 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Affect Analysis: Predicting Emotions of Image Viewers with Vision-Language Models
Jan 27, 2026Vision-language models (VLMs) show promise as tools for inferring affect from visual stimuli at scale; it is not yet clear how closely their outputs align with human affective ratings. We benchmarked nine VLMs, ranging from state-of-the-art proprietary models to open-source models, on three psycho-metrically validated affective image datasets: the International Affective Picture System, the Nencki Affective Picture System, and the Library of AI-Generated Affective Images. The models performed two tasks in the zero-shot setting: (i) top-emotion classification (selecting the strongest discrete emotion elicited by an image) and (ii) continuous prediction of human ratings on 1-7/9 Likert scales for discrete emotion categories and affective dimensions. We also evaluated the impact of rater-conditioned prompting on the LAI-GAI dataset using de-identified participant metadata. The results show good performance in discrete emotion classification, with accuracies typically ranging from 60% to 80% on six-emotion labels and from 60% to 75% on a more challenging 12-category task. The predictions of anger and surprise had the lowest accuracy in all datasets. For continuous rating prediction, models showed moderate to strong alignment with humans (r > 0.75) but also exhibited consistent biases, notably weaker performance on arousal, and a tendency to overestimate response strength. Rater-conditioned prompting resulted in only small, inconsistent changes in predictions. Overall, VLMs capture broad affective trends but lack the nuance found in validated psychological ratings, highlighting their potential and current limitations for affective computing and mental health-related applications.
LLMzSzŁ: a comprehensive LLM benchmark for Polish
Jan 04, 2025This article introduces the first comprehensive benchmark for the Polish language at this scale: LLMzSz{\L} (LLMs Behind the School Desk). It is based on a coherent collection of Polish national exams, including both academic and professional tests extracted from the archives of the Polish Central Examination Board. It covers 4 types of exams, coming from 154 domains. Altogether, it consists of almost 19k closed-ended questions. We investigate the performance of open-source multilingual, English, and Polish LLMs to verify LLMs' abilities to transfer knowledge between languages. Also, the correlation between LLMs and humans at model accuracy and exam pass rate levels is examined. We show that multilingual LLMs can obtain superior results over monolingual ones; however, monolingual models may be beneficial when model size matters. Our analysis highlights the potential of LLMs in assisting with exam validation, particularly in identifying anomalies or errors in examination tasks.
Temporal Image Caption Retrieval Competition -- Description and Results
Oct 08, 2024



Multimodal models, which combine visual and textual information, have recently gained significant recognition. This paper addresses the multimodal challenge of Text-Image retrieval and introduces a novel task that extends the modalities to include temporal data. The Temporal Image Caption Retrieval Competition (TICRC) presented in this paper is based on the Chronicling America and Challenging America projects, which offer access to an extensive collection of digitized historic American newspapers spanning 274 years. In addition to the competition results, we provide an analysis of the delivered dataset and the process of its creation.
Two Approaches to Diachronic Normalization of Polish Texts
Feb 02, 2024This paper discusses two approaches to the diachronic normalization of Polish texts: a rule-based solution that relies on a set of handcrafted patterns, and a neural normalization model based on the text-to-text transfer transformer architecture. The training and evaluation data prepared for the task are discussed in detail, along with experiments conducted to compare the proposed normalization solutions. A quantitative and qualitative analysis is made. It is shown that at the current stage of inquiry into the problem, the rule-based solution outperforms the neural one on 3 out of 4 variants of the prepared dataset, although in practice both approaches have distinct advantages and disadvantages.
Detection of Criminal Texts for the Polish State Border Guard
Aug 24, 2021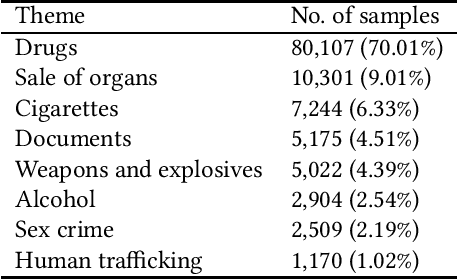
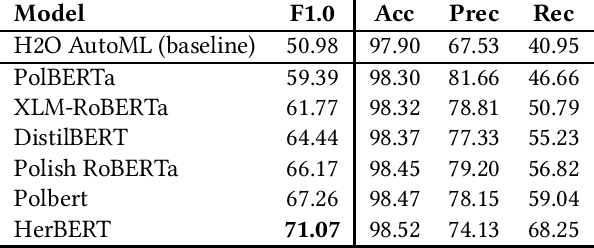
This paper describes research on the detection of Polish criminal texts appearing on the Internet. We carried out experiments to find the best available setup for the efficient classification of unbalanced and noisy data. The best performance was achieved when our model was fine-tuned on a pre-trained Polish-based transformer language model. For the detection task, a large corpus of annotated Internet snippets was collected as training data. We share this dataset and create a new task for the detection of criminal texts using the Gonito platform as the benchmark.