 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Aligned Canonical Correlation Analysis: Preliminary Formulation and Proof-of-Concept Results
Dec 08, 2023


Canonical Correlation Analysis (CCA) has been widely applied to jointly embed multiple views of data in a maximally correlated latent space. However, the alignment between various data perspectives, which is required by traditional approaches, is unclear in many practical cases. In this work we propose a new framework Aligned Canonical Correlation Analysis (ACCA), to address this challenge by iteratively solving the alignment and multi-view embedding.
CARL-G: Clustering-Accelerated Representation Learning on Graphs
Jun 12, 2023



Self-supervised learning on graphs has made large strides in achieving great performance in various downstream tasks. However, many state-of-the-art methods suffer from a number of impediments, which prevent them from realizing their full potential. For instance, contrastive methods typically require negative sampling, which is often computationally costly. While non-contrastive methods avoid this expensive step, most existing methods either rely on overly complex architectures or dataset-specific augmentations. In this paper, we ask: Can we borrow from classical unsupervised machine learning literature in order to overcome those obstacles? Guided by our key insight that the goal of distance-based clustering closely resembles that of contrastive learning: both attempt to pull representations of similar items together and dissimilar items apart. As a result, we propose CARL-G - a novel clustering-based framework for graph representation learning that uses a loss inspired by Cluster Validation Indices (CVIs), i.e., internal measures of cluster quality (no ground truth required). CARL-G is adaptable to different clustering methods and CVIs, and we show that with the right choice of clustering method and CVI, CARL-G outperforms node classification baselines on 4/5 datasets with up to a 79x training speedup compared to the best-performing baseline. CARL-G also performs at par or better than baselines in node clustering and similarity search tasks, training up to 1,500x faster than the best-performing baseline. Finally, we also provide theoretical foundations for the use of CVI-inspired losses in graph representation learning.
Link Prediction with Non-Contrastive Learning
Nov 25, 2022A recent focal area in the space of graph neural networks (GNNs) is graph self-supervised learning (SSL), which aims to derive useful node representations without labeled data. Notably, many state-of-the-art graph SSL methods are contrastive methods, which use a combination of positive and negative samples to learn node representations. Owing to challenges in negative sampling (slowness and model sensitivity), recent literature introduced non-contrastive methods, which instead only use positive samples. Though such methods have shown promising performance in node-level tasks, their suitability for link prediction tasks, which are concerned with predicting link existence between pairs of nodes (and have broad applicability to recommendation systems contexts) is yet unexplored. In this work, we extensively evaluate the performance of existing non-contrastive methods for link prediction in both transductive and inductive settings. While most existing non-contrastive methods perform poorly overall, we find that, surprisingly, BGRL generally performs well in transductive settings. However, it performs poorly in the more realistic inductive settings where the model has to generalize to links to/from unseen nodes. We find that non-contrastive models tend to overfit to the training graph and use this analysis to propose T-BGRL, a novel non-contrastive framework that incorporates cheap corruptions to improve the generalization ability of the model. This simple modification strongly improves inductive performance in 5/6 of our datasets, with up to a 120% improvement in Hits@50--all with comparable speed to other non-contrastive baselines and up to 14x faster than the best-performing contrastive baseline. Our work imparts interesting findings about non-contrastive learning for link prediction and paves the way for future researchers to further expand upon this area.
FRAPPE: $\underline{\text{F}}$ast $\underline{\text{Ra}}$nk $\underline{\text{App}}$roximation with $\underline{\text{E}}$xplainable Features for Tensors
Jun 19, 2022Tensor decompositions have proven to be effective in analyzing the structure of multidimensional data. However, most of these methods require a key parameter: the number of desired components. In the case of the CANDECOMP/PARAFAC decomposition (CPD), this value is known as the canonical rank and greatly affects the quality of the results. Existing methods use heuristics or Bayesian methods to estimate this value by repeatedly calculating the CPD, making them extremely computationally expensive. In this work, we propose FRAPPE and Self-FRAPPE: a cheaply supervised and a self-supervised method to estimate the canonical rank of a tensor without ever having to compute the CPD. We call FRAPPE cheaply supervised because it uses a fully synthetic training set without requiring real-world examples. We evaluate these methods on synthetic tensors, real tensors of known rank, and the weight tensor of a convolutional neural network. We show that FRAPPE and Self-FRAPPE offer large improvements in both effectiveness and speed, with a respective $15\%$ and $10\%$ improvement in MAPE and an $4000\times$ and $13\times$ improvement in evaluation speed over the best-performing baseline.
MAVIPER: Learning Decision Tree Policies for Interpretable Multi-Agent Reinforcement Learning
May 25, 2022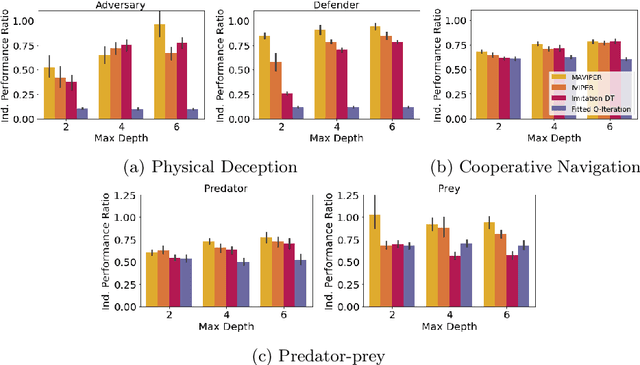
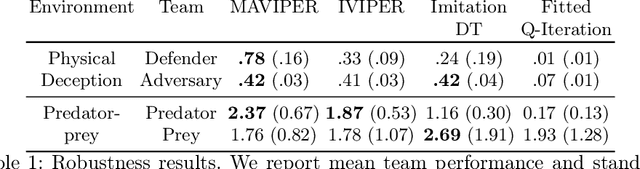
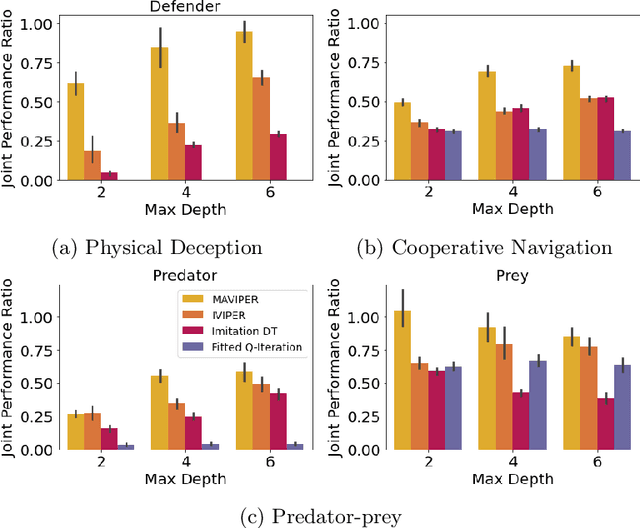
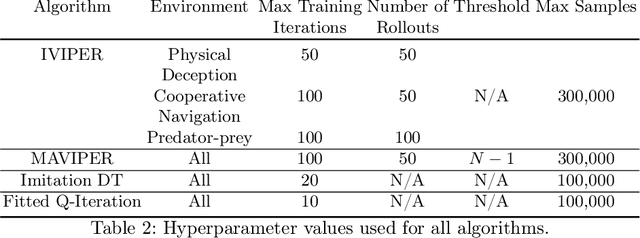
Many recent breakthroughs in multi-agent reinforcement learning (MARL) require the use of deep neural networks, which are challenging for human experts to interpret and understand. On the other hand, existing work on interpretable RL has shown promise in extracting more interpretable decision tree-based policies, but only in the single-agent setting. To fill this gap, we propose the first set of interpretable MARL algorithms that extract decision-tree policies from neural networks trained with MARL. The first algorithm, IVIPER, extends VIPER, a recent method for single-agent interpretable RL, to the multi-agent setting. We demonstrate that IVIPER can learn high-quality decision-tree policies for each agent. To better capture coordination between agents, we propose a novel centralized decision-tree training algorithm, MAVIPER. MAVIPER jointly grows the trees of each agent by predicting the behavior of the other agents using their anticipated trees, and uses resampling to focus on states that are critical for its interactions with other agents. We show that both algorithms generally outperform the baselines and that MAVIPER-trained agents achieve better-coordinated performance than IVIPER-trained agents on three different multi-agent particle-world environments.
Deepfake Representation with Multilinear Regression
Aug 15, 2021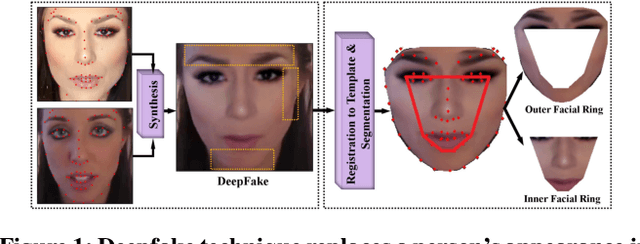
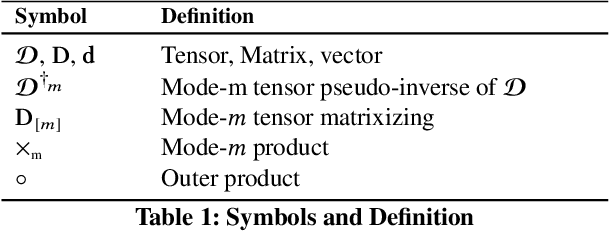
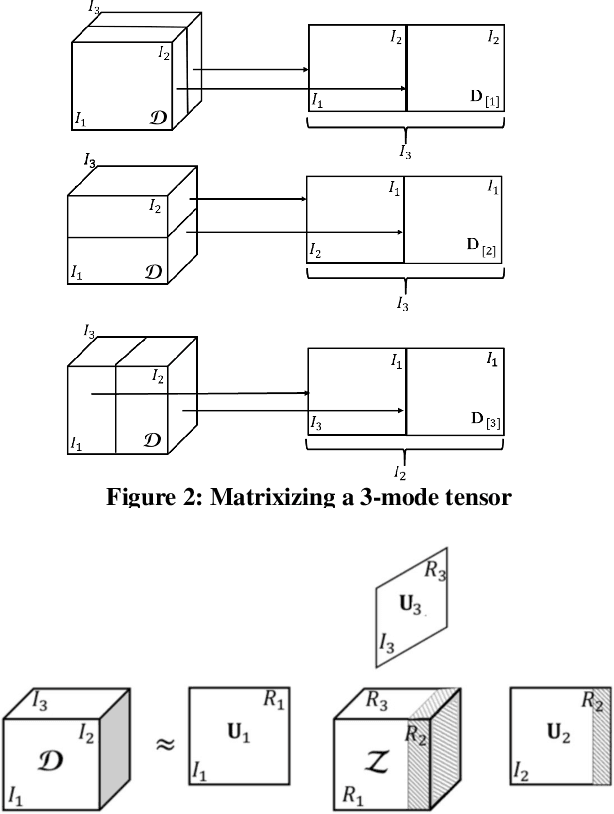
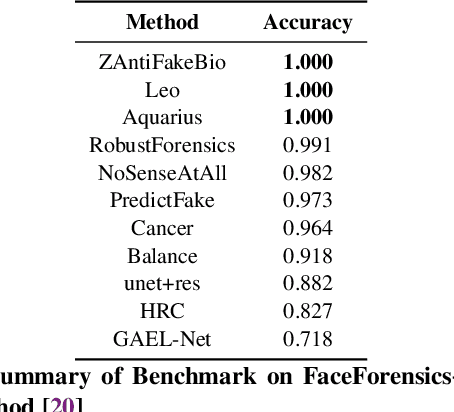
Generative neural network architectures such as GANs, may be used to generate synthetic instances to compensate for the lack of real data. However, they may be employed to create media that may cause social, political or economical upheaval. One emerging media is "Deepfake".Techniques that can discriminate between such media is indispensable. In this paper, we propose a modified multilinear (tensor) method, a combination of linear and multilinear regressions for representing fake and real data. We test our approach by representing Deepfakes with our modified multilinear (tensor) approach and perform SVM classification with encouraging results.
Subspace Clustering Based Analysis of Neural Networks
Jul 02, 2021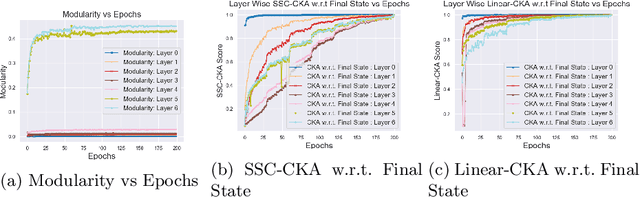

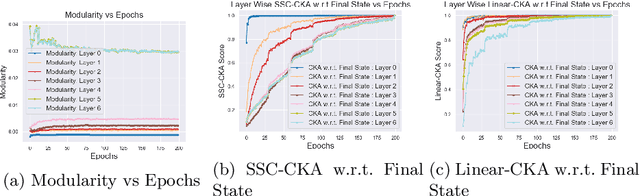
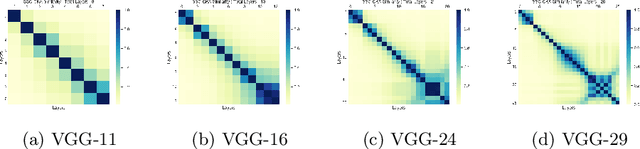
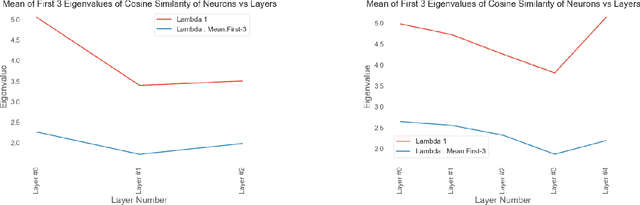
Tools to analyze the latent space of deep neural networks provide a step towards better understanding them. In this work, we motivate sparse subspace clustering (SSC) with an aim to learn affinity graphs from the latent structure of a given neural network layer trained over a set of inputs. We then use tools from Community Detection to quantify structures present in the input. These experiments reveal that as we go deeper in a network, inputs tend to have an increasing affinity to other inputs of the same class. Subsequently, we utilise matrix similarity measures to perform layer-wise comparisons between affinity graphs. In doing so we first demonstrate that when comparing a given layer currently under training to its final state, the shallower the layer of the network, the quicker it is to converge than the deeper layers. When performing a pairwise analysis of the entire network architecture, we observe that, as the network increases in size, it reorganises from a state where each layer is moderately similar to its neighbours, to a state where layers within a block have high similarity than to layers in other blocks. Finally, we analyze the learned affinity graphs of the final convolutional layer of the network and demonstrate how an input's local neighbourhood affects its classification by the network.
KNH: Multi-View Modeling with K-Nearest Hyperplanes Graph for Misinformation Detection
Feb 15, 2021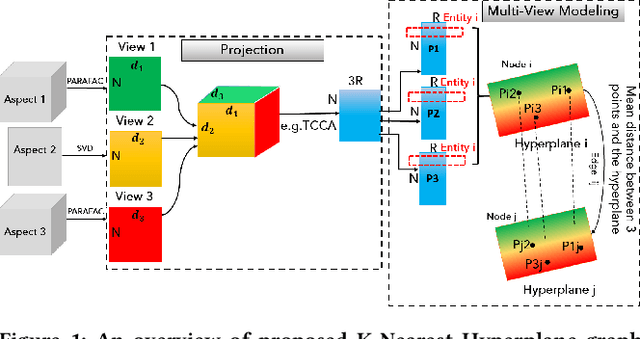

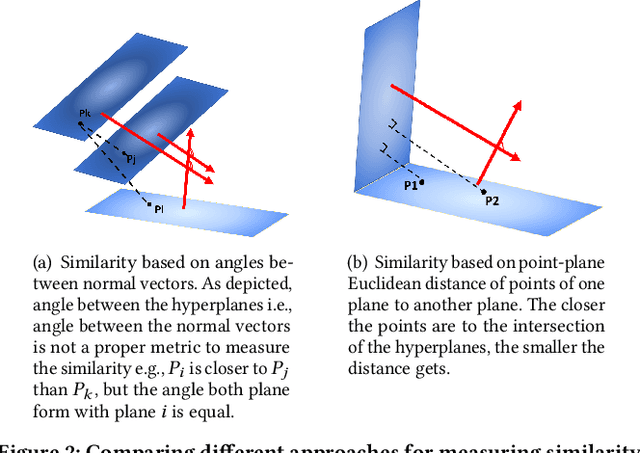
Graphs are one of the most efficacious structures for representing datapoints and their relations, and they have been largely exploited for different applications. Previously, the higher-order relations between the nodes have been modeled by a generalization of graphs known as hypergraphs. In hypergraphs, the edges are defined by a set of nodes i.e., hyperedges to demonstrate the higher order relationships between the data. However, there is no explicit higher-order generalization for nodes themselves. In this work, we introduce a novel generalization of graphs i.e., K-Nearest Hyperplanes graph (KNH) where the nodes are defined by higher order Euclidean subspaces for multi-view modeling of the nodes. In fact, in KNH, nodes are hyperplanes or more precisely m-flats instead of datapoints. We experimentally evaluate the KNH graph on two multi-aspect datasets for misinformation detection. The experimental results suggest that multi-view modeling of articles using KNH graph outperforms the classic KNN graph in terms of classification performance.
Identifying Misinformation from Website Screenshots
Feb 15, 2021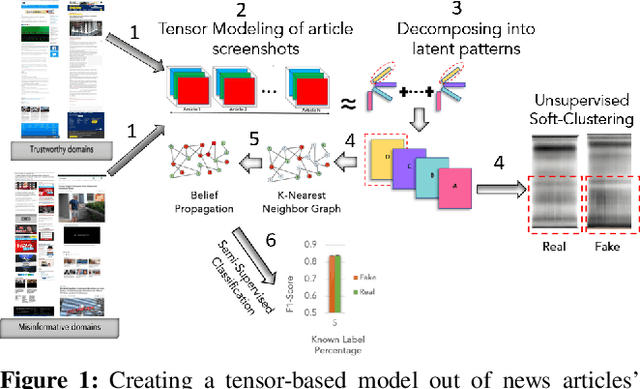

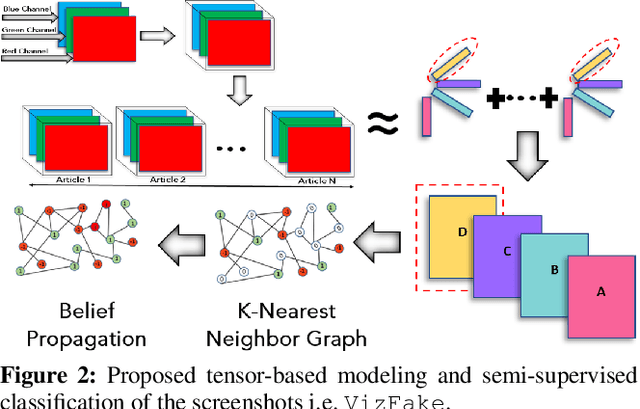
Can the look and the feel of a website give information about the trustworthiness of an article? In this paper, we propose to use a promising, yet neglected aspect in detecting the misinformativeness: the overall look of the domain webpage. To capture this overall look, we take screenshots of news articles served by either misinformative or trustworthy web domains and leverage a tensor decomposition based semi-supervised classification technique. The proposed approach i.e., VizFake is insensitive to a number of image transformations such as converting the image to grayscale, vectorizing the image and losing some parts of the screenshots. VizFake leverages a very small amount of known labels, mirroring realistic and practical scenarios, where labels (especially for known misinformative articles), are scarce and quickly become dated. The F1 score of VizFake on a dataset of 50k screenshots of news articles spanning more than 500 domains is roughly 85% using only 5% of ground truth labels. Furthermore, tensor representations of VizFake, obtained in an unsupervised manner, allow for exploratory analysis of the data that provides valuable insights into the problem. Finally, we compare VizFake with deep transfer learning, since it is a very popular black-box approach for image classification and also well-known text text-based methods. VizFake achieves competitive accuracy with deep transfer learning models while being two orders of magnitude faster and not requiring laborious hyper-parameter tuning.
Analyzing Representations inside Convolutional Neural Networks
Dec 23, 2020

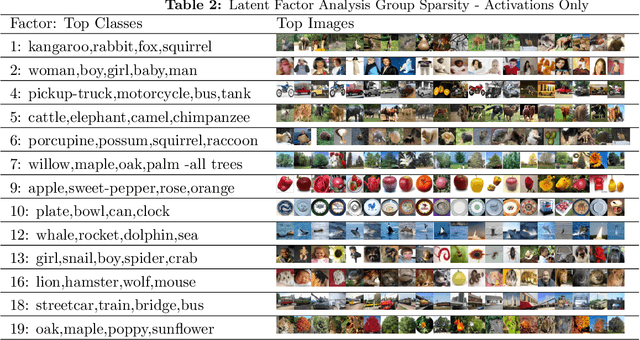
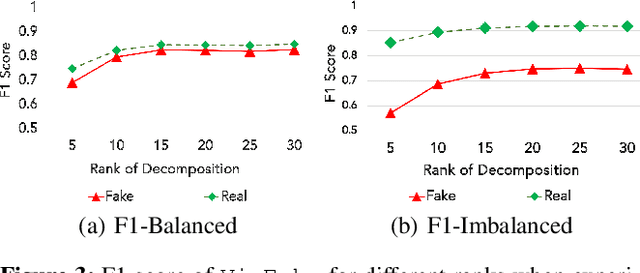
How can we discover and succinctly summarize the concepts that a neural network has learned? Such a task is of great importance in applications of networks in areas of inference that involve classification, like medical diagnosis based on fMRI/x-ray etc. In this work, we propose a framework to categorize the concepts a network learns based on the way it clusters a set of input examples, clusters neurons based on the examples they activate for, and input features all in the same latent space. This framework is unsupervised and can work without any labels for input features, it only needs access to internal activations of the network for each input example, thereby making it widely applicable. We extensively evaluate the proposed method and demonstrate that it produces human-understandable and coherent concepts that a ResNet-18 has learned on the CIFAR-100 dataset.