 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNode-Variant Graph Filters in Graph Neural Networks
May 31, 2021
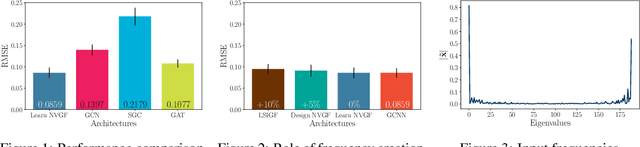
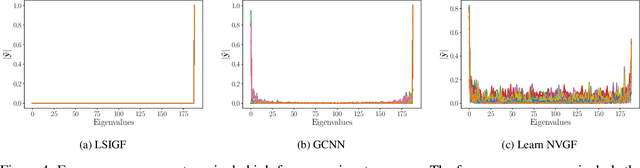
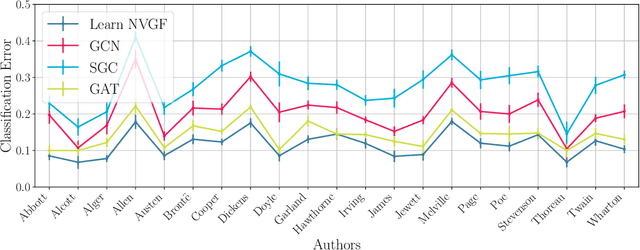
Graph neural networks (GNNs) have been successfully employed in a myriad of applications involving graph-structured data. Theoretical findings establish that GNNs use nonlinear activation functions to create low-eigenvalue frequency content that can be processed in a stable manner by subsequent graph convolutional filters. However, the exact shape of the frequency content created by nonlinear functions is not known, and thus, it cannot be learned nor controlled. In this work, node-variant graph filters (NVGFs) are shown to be capable of creating frequency content and are thus used in lieu of nonlinear activation functions. This results in a novel GNN architecture that, although linear, is capable of creating frequency content as well. Furthermore, this new frequency content can be either designed or learned from data. In this way, the role of frequency creation is separated from the nonlinear nature of traditional GNNs. Extensive simulations are carried out to differentiate the contributions of frequency creation from those of the nonlinearity.
Distributed Linear-Quadratic Control with Graph Neural Networks
Mar 16, 2021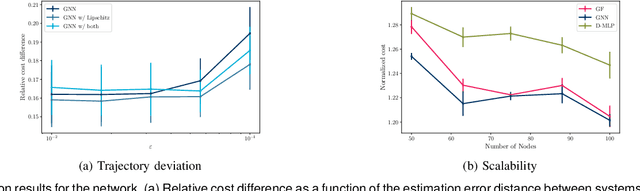
Controlling network systems has become a problem of paramount importance. Optimally controlling a network system with linear dynamics and minimizing a quadratic cost is a particular case of the well-studied linear-quadratic problem. When the specific topology of the network system is ignored, the optimal controller is readily available. However, this results in a centralized controller, facing limitations in terms of implementation and scalability. Finding the optimal distributed controller, on the other hand, is intractable in the general case. In this paper, we propose the use of graph neural networks (GNNs) to parametrize and design a distributed controller. GNNs exhibit many desirable properties, such as being naturally distributed and scalable. We cast the distributed linear-quadratic problem as a self-supervised learning problem, which is then used to train the GNN-based controllers. We also obtain sufficient conditions for the resulting closed-loop system to be input-state stable, and derive an upper bound on the trajectory deviation when the system is not accurately known. We run extensive simulations to study the performance of GNN-based distributed controllers and show that they are computationally efficient and scalable.
Decentralized Control with Graph Neural Networks
Dec 29, 2020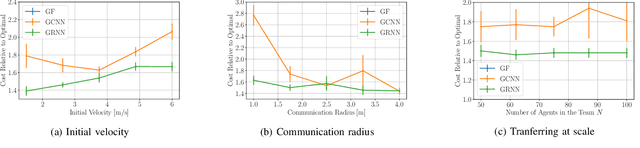
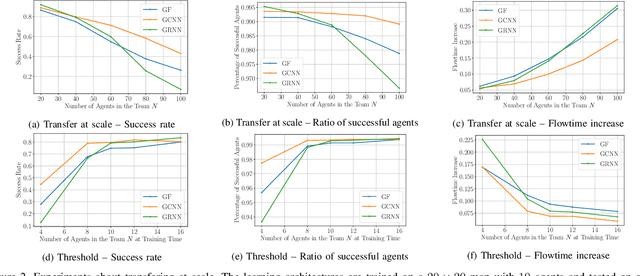
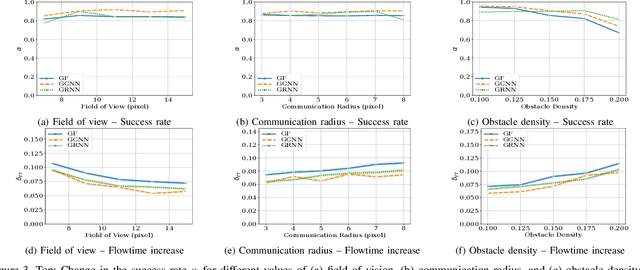

Dynamical systems consisting of a set of autonomous agents face the challenge of having to accomplish a global task, relying only on local information. While centralized controllers are readily available, they face limitations in terms of scalability and implementation, as they do not respect the distributed information structure imposed by the network system of agents. Given the difficulties in finding optimal decentralized controllers, we propose a novel framework using graph neural networks (GNNs) to learn these controllers. GNNs are well-suited for the task since they are naturally distributed architectures and exhibit good scalability and transferability properties. The problems of flocking and multi-agent path planning are explored to illustrate the potential of GNNs in learning decentralized controllers.
Nonlinear State-Space Generalizations of Graph Convolutional Neural Networks
Oct 27, 2020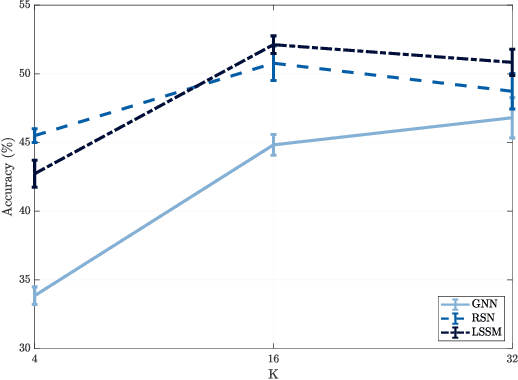
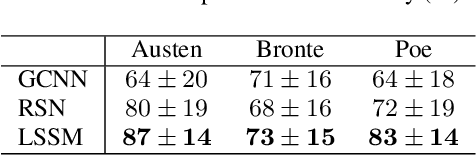
Graph convolutional neural networks (GCNNs) learn compositional representations from network data by nesting linear graph convolutions into nonlinearities. In this work, we approach GCNNs from a state-space perspective revealing that the graph convolutional module is a minimalistic linear state-space model, in which the state update matrix is the graph shift operator. We show this state update may be problematic because it is nonparametric, and depending on the graph spectrum it may explode or vanish. Therefore, the GCNN has to trade its degrees of freedom between extracting features from data and handling these instabilities. To improve such trade-off, we propose a novel family of nodal aggregation rules that aggregates node features within a layer in a nonlinear state-space parametric fashion and allowing for a better trade-off. We develop two architectures within this family inspired by the recursive ideas with and without nodal gating mechanisms. The proposed solutions generalize the GCNN and provide an additional handle to control the state update and learn from the data. Numerical results on source localization and authorship attribution show the superiority of the nonlinear state-space generalization models over the baseline GCNN.
Discriminability of Single-Layer Graph Neural Networks
Oct 21, 2020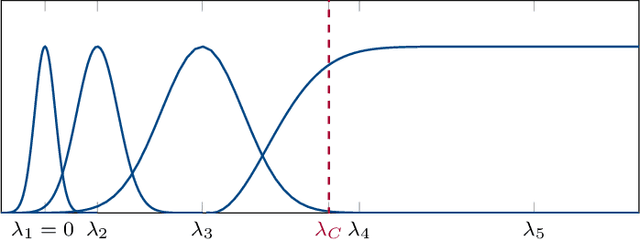
Network data can be conveniently modeled as a graph signal, where data values are assigned to the nodes of a graph describing the underlying network topology. Successful learning from network data requires methods that effectively exploit this graph structure. Graph neural networks (GNNs) provide one such method and have exhibited promising performance on a wide range of problems. Understanding why GNNs work is of paramount importance, particularly in applications involving physical networks. We focus on the property of discriminability and establish conditions under which the inclusion of pointwise nonlinearities to a stable graph filter bank leads to an increased discriminative capacity for high-eigenvalue content. We define a notion of discriminability tied to the stability of the architecture, show that GNNs are at least as discriminative as linear graph filter banks, and characterize the signals that cannot be discriminated by either.
Spherical Convolutional Neural Networks: Stability to Perturbations in SO(3)
Oct 12, 2020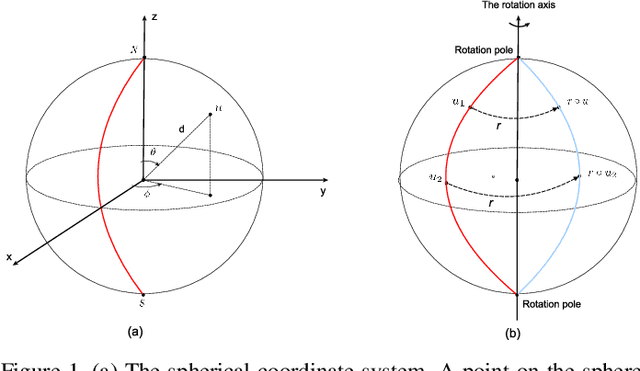
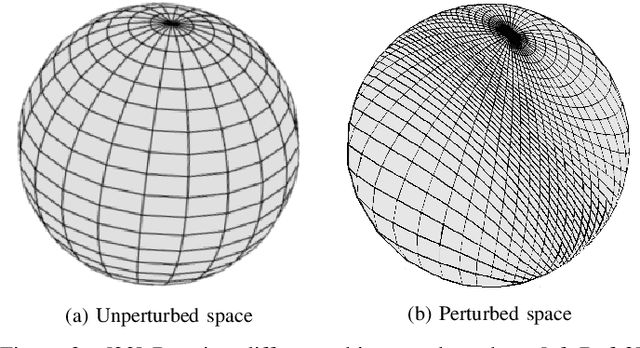
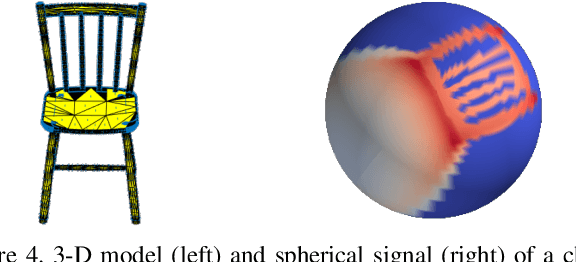
Spherical signals are useful mathematical models for data arising in many 3-D applications such as LIDAR images, panorama cameras, and optical scanners. Successful processing of spherical signals entails architectures capable of exploiting their inherent data structure. In particular, spherical convolutional neural networks (Spherical CNNs) have shown promising performance in shape analysis and object recognition. In this paper, we focus on analyzing the properties that Spherical CNNs exhibit as they pertain to the rotational structure present in spherical signals. More specifically, we prove that they are equivariant to rotations and stable to rotation diffeomorphisms. These two properties illustrate how Spherical CNNs exploit the rotational structure of spherical signals, thus offering good generalization and faster learning. We corroborate these properties through controlled numerical experiments.
Graph Neural Networks: Architectures, Stability and Transferability
Aug 04, 2020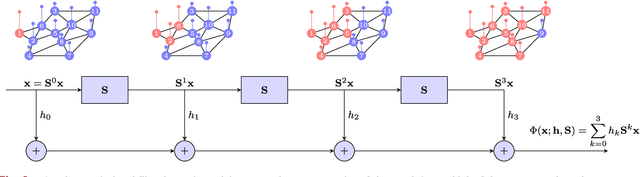

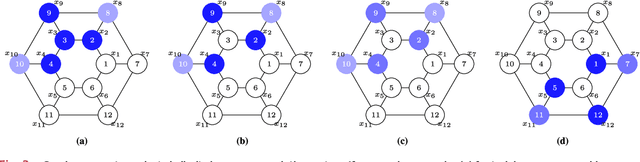

Graph Neural Networks (GNNs) are information processing architectures for signals supported on graphs. They are presented here as generalizations of convolutional neural networks (CNNs) in which individual layers contain banks of graph convolutional filters instead of banks of classical convolutional filters. Otherwise, GNNs operate as CNNs. Filters are composed with pointwise nonlinearities and stacked in layers. It is shown that GNN architectures exhibit equivariance to permutation and stability to graph deformations. These properties provide a measure of explanation respecting the good performance of GNNs that can be observed empirically. It is also shown that if graphs converge to a limit object, a graphon, GNNs converge to a corresponding limit object, a graphon neural network. This convergence justifies the transferability of GNNs across networks with different number of nodes.
Wide and Deep Graph Neural Networks with Distributed Online Learning
Jun 11, 2020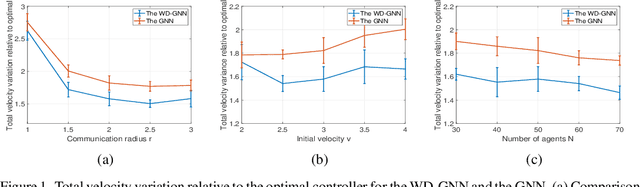
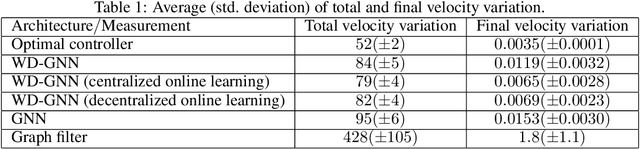
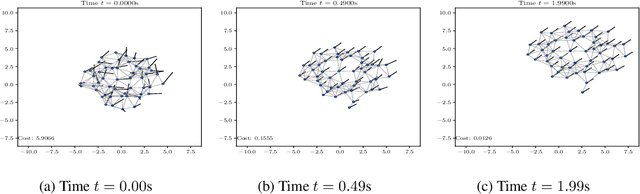
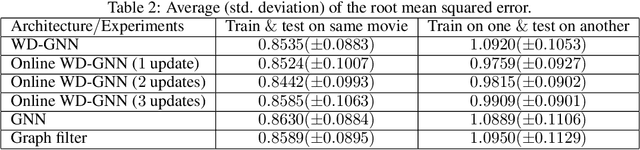
Graph neural networks (GNNs) learn representations from network data with naturally distributed architectures. This renders them well-suited candidates for decentralized learning since the operations respect the structure imposed by the underlying graph. Oftentimes, this graph support changes with time, whether it is due to link failures or topology changes caused by mobile components. Modifications to the underlying structure create a mismatch between the graphs on which GNNs were trained and the ones on which they are tested. Online learning can be used to retrain the GNNs at test time, overcoming this issue. However, most online learning algorithms are centralized and work on convex objective functions (which GNNs rarely lead to). This paper puts forth the Wide and Deep GNN (WD-GNN), a novel architecture that can be easily updated with distributed online learning mechanisms. The WD-GNN consists of two components: the wide part is a bank of linear graph filters and the deep part is a convolutional GNN. At training time, the joint architecture learns a relevant nonlinear representation from data. At test time, the deep part is left unchanged, while the wide part is retrained online. Since the wide part is linear, the problem becomes convex, and online optimization algorithms can be used. We also propose a distributed online optimization algorithm that updates the wide part at test time, without violating its decentralized nature. We also analyze the stability of the WD-GNN to changes in the underlying topology and derive convergence guarantees for the online retraining procedure. These results indicate the transferability, scalability, and efficiency of the WD-GNN to adapt online to new testing scenarios in a distributed manner. Experiments on the control of robot swarms corroborate the theory and show the potential of the proposed architecture for distributed online learning.
Graph Neural Networks for Decentralized Controllers
Mar 23, 2020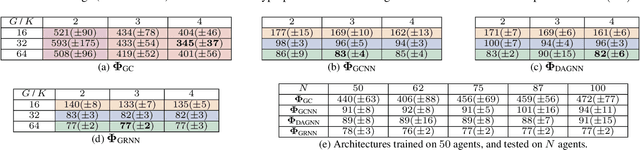
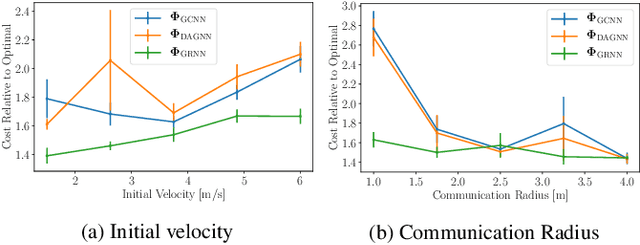
Dynamical systems comprised of autonomous agents arise in many relevant problems such as multi-agent robotics, smart grids, or smart cities. Controlling these systems is of paramount importance to guarantee a successful deployment. Optimal centralized controllers are readily available but face limitations in terms of scalability and practical implementation. Optimal decentralized controllers, on the other hand, are difficult to find. In this paper, we use graph neural networks (GNNs) to learn decentralized controllers from data. GNNs are well-suited for the task since they are naturally distributed architectures. Furthermore, they are equivariant and stable, leading to good scalability and transferability properties. The problem of flocking is explored to illustrate the power of GNNs in learning decentralized controllers.
Graphs, Convolutions, and Neural Networks
Mar 08, 2020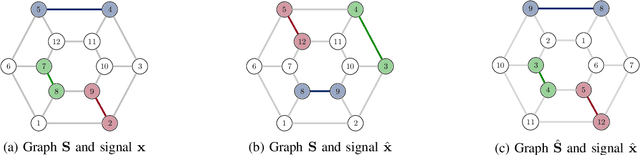
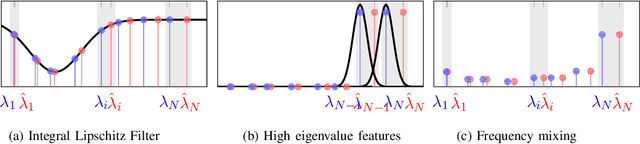
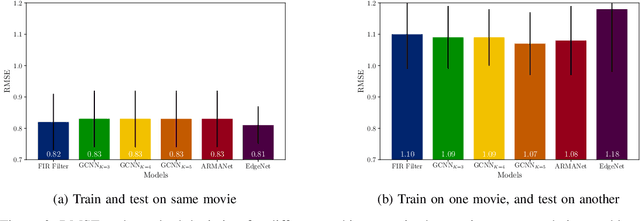

Network data can be conveniently modeled as a graph signal, where data values are assigned to nodes of a graph that describes the underlying network topology. Successful learning from network data is built upon methods that effectively exploit this graph structure. In this work, we overview graph convolutional filters, which are linear, local and distributed operations that adequately leverage the graph structure. We then discuss graph neural networks (GNNs), built upon graph convolutional filters, that have been shown to be powerful nonlinear learning architectures. We show that GNNs are permutation equivariant and stable to changes in the underlying graph topology, allowing them to scale and transfer. We also introduce GNN extensions using edge-varying and autoregressive moving average graph filters and discuss their properties. Finally, we study the use of GNNs in learning decentralized controllers for robot swarm and in addressing the recommender system problem.