 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinding Deep-Learning Compilation Bugs with NNSmith
Jul 26, 2022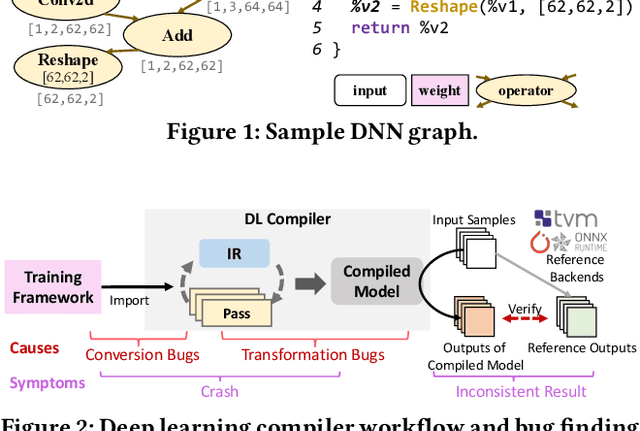


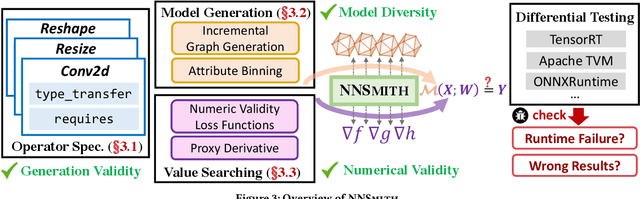
Deep-learning (DL) compilers such as TVM and TensorRT are increasingly used to optimize deep neural network (DNN) models to meet performance, resource utilization and other requirements. Bugs in these compilers can produce optimized models whose semantics differ from the original models, and produce incorrect results impacting the correctness of down stream applications. However, finding bugs in these compilers is challenging due to their complexity. In this work, we propose a new fuzz testing approach for finding bugs in deep-learning compilers. Our core approach uses (i) light-weight operator specifications to generate diverse yet valid DNN models allowing us to exercise a large part of the compiler's transformation logic; (ii) a gradient-based search process for finding model inputs that avoid any floating-point exceptional values during model execution, reducing the chance of missed bugs or false alarms; and (iii) differential testing to identify bugs. We implemented this approach in NNSmith which has found 65 new bugs in the last seven months for TVM, TensorRT, ONNXRuntime, and PyTorch. Of these 52 have been confirmed and 44 have been fixed by project maintainers.
The State of Knowledge Distillation for Classification
Dec 20, 2019

We survey various knowledge distillation (KD) strategies for simple classification tasks and implement a set of techniques that claim state-of-the-art accuracy. Our experiments using standardized model architectures, fixed compute budgets, and consistent training schedules indicate that many of these distillation results are hard to reproduce. This is especially apparent with methods using some form of feature distillation. Further examination reveals a lack of generalizability where these techniques may only succeed for specific architectures and training settings. We observe that appropriately tuned classical distillation in combination with a data augmentation training scheme gives an orthogonal improvement over other techniques. We validate this approach and open-source our code.
Iroko: A Framework to Prototype Reinforcement Learning for Data Center Traffic Control
Dec 24, 2018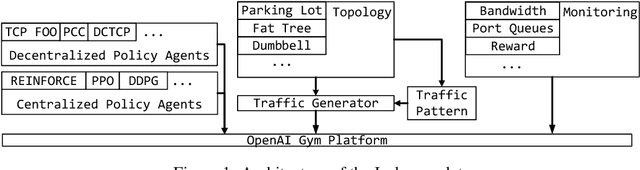
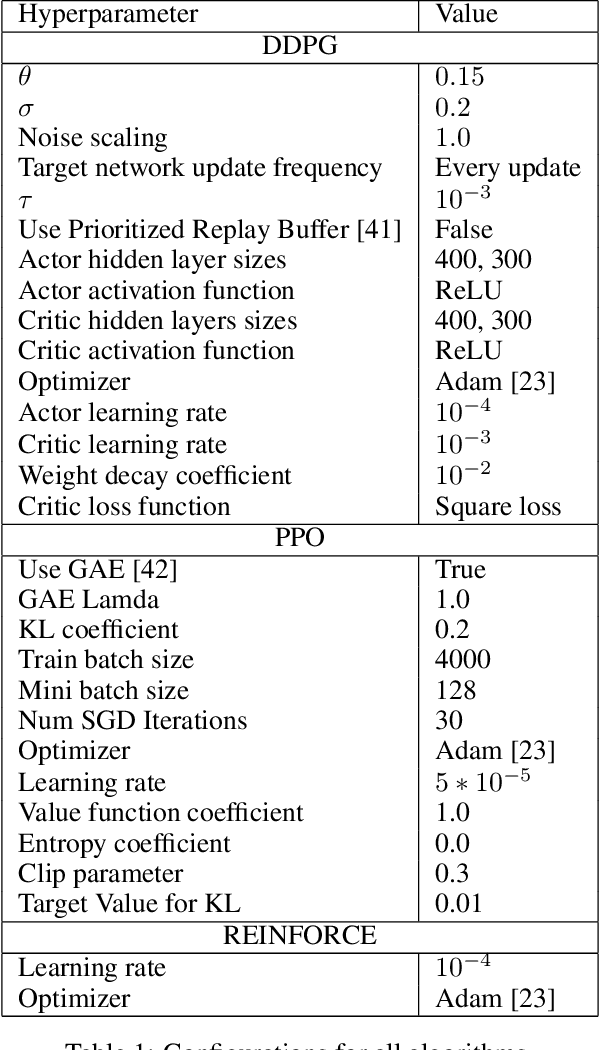
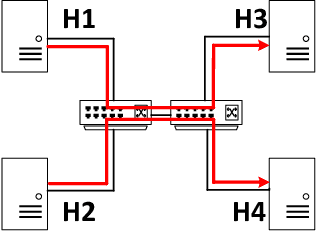
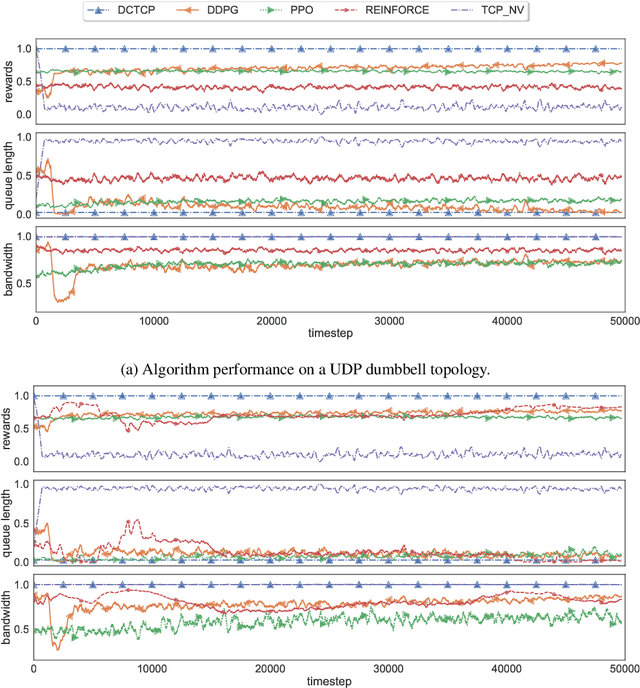
Recent networking research has identified that data-driven congestion control (CC) can be more efficient than traditional CC in TCP. Deep reinforcement learning (RL), in particular, has the potential to learn optimal network policies. However, RL suffers from instability and over-fitting, deficiencies which so far render it unacceptable for use in datacenter networks. In this paper, we analyze the requirements for RL to succeed in the datacenter context. We present a new emulator, Iroko, which we developed to support different network topologies, congestion control algorithms, and deployment scenarios. Iroko interfaces with the OpenAI gym toolkit, which allows for fast and fair evaluation of different RL and traditional CC algorithms under the same conditions. We present initial benchmarks on three deep RL algorithms compared to TCP New Vegas and DCTCP. Our results show that these algorithms are able to learn a CC policy which exceeds the performance of TCP New Vegas on a dumbbell and fat-tree topology. We make our emulator open-source and publicly available: https://github.com/dcgym/iroko