 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJailbreakOPT: Tool-Assisted Iterative Jailbreak Prompt Optimization
Jun 09, 2026Jailbreak attacks expose persistent safety weaknesses in large language models (LLMs), but existing stateless single-turn methods face a trade-off: hand-crafted prompts are expressive but static, while iterative prompt optimization can adapt but often relies on low-level mutations that require many target queries. We propose JailbreakOPT, a tool-assisted framework for improving iterative single-turn jailbreak prompt optimization. JailbreakOPT organizes diverse atomic jailbreak prompts into an attack tool library and composes them through a unified intra-episode optimization abstraction to generate stronger standalone attack prompts. To reuse experience across attack episodes, JailbreakOPT further frames tool selection as a contextual bandit problem and applies contextual Thompson sampling to guide exploration and exploitation based on past outcomes. Experiments across multiple target LLMs and attack goals show that JailbreakOPT improves attack success rate (ASR) while reducing the number of attacks until success (No.A) compared with atomic single-turn attacks and existing iterative optimization baselines. This paper may contain offensive or harmful content.
View Confusion Feature Learning for Person Re-identification
Oct 09, 2019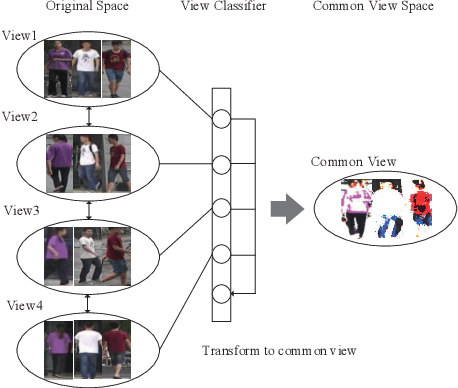
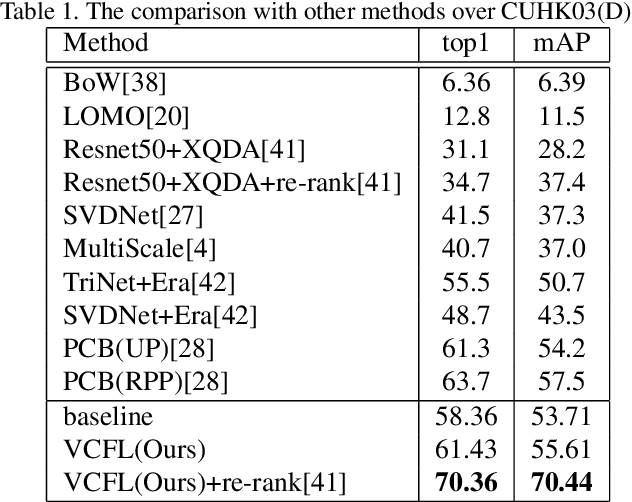
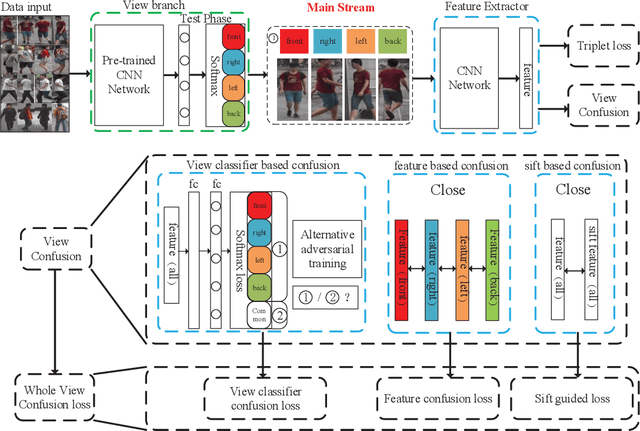
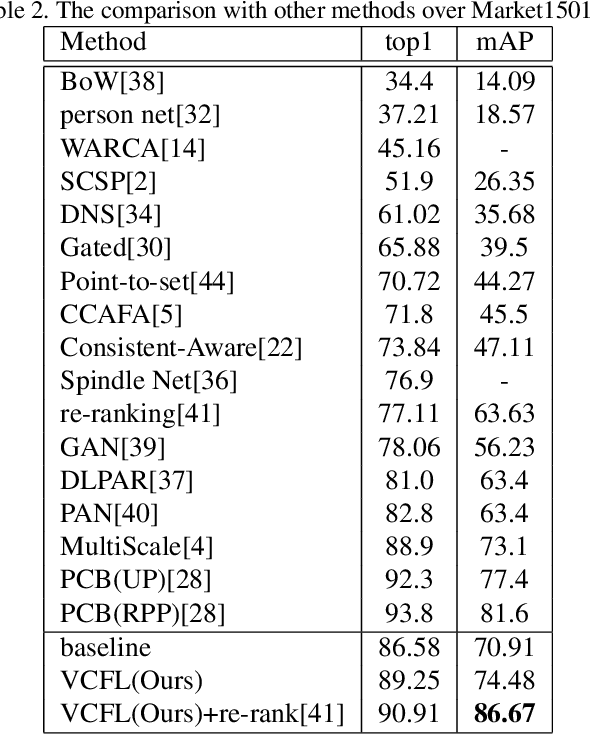
Person re-identification is an important task in video surveillance that aims to associate people across camera views at different locations and time. View variability is always a challenging problem seriously degrading person re-identification performance. Most of the existing methods either focus on how to learn view invariant feature or how to combine view-wise features. In this paper, we mainly focus on how to learn view-invariant features by getting rid of view specific information through a view confusion learning mechanism. Specifically, we propose an end-toend trainable framework, called View Confusion Feature Learning (VCFL), for person Re-ID across cameras. To the best of our knowledge, VCFL is originally proposed to learn view-invariant identity-wise features, and it is a kind of combination of view-generic and view-specific methods. Classifiers and feature centers are utilized to achieve view confusion. Furthermore, we extract sift-guided features by using bag-of-words model to help supervise the training of deep networks and enhance the view invariance of features. In experiments, our approach is validated on three benchmark datasets including CUHK01, CUHK03, and MARKET1501, which show the superiority of the proposed method over several state-of-the-art approaches