental reasons why explaining model predictions is not the same as explaining the decisions made using those predictions, suggesting we should carefully consider whether importance-weight explanations are well-suited to explain decisions made by AI systems. Specifically, we show that (1) features that have a large importance weight for a model prediction may not actually affect the corresponding decision, and (2) importance weights are insufficient to communicate whether and how features influence system decisions. We demonstrate this with several examples, including three detailed case studies that compare the counterfactual approach with SHAP to illustrate various conditions under which counterfactual explanations explain data-driven decisions better than feature importance weights.
Counterfactual Explanation Algorithms for Behavioral and Textual Data
Dec 04, 2019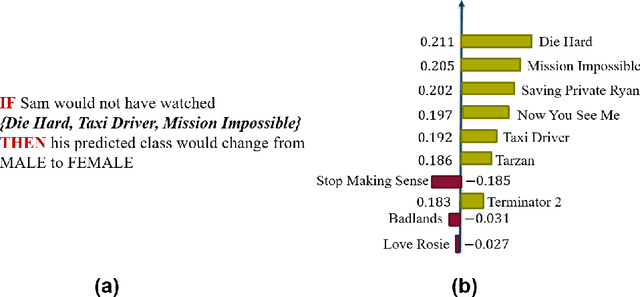
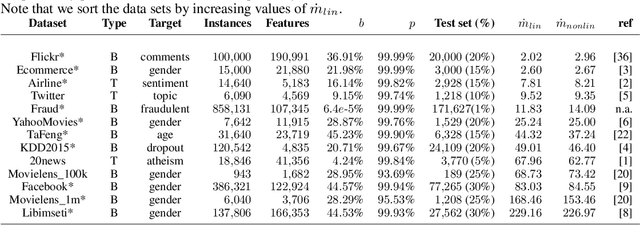
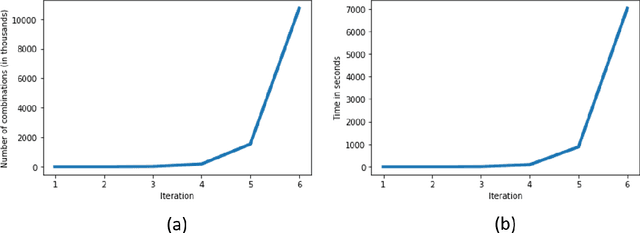
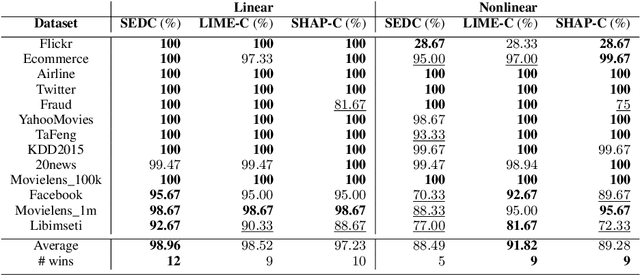
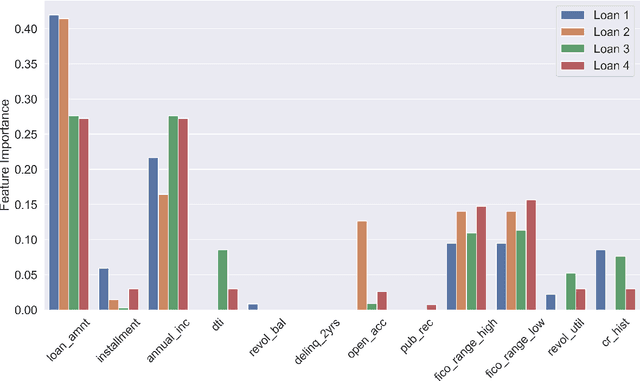
We study the interpretability of predictive systems that use high-dimensonal behavioral and textual data. Examples include predicting product interest based on online browsing data and detecting spam emails or objectionable web content. Recently, counterfactual explanations have been proposed for generating insight into model predictions, which focus on what is relevant to a particular instance. Conducting a complete search to compute counterfactuals is very time-consuming because of the huge dimensionality. To our knowledge, for behavioral and text data, only one model-agnostic heuristic algorithm (SEDC) for finding counterfactual explanations has been proposed in the literature. However, there may be better algorithms for finding counterfactuals quickly. This study aligns the recently proposed Linear Interpretable Model-agnostic Explainer (LIME) and Shapley Additive Explanations (SHAP) with the notion of counterfactual explanations, and empirically benchmarks their effectiveness and efficiency against SEDC using a collection of 13 data sets. Results show that LIME-Counterfactual (LIME-C) and SHAP-Counterfactual (SHAP-C) have low and stable computation times, but mostly, they are less efficient than SEDC. However, for certain instances on certain data sets, SEDC's run time is comparably large. With regard to effectiveness, LIME-C and SHAP-C find reasonable, if not always optimal, counterfactual explanations. SHAP-C, however, seems to have difficulties with highly unbalanced data. Because of its good overall performance, LIME-C seems to be a favorable alternative to SEDC, which failed for some nonlinear models to find counterfactuals because of the particular heuristic search algorithm it uses. A main upshot of this paper is that there is a good deal of room for further research. For example, we propose algorithmic adjustments that are direct upshots of the paper's findings.
Explaining Classification Models Built on High-Dimensional Sparse Data
Jul 26, 2016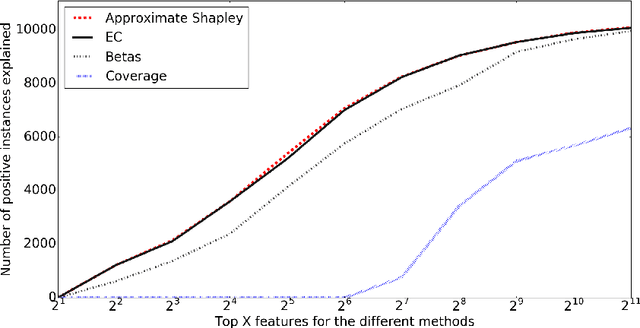

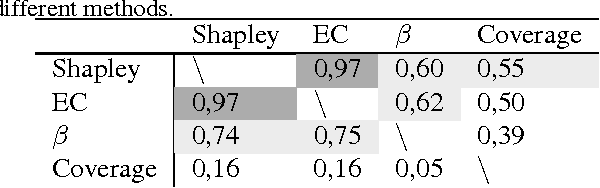
Predictive modeling applications increasingly use data representing people's behavior, opinions, and interactions. Fine-grained behavior data often has different structure from traditional data, being very high-dimensional and sparse. Models built from these data are quite difficult to interpret, since they contain many thousands or even many millions of features. Listing features with large model coefficients is not sufficient, because the model coefficients do not incorporate information on feature presence, which is key when analysing sparse data. In this paper we introduce two alternatives for explaining predictive models by listing important features. We evaluate these alternatives in terms of explanation "bang for the buck,", i.e., how many examples' inferences are explained for a given number of features listed. The bottom line: (i) The proposed alternatives have double the bang-for-the-buck as compared to just listing the high-coefficient features, and (ii) interestingly, although they come from different sources and motivations, the two new alternatives provide strikingly similar rankings of important features.