 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe 2017 DAVIS Challenge on Video Object Segmentation
Mar 01, 2018
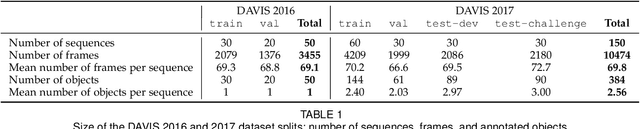

We present the 2017 DAVIS Challenge on Video Object Segmentation, a public dataset, benchmark, and competition specifically designed for the task of video object segmentation. Following the footsteps of other successful initiatives, such as ILSVRC and PASCAL VOC, which established the avenue of research in the fields of scene classification and semantic segmentation, the DAVIS Challenge comprises a dataset, an evaluation methodology, and a public competition with a dedicated workshop co-located with CVPR 2017. The DAVIS Challenge follows up on the recent publication of DAVIS (Densely-Annotated VIdeo Segmentation), which has fostered the development of several novel state-of-the-art video object segmentation techniques. In this paper we describe the scope of the benchmark, highlight the main characteristics of the dataset, define the evaluation metrics of the competition, and present a detailed analysis of the results of the participants to the challenge.
Learning Video Object Segmentation from Static Images
Dec 08, 2016
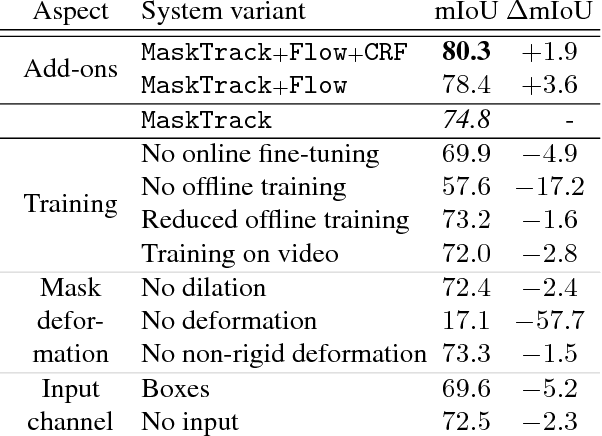
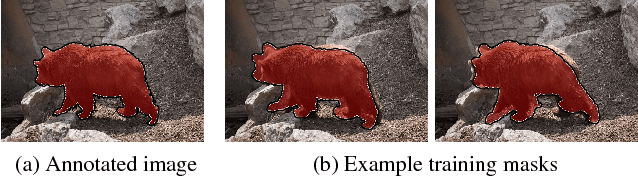
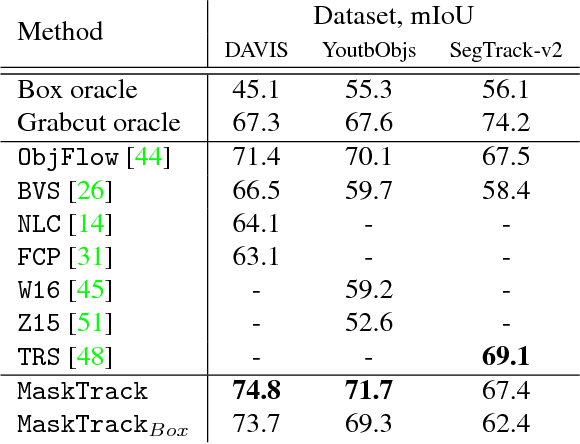
Inspired by recent advances of deep learning in instance segmentation and object tracking, we introduce video object segmentation problem as a concept of guided instance segmentation. Our model proceeds on a per-frame basis, guided by the output of the previous frame towards the object of interest in the next frame. We demonstrate that highly accurate object segmentation in videos can be enabled by using a convnet trained with static images only. The key ingredient of our approach is a combination of offline and online learning strategies, where the former serves to produce a refined mask from the previous frame estimate and the latter allows to capture the appearance of the specific object instance. Our method can handle different types of input annotations: bounding boxes and segments, as well as incorporate multiple annotated frames, making the system suitable for diverse applications. We obtain competitive results on three different datasets, independently from the type of input annotation.