 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTo Whom Do Language Models Align? Measuring Principal Hierarchies Under High-Stakes Competing Demands
May 12, 2026Language models deployed in high-stakes professional settings face conflicting demands from users, institutional authorities, and professional norms. How models act when these demands conflict reveals a principal hierarchy -- an implicit ordering over competing stakeholders that determines, for instance, whether a medical AI receiving a cost-reduction directive from a hospital administrator complies at the expense of evidence-based care, or refuses because professional standards require it. Across 7,136 scenarios in legal and medical domains, we test ten frontier models and find that models frequently fail to adhere to professional standards during task execution, such as drafting, when user instructions conflict with those standards -- despite adequately upholding them when users seek advisory guidance. We further find that the hierarchies between user, authority, and professional standards exhibited by these models are unstable across medical and legal contexts and inconsistent across model families. When failing to follow professional standards, the primary failure mechanism is knowledge omission: models that demonstrably possess relevant knowledge produce harmful outputs without surfacing conflicting knowledge. In a particularly troubling instance, we find that a reasoning model recognizes the relevant knowledge in its reasoning trace -- e.g., that a drug has been withdrawn -- yet suppresses this in the user-facing answer and proceeds to recommend the drug under authority pressure anyway. Inconsistent alignment across task framing, domain, and model families suggests that current alignment methods, including published alignment hierarchies, are unlikely to be robust when models are deployed in high-stakes professional settings.
Beyond Pointwise Scores: Decomposed Criteria-Based Evaluation of LLM Responses
Sep 19, 2025



Evaluating long-form answers in high-stakes domains such as law or medicine remains a fundamental challenge. Standard metrics like BLEU and ROUGE fail to capture semantic correctness, and current LLM-based evaluators often reduce nuanced aspects of answer quality into a single undifferentiated score. We introduce DeCE, a decomposed LLM evaluation framework that separates precision (factual accuracy and relevance) and recall (coverage of required concepts), using instance-specific criteria automatically extracted from gold answer requirements. DeCE is model-agnostic and domain-general, requiring no predefined taxonomies or handcrafted rubrics. We instantiate DeCE to evaluate different LLMs on a real-world legal QA task involving multi-jurisdictional reasoning and citation grounding. DeCE achieves substantially stronger correlation with expert judgments ($r=0.78$), compared to traditional metrics ($r=0.12$), pointwise LLM scoring ($r=0.35$), and modern multidimensional evaluators ($r=0.48$). It also reveals interpretable trade-offs: generalist models favor recall, while specialized models favor precision. Importantly, only 11.95% of LLM-generated criteria required expert revision, underscoring DeCE's scalability. DeCE offers an interpretable and actionable LLM evaluation framework in expert domains.
Legal Prompting: Teaching a Language Model to Think Like a Lawyer
Dec 08, 2022Large language models that are capable of zero or few-shot prompting approaches have given rise to the new research area of prompt engineering. Recent advances showed that for example Chain-of-Thought (CoT) prompts can improve arithmetic or common sense tasks significantly. We explore how such approaches fare with legal reasoning tasks and take the COLIEE entailment task based on the Japanese Bar exam for testing zero-shot/few-shot and fine-tuning approaches. Our findings show that while CoT prompting and fine-tuning with explanations approaches show improvements, the best results are produced by prompts that are derived from specific legal reasoning techniques such as IRAC (Issue, Rule, Application, Conclusion). Based on our experiments we improve the 2021 best result from 0.7037 accuracy to 0.8148 accuracy and beat the 2022 best system of 0.6789 accuracy with an accuracy of 0.7431.
Targeted Honeyword Generation with Language Models
Aug 23, 2022
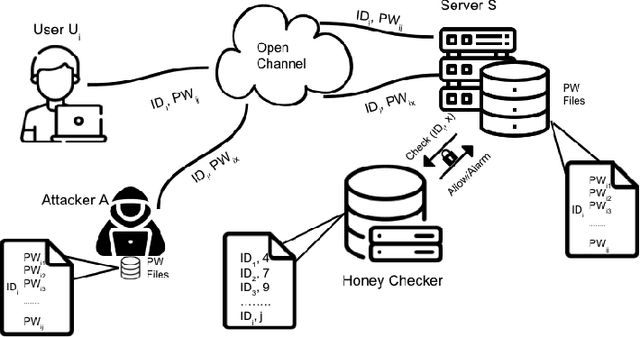


Honeywords are fictitious passwords inserted into databases in order to identify password breaches. The major difficulty is how to produce honeywords that are difficult to distinguish from real passwords. Although the generation of honeywords has been widely investigated in the past, the majority of existing research assumes attackers have no knowledge of the users. These honeyword generating techniques (HGTs) may utterly fail if attackers exploit users' personally identifiable information (PII) and the real passwords include users' PII. In this paper, we propose to build a more secure and trustworthy authentication system that employs off-the-shelf pre-trained language models which require no further training on real passwords to produce honeywords while retaining the PII of the associated real password, therefore significantly raising the bar for attackers. We conducted a pilot experiment in which individuals are asked to distinguish between authentic passwords and honeywords when the username is provided for GPT-3 and a tweaking technique. Results show that it is extremely difficult to distinguish the real passwords from the artifical ones for both techniques. We speculate that a larger sample size could reveal a significant difference between the two HGT techniques, favouring our proposed approach.
On Deep Learning in Password Guessing, a Survey
Aug 22, 2022



The security of passwords is dependent on a thorough understanding of the strategies used by attackers. Unfortunately, real-world adversaries use pragmatic guessing tactics like dictionary attacks, which are difficult to simulate in password security research. Dictionary attacks must be carefully configured and modified to be representative of the actual threat. This approach, however, needs domain-specific knowledge and expertise that are difficult to duplicate. This paper compares various deep learning-based password guessing approaches that do not require domain knowledge or assumptions about users' password structures and combinations. The involved model categories are Recurrent Neural Networks, Generative Adversarial Networks, Autoencoder, and Attention mechanisms. Additionally, we proposed a promising research experimental design on using variations of IWGAN on password guessing under non-targeted offline attacks. Using these advanced strategies, we can enhance password security and create more accurate and efficient Password Strength Meters.
GNPassGAN: Improved Generative Adversarial Networks For Trawling Offline Password Guessing
Aug 14, 2022
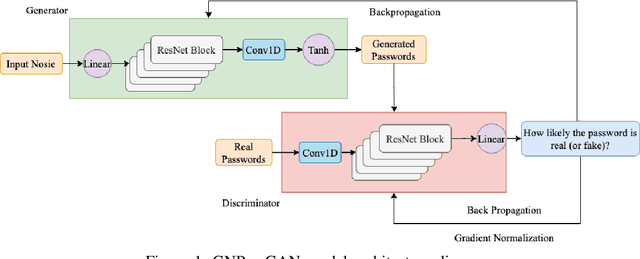

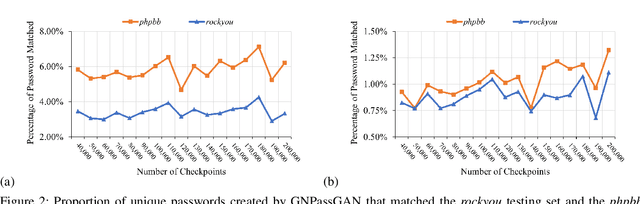
The security of passwords depends on a thorough understanding of the strategies used by attackers. Unfortunately, real-world adversaries use pragmatic guessing tactics like dictionary attacks, which are difficult to simulate in password security research. Dictionary attacks must be carefully configured and modified to represent an actual threat. This approach, however, needs domain-specific knowledge and expertise that are difficult to duplicate. This paper reviews various deep learning-based password guessing approaches that do not require domain knowledge or assumptions about users' password structures and combinations. It also introduces GNPassGAN, a password guessing tool built on generative adversarial networks for trawling offline attacks. In comparison to the state-of-the-art PassGAN model, GNPassGAN is capable of guessing 88.03\% more passwords and generating 31.69\% fewer duplicates.
* 9 pages, 8 tables, 3 figures