 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdapting LLMs for Minimal-edit Grammatical Error Correction
Jun 16, 2025Decoder-only large language models have shown superior performance in the fluency-edit English Grammatical Error Correction, but their adaptation for minimal-edit English GEC is still underexplored. To improve their effectiveness in the minimal-edit approach, we explore the error rate adaptation topic and propose a novel training schedule method. Our experiments set a new state-of-the-art result for a single-model system on the BEA-test set. We also detokenize the most common English GEC datasets to match the natural way of writing text. During the process, we find that there are errors in them. Our experiments analyze whether training on detokenized datasets impacts the results and measure the impact of the usage of the datasets with corrected erroneous examples. To facilitate reproducibility, we have released the source code used to train our models.
LLMzSzŁ: a comprehensive LLM benchmark for Polish
Jan 04, 2025This article introduces the first comprehensive benchmark for the Polish language at this scale: LLMzSz{\L} (LLMs Behind the School Desk). It is based on a coherent collection of Polish national exams, including both academic and professional tests extracted from the archives of the Polish Central Examination Board. It covers 4 types of exams, coming from 154 domains. Altogether, it consists of almost 19k closed-ended questions. We investigate the performance of open-source multilingual, English, and Polish LLMs to verify LLMs' abilities to transfer knowledge between languages. Also, the correlation between LLMs and humans at model accuracy and exam pass rate levels is examined. We show that multilingual LLMs can obtain superior results over monolingual ones; however, monolingual models may be beneficial when model size matters. Our analysis highlights the potential of LLMs in assisting with exam validation, particularly in identifying anomalies or errors in examination tasks.
CORD: Balancing COnsistency and Rank Distillation for Robust Retrieval-Augmented Generation
Dec 19, 2024



With the adoption of retrieval-augmented generation (RAG), large language models (LLMs) are expected to ground their generation to the retrieved contexts. Yet, this is hindered by position bias of LLMs, failing to evenly attend to all contexts. Previous work has addressed this by synthesizing contexts with perturbed positions of gold segment, creating a position-diversified train set. We extend this intuition to propose consistency regularization with augmentation and distillation. First, we augment each training instance with its position perturbation to encourage consistent predictions, regardless of ordering. We also distill behaviors of this pair, although it can be counterproductive in certain RAG scenarios where the given order from the retriever is crucial for generation quality. We thus propose CORD, balancing COnsistency and Rank Distillation. CORD adaptively samples noise-controlled perturbations from an interpolation space, ensuring both consistency and respect for the rank prior. Empirical results show this balance enables CORD to outperform consistently in diverse RAG benchmarks.
Inference Scaling for Bridging Retrieval and Augmented Generation
Dec 14, 2024Retrieval-augmented generation (RAG) has emerged as a popular approach to steering the output of a large language model (LLM) by incorporating retrieved contexts as inputs. However, existing work observed the generator bias, such that improving the retrieval results may negatively affect the outcome. In this work, we show such bias can be mitigated, from inference scaling, aggregating inference calls from the permuted order of retrieved contexts. The proposed Mixture-of-Intervention (MOI) explicitly models the debiased utility of each passage with multiple forward passes to construct a new ranking. We also show that MOI can leverage the retriever's prior knowledge to reduce the computational cost by minimizing the number of permutations considered and lowering the cost per LLM call. We showcase the effectiveness of MOI on diverse RAG tasks, improving ROUGE-L on MS MARCO and EM on HotpotQA benchmarks by ~7 points.
Tackling prediction tasks in relational databases with LLMs
Nov 18, 2024



Though large language models (LLMs) have demonstrated exceptional performance across numerous problems, their application to predictive tasks in relational databases remains largely unexplored. In this work, we address the notion that LLMs cannot yield satisfactory results on relational databases due to their interconnected tables, complex relationships, and heterogeneous data types. Using the recently introduced RelBench benchmark, we demonstrate that even a straightforward application of LLMs achieves competitive performance on these tasks. These findings establish LLMs as a promising new baseline for ML on relational databases and encourage further research in this direction.
Oddballness: universal anomaly detection with language models
Sep 04, 2024We present a new method to detect anomalies in texts (in general: in sequences of any data), using language models, in a totally unsupervised manner. The method considers probabilities (likelihoods) generated by a language model, but instead of focusing on low-likelihood tokens, it considers a new metric introduced in this paper: oddballness. Oddballness measures how ``strange'' a given token is according to the language model. We demonstrate in grammatical error detection tasks (a specific case of text anomaly detection) that oddballness is better than just considering low-likelihood events, if a totally unsupervised setup is assumed.
POLygraph: Polish Fake News Dataset
Jul 01, 2024This paper presents the POLygraph dataset, a unique resource for fake news detection in Polish. The dataset, created by an interdisciplinary team, is composed of two parts: the "fake-or-not" dataset with 11,360 pairs of news articles (identified by their URLs) and corresponding labels, and the "fake-they-say" dataset with 5,082 news articles (identified by their URLs) and tweets commenting on them. Unlike existing datasets, POLygraph encompasses a variety of approaches from source literature, providing a comprehensive resource for fake news detection. The data was collected through manual annotation by expert and non-expert annotators. The project also developed a software tool that uses advanced machine learning techniques to analyze the data and determine content authenticity. The tool and dataset are expected to benefit various entities, from public sector institutions to publishers and fact-checking organizations. Further dataset exploration will foster fake news detection and potentially stimulate the implementation of similar models in other languages. The paper focuses on the creation and composition of the dataset, so it does not include a detailed evaluation of the software tool for content authenticity analysis, which is planned at a later stage of the project.
Two Approaches to Diachronic Normalization of Polish Texts
Feb 02, 2024This paper discusses two approaches to the diachronic normalization of Polish texts: a rule-based solution that relies on a set of handcrafted patterns, and a neural normalization model based on the text-to-text transfer transformer architecture. The training and evaluation data prepared for the task are discussed in detail, along with experiments conducted to compare the proposed normalization solutions. A quantitative and qualitative analysis is made. It is shown that at the current stage of inquiry into the problem, the rule-based solution outperforms the neural one on 3 out of 4 variants of the prepared dataset, although in practice both approaches have distinct advantages and disadvantages.
CCpdf: Building a High Quality Corpus for Visually Rich Documents from Web Crawl Data
Apr 28, 2023In recent years, the field of document understanding has progressed a lot. A significant part of this progress has been possible thanks to the use of language models pretrained on large amounts of documents. However, pretraining corpora used in the domain of document understanding are single domain, monolingual, or nonpublic. Our goal in this paper is to propose an efficient pipeline for creating a big-scale, diverse, multilingual corpus of PDF files from all over the Internet using Common Crawl, as PDF files are the most canonical types of documents as considered in document understanding. We analysed extensively all of the steps of the pipeline and proposed a solution which is a trade-off between data quality and processing time. We also share a CCpdf corpus in a form or an index of PDF files along with a script for downloading them, which produces a collection useful for language model pretraining. The dataset and tools published with this paper offer researchers the opportunity to develop even better multilingual language models.
Kleister: Key Information Extraction Datasets Involving Long Documents with Complex Layouts
May 12, 2021
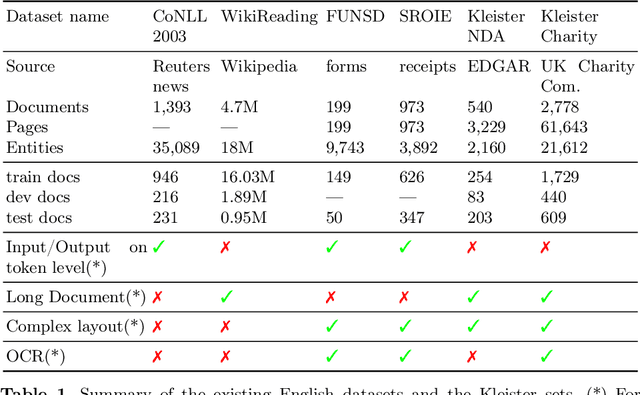
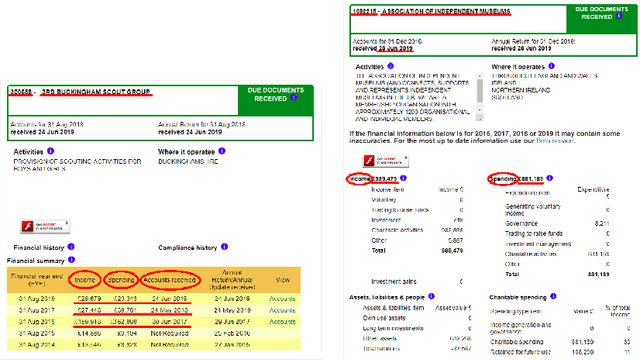
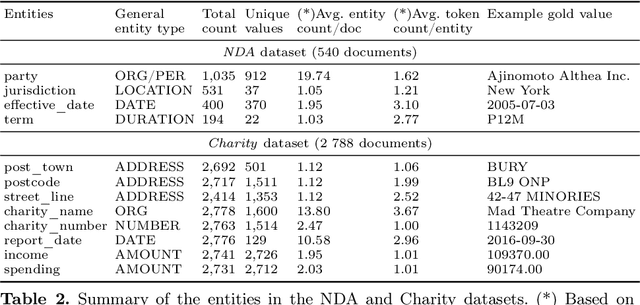
The relevance of the Key Information Extraction (KIE) task is increasingly important in natural language processing problems. But there are still only a few well-defined problems that serve as benchmarks for solutions in this area. To bridge this gap, we introduce two new datasets (Kleister NDA and Kleister Charity). They involve a mix of scanned and born-digital long formal English-language documents. In these datasets, an NLP system is expected to find or infer various types of entities by employing both textual and structural layout features. The Kleister Charity dataset consists of 2,788 annual financial reports of charity organizations, with 61,643 unique pages and 21,612 entities to extract. The Kleister NDA dataset has 540 Non-disclosure Agreements, with 3,229 unique pages and 2,160 entities to extract. We provide several state-of-the-art baseline systems from the KIE domain (Flair, BERT, RoBERTa, LayoutLM, LAMBERT), which show that our datasets pose a strong challenge to existing models. The best model achieved an 81.77% and an 83.57% F1-score on respectively the Kleister NDA and the Kleister Charity datasets. We share the datasets to encourage progress on more in-depth and complex information extraction tasks.