 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Fine-Tuning of Sparsely-Activated Large Language Models on Resource-Constrained Devices
Aug 26, 2025Federated fine-tuning of Mixture-of-Experts (MoE)-based large language models (LLMs) is challenging due to their massive computational requirements and the resource constraints of participants. Existing working attempts to fill this gap through model quantization, computation offloading, or expert pruning. However, they cannot achieve desired performance due to impractical system assumptions and a lack of consideration for MoE-specific characteristics. In this paper, we propose FLUX, a system designed to enable federated fine-tuning of MoE-based LLMs across participants with constrained computing resources (e.g., consumer-grade GPUs), aiming to minimize time-to-accuracy. FLUX introduces three key innovations: (1) quantization-based local profiling to estimate expert activation with minimal overhead, (2) adaptive layer-aware expert merging to reduce resource consumption while preserving accuracy, and (3) dynamic expert role assignment using an exploration-exploitation strategy to balance tuning and non-tuning experts. Extensive experiments on LLaMA-MoE and DeepSeek-MoE with multiple benchmark datasets demonstrate that FLUX significantly outperforms existing methods, achieving up to 4.75X speedup in time-to-accuracy.
Internet of Agents: Fundamentals, Applications, and Challenges
May 12, 2025



With the rapid proliferation of large language models and vision-language models, AI agents have evolved from isolated, task-specific systems into autonomous, interactive entities capable of perceiving, reasoning, and acting without human intervention. As these agents proliferate across virtual and physical environments, from virtual assistants to embodied robots, the need for a unified, agent-centric infrastructure becomes paramount. In this survey, we introduce the Internet of Agents (IoA) as a foundational framework that enables seamless interconnection, dynamic discovery, and collaborative orchestration among heterogeneous agents at scale. We begin by presenting a general IoA architecture, highlighting its hierarchical organization, distinguishing features relative to the traditional Internet, and emerging applications. Next, we analyze the key operational enablers of IoA, including capability notification and discovery, adaptive communication protocols, dynamic task matching, consensus and conflict-resolution mechanisms, and incentive models. Finally, we identify open research directions toward building resilient and trustworthy IoA ecosystems.
DGC: Training Dynamic Graphs with Spatio-Temporal Non-Uniformity using Graph Partitioning by Chunks
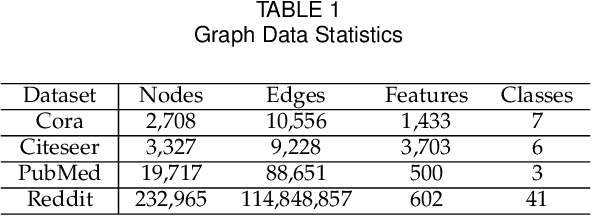
Sep 07, 2023Dynamic Graph Neural Network (DGNN) has shown a strong capability of learning dynamic graphs by exploiting both spatial and temporal features. Although DGNN has recently received considerable attention by AI community and various DGNN models have been proposed, building a distributed system for efficient DGNN training is still challenging. It has been well recognized that how to partition the dynamic graph and assign workloads to multiple GPUs plays a critical role in training acceleration. Existing works partition a dynamic graph into snapshots or temporal sequences, which only work well when the graph has uniform spatio-temporal structures. However, dynamic graphs in practice are not uniformly structured, with some snapshots being very dense while others are sparse. To address this issue, we propose DGC, a distributed DGNN training system that achieves a 1.25x - 7.52x speedup over the state-of-the-art in our testbed. DGC's success stems from a new graph partitioning method that partitions dynamic graphs into chunks, which are essentially subgraphs with modest training workloads and few inter connections. This partitioning algorithm is based on graph coarsening, which can run very fast on large graphs. In addition, DGC has a highly efficient run-time, powered by the proposed chunk fusion and adaptive stale aggregation techniques. Extensive experimental results on 3 typical DGNN models and 4 popular dynamic graph datasets are presented to show the effectiveness of DGC.
FedGraph: Federated Graph Learning with Intelligent Sampling
Nov 02, 2021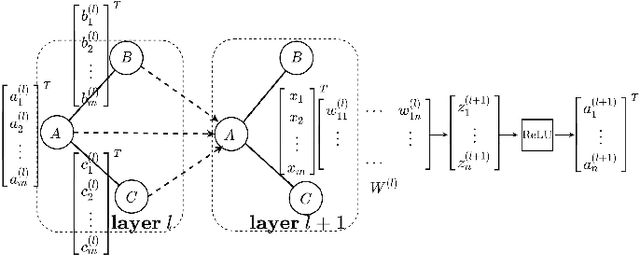
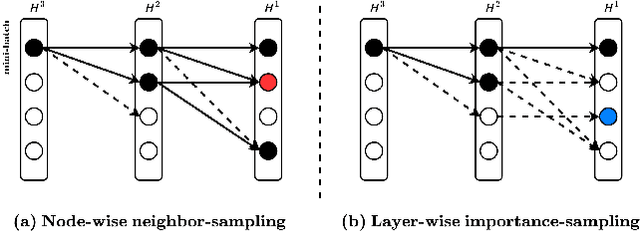
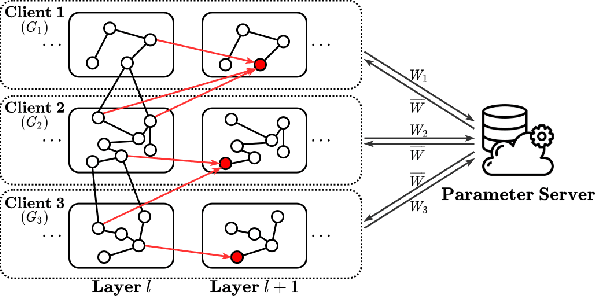
Federated learning has attracted much research attention due to its privacy protection in distributed machine learning. However, existing work of federated learning mainly focuses on Convolutional Neural Network (CNN), which cannot efficiently handle graph data that are popular in many applications. Graph Convolutional Network (GCN) has been proposed as one of the most promising techniques for graph learning, but its federated setting has been seldom explored. In this paper, we propose FedGraph for federated graph learning among multiple computing clients, each of which holds a subgraph. FedGraph provides strong graph learning capability across clients by addressing two unique challenges. First, traditional GCN training needs feature data sharing among clients, leading to risk of privacy leakage. FedGraph solves this issue using a novel cross-client convolution operation. The second challenge is high GCN training overhead incurred by large graph size. We propose an intelligent graph sampling algorithm based on deep reinforcement learning, which can automatically converge to the optimal sampling policies that balance training speed and accuracy. We implement FedGraph based on PyTorch and deploy it on a testbed for performance evaluation. The experimental results of four popular datasets demonstrate that FedGraph significantly outperforms existing work by enabling faster convergence to higher accuracy.