 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPATIALALIGN: Aligning Dynamic Spatial Relationships in Video Generation
Feb 26, 2026Most text-to-video (T2V) generators prioritize aesthetic quality, but often ignoring the spatial constraints in the generated videos. In this work, we present SPATIALALIGN, a self-improvement framework that enhances T2V models capabilities to depict Dynamic Spatial Relationships (DSR) specified in text prompts. We present a zeroth-order regularized Direct Preference Optimization (DPO) to fine-tune T2V models towards better alignment with DSR. Specifically, we design DSR-SCORE, a geometry-based metric that quantitatively measures the alignment between generated videos and the specified DSRs in prompts, which is a step forward from prior works that rely on VLM for evaluation. We also conduct a dataset of text-video pairs with diverse DSRs to facilitate the study. Extensive experiments demonstrate that our fine-tuned model significantly out performs the baseline in spatial relationships. The code will be released in Link.
Dynamic Sparse R-CNN
May 04, 2022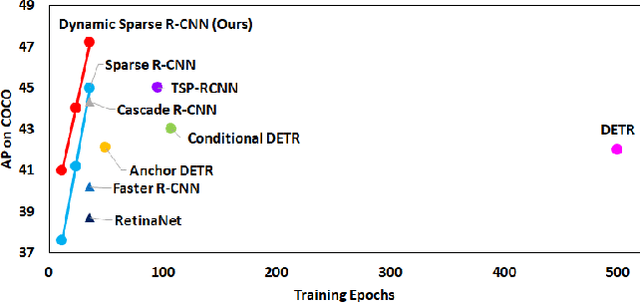
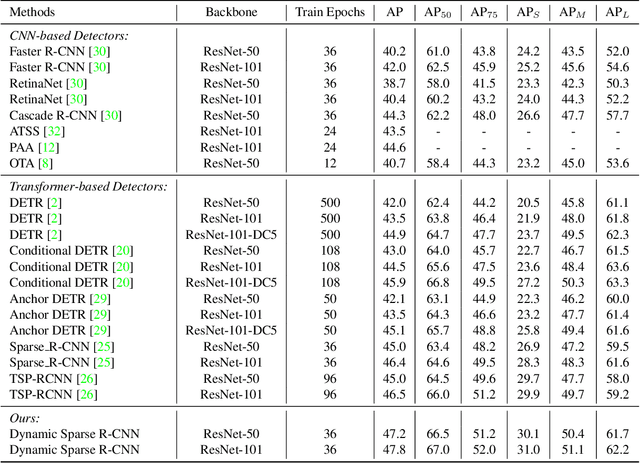
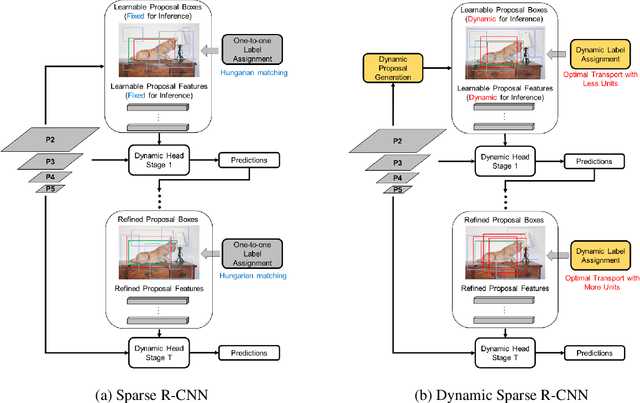

Sparse R-CNN is a recent strong object detection baseline by set prediction on sparse, learnable proposal boxes and proposal features. In this work, we propose to improve Sparse R-CNN with two dynamic designs. First, Sparse R-CNN adopts a one-to-one label assignment scheme, where the Hungarian algorithm is applied to match only one positive sample for each ground truth. Such one-to-one assignment may not be optimal for the matching between the learned proposal boxes and ground truths. To address this problem, we propose dynamic label assignment (DLA) based on the optimal transport algorithm to assign increasing positive samples in the iterative training stages of Sparse R-CNN. We constrain the matching to be gradually looser in the sequential stages as the later stage produces the refined proposals with improved precision. Second, the learned proposal boxes and features remain fixed for different images in the inference process of Sparse R-CNN. Motivated by dynamic convolution, we propose dynamic proposal generation (DPG) to assemble multiple proposal experts dynamically for providing better initial proposal boxes and features for the consecutive training stages. DPG thereby can derive sample-dependent proposal boxes and features for inference. Experiments demonstrate that our method, named Dynamic Sparse R-CNN, can boost the strong Sparse R-CNN baseline with different backbones for object detection. Particularly, Dynamic Sparse R-CNN reaches the state-of-the-art 47.2% AP on the COCO 2017 validation set, surpassing Sparse R-CNN by 2.2% AP with the same ResNet-50 backbone.