 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPAGHETTI: Open-Domain Question Answering from Heterogeneous Data Sources with Retrieval and Semantic Parsing
Jun 01, 2024



We introduce SPAGHETTI: Semantic Parsing Augmented Generation for Hybrid English information from Text Tables and Infoboxes, a hybrid question-answering (QA) pipeline that utilizes information from heterogeneous knowledge sources, including knowledge base, text, tables, and infoboxes. Our LLM-augmented approach achieves state-of-the-art performance on the Compmix dataset, the most comprehensive heterogeneous open-domain QA dataset, with 56.5% exact match (EM) rate. More importantly, manual analysis on a sample of the dataset suggests that SPAGHETTI is more than 90% accurate, indicating that EM is no longer suitable for assessing the capabilities of QA systems today.
Search Optimization with Query Likelihood Boosting and Two-Level Approximate Search for Edge Devices
Dec 12, 2023



We present a novel search optimization solution for approximate nearest neighbor (ANN) search on resource-constrained edge devices. Traditional ANN approaches fall short in meeting the specific demands of real-world scenarios, e.g., skewed query likelihood distribution and search on large-scale indices with a low latency and small footprint. To address these limitations, we introduce two key components: a Query Likelihood Boosted Tree (QLBT) to optimize average search latency for frequently used small datasets, and a two-level approximate search algorithm to enable efficient retrieval with large datasets on edge devices. We perform thorough evaluation on simulated and real data and demonstrate QLBT can significantly reduce latency by 15% on real data and our two-level search algorithm successfully achieve deployable accuracy and latency on a 10 million dataset for edge devices. In addition, we provide a comprehensive protocol for configuring and optimizing on-device search algorithm through extensive empirical studies.
Robust Nonparametric Distribution Forecast with Backtest-based Bootstrap and Adaptive Residual Selection
Feb 16, 2022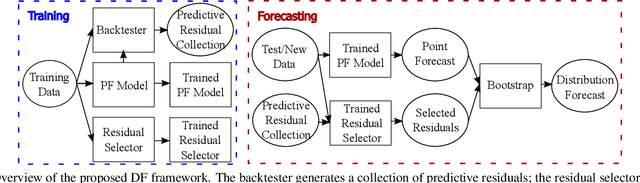
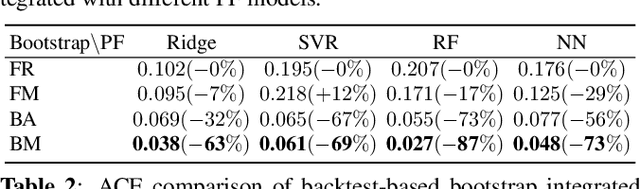
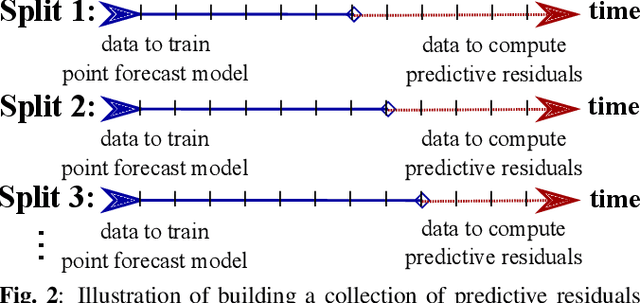

Distribution forecast can quantify forecast uncertainty and provide various forecast scenarios with their corresponding estimated probabilities. Accurate distribution forecast is crucial for planning - for example when making production capacity or inventory allocation decisions. We propose a practical and robust distribution forecast framework that relies on backtest-based bootstrap and adaptive residual selection. The proposed approach is robust to the choice of the underlying forecasting model, accounts for uncertainty around the input covariates, and relaxes the independence between residuals and covariates assumption. It reduces the Absolute Coverage Error by more than 63% compared to the classic bootstrap approaches and by 2% - 32% compared to a variety of State-of-the-Art deep learning approaches on in-house product sales data and M4-hourly competition data.