 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSegmentation and Classification of Pap Smear Images for Cervical Cancer Detection Using Deep Learning
Aug 25, 2025



Cervical cancer remains a significant global health concern and a leading cause of cancer-related deaths among women. Early detection through Pap smear tests is essential to reduce mortality rates; however, the manual examination is time consuming and prone to human error. This study proposes a deep learning framework that integrates U-Net for segmentation and a classification model to enhance diagnostic performance. The Herlev Pap Smear Dataset, a publicly available cervical cell dataset, was utilized for training and evaluation. The impact of segmentation on classification performance was evaluated by comparing the model trained on segmented images and another trained on non-segmented images. Experimental results showed that the use of segmented images marginally improved the model performance on precision (about 0.41 percent higher) and F1-score (about 1.30 percent higher), which suggests a slightly more balanced classification performance. While segmentation helps in feature extraction, the results showed that its impact on classification performance appears to be limited. The proposed framework offers a supplemental tool for clinical applications, which may aid pathologists in early diagnosis.
HAMLET: Healthcare-focused Adaptive Multilingual Learning Embedding-based Topic Modeling
May 12, 2025Traditional topic models often struggle with contextual nuances and fail to adequately handle polysemy and rare words. This limitation typically results in topics that lack coherence and quality. Large Language Models (LLMs) can mitigate this issue by generating an initial set of topics. However, these raw topics frequently lack refinement and representativeness, which leads to redundancy without lexical similarity and reduced interpretability. This paper introduces HAMLET, a graph-driven architecture for cross-lingual healthcare topic modeling that uses LLMs. The proposed approach leverages neural-enhanced semantic fusion to refine the embeddings of topics generated by the LLM. Instead of relying solely on statistical co-occurrence or human interpretation to extract topics from a document corpus, this method introduces a topic embedding refinement that uses Bidirectional Encoder Representations from Transformers (BERT) and Graph Neural Networks (GNN). After topic generation, a hybrid technique that involves BERT and Sentence-BERT (SBERT) is employed for embedding. The topic representations are further refined using a GNN, which establishes connections between documents, topics, words, similar topics, and similar words. A novel method is introduced to compute similarities. Consequently, the topic embeddings are refined, and the top k topics are extracted. Experiments were conducted using two healthcare datasets, one in English and one in French, from which six sets were derived. The results demonstrate the effectiveness of HAMLET.
KDH-MLTC: Knowledge Distillation for Healthcare Multi-Label Text Classification
May 12, 2025The increasing volume of healthcare textual data requires computationally efficient, yet highly accurate classification approaches able to handle the nuanced and complex nature of medical terminology. This research presents Knowledge Distillation for Healthcare Multi-Label Text Classification (KDH-MLTC), a framework leveraging model compression and Large Language Models (LLMs). The proposed approach addresses conventional healthcare Multi-Label Text Classification (MLTC) challenges by integrating knowledge distillation and sequential fine-tuning, subsequently optimized through Particle Swarm Optimization (PSO) for hyperparameter tuning. KDH-MLTC transfers knowledge from a more complex teacher LLM (i.e., BERT) to a lighter student LLM (i.e., DistilBERT) through sequential training adapted to MLTC that preserves the teacher's learned information while significantly reducing computational requirements. As a result, the classification is enabled to be conducted locally, making it suitable for healthcare textual data characterized by sensitivity and, therefore, ensuring HIPAA compliance. The experiments conducted on three medical literature datasets of different sizes, sampled from the Hallmark of Cancer (HoC) dataset, demonstrate that KDH-MLTC achieves superior performance compared to existing approaches, particularly for the largest dataset, reaching an F1 score of 82.70%. Additionally, statistical validation and an ablation study are carried out, proving the robustness of KDH-MLTC. Furthermore, the PSO-based hyperparameter optimization process allowed the identification of optimal configurations. The proposed approach contributes to healthcare text classification research, balancing efficiency requirements in resource-constrained healthcare settings with satisfactory accuracy demands.
Large Language Models for Healthcare Text Classification: A Systematic Review
Mar 03, 2025



Large Language Models (LLMs) have fundamentally transformed approaches to Natural Language Processing (NLP) tasks across diverse domains. In healthcare, accurate and cost-efficient text classification is crucial, whether for clinical notes analysis, diagnosis coding, or any other task, and LLMs present promising potential. Text classification has always faced multiple challenges, including manual annotation for training, handling imbalanced data, and developing scalable approaches. With healthcare, additional challenges are added, particularly the critical need to preserve patients' data privacy and the complexity of the medical terminology. Numerous studies have been conducted to leverage LLMs for automated healthcare text classification and contrast the results with existing machine learning-based methods where embedding, annotation, and training are traditionally required. Existing systematic reviews about LLMs either do not specialize in text classification or do not focus on the healthcare domain. This research synthesizes and critically evaluates the current evidence found in the literature regarding the use of LLMs for text classification in a healthcare setting. Major databases (e.g., Google Scholar, Scopus, PubMed, Science Direct) and other resources were queried, which focused on the papers published between 2018 and 2024 within the framework of PRISMA guidelines, which resulted in 65 eligible research articles. These were categorized by text classification type (e.g., binary classification, multi-label classification), application (e.g., clinical decision support, public health and opinion analysis), methodology, type of healthcare text, and metrics used for evaluation and validation. This review reveals the existing gaps in the literature and suggests future research lines that can be investigated and explored.
QUAD-LLM-MLTC: Large Language Models Ensemble Learning for Healthcare Text Multi-Label Classification
Feb 20, 2025The escalating volume of collected healthcare textual data presents a unique challenge for automated Multi-Label Text Classification (MLTC), which is primarily due to the scarcity of annotated texts for training and their nuanced nature. Traditional machine learning models often fail to fully capture the array of expressed topics. However, Large Language Models (LLMs) have demonstrated remarkable effectiveness across numerous Natural Language Processing (NLP) tasks in various domains, which show impressive computational efficiency and suitability for unsupervised learning through prompt engineering. Consequently, these LLMs promise an effective MLTC of medical narratives. However, when dealing with various labels, different prompts can be relevant depending on the topic. To address these challenges, the proposed approach, QUAD-LLM-MLTC, leverages the strengths of four LLMs: GPT-4o, BERT, PEGASUS, and BART. QUAD-LLM-MLTC operates in a sequential pipeline in which BERT extracts key tokens, PEGASUS augments textual data, GPT-4o classifies, and BART provides topics' assignment probabilities, which results in four classifications, all in a 0-shot setting. The outputs are then combined using ensemble learning and processed through a meta-classifier to produce the final MLTC result. The approach is evaluated using three samples of annotated texts, which contrast it with traditional and single-model methods. The results show significant improvements across the majority of the topics in the classification's F1 score and consistency (F1 and Micro-F1 scores of 78.17% and 80.16% with standard deviations of 0.025 and 0.011, respectively). This research advances MLTC using LLMs and provides an efficient and scalable solution to rapidly categorize healthcare-related text data without further training.
Large Language Models for Patient Comments Multi-Label Classification
Oct 31, 2024



Patient experience and care quality are crucial for a hospital's sustainability and reputation. The analysis of patient feedback offers valuable insight into patient satisfaction and outcomes. However, the unstructured nature of these comments poses challenges for traditional machine learning methods following a supervised learning paradigm. This is due to the unavailability of labeled data and the nuances these texts encompass. This research explores leveraging Large Language Models (LLMs) in conducting Multi-label Text Classification (MLTC) of inpatient comments shared after a stay in the hospital. GPT-4o-Turbo was leveraged to conduct the classification. However, given the sensitive nature of patients' comments, a security layer is introduced before feeding the data to the LLM through a Protected Health Information (PHI) detection framework, which ensures patients' de-identification. Additionally, using the prompt engineering framework, zero-shot learning, in-context learning, and chain-of-thought prompting were experimented with. Results demonstrate that GPT-4o-Turbo, whether following a zero-shot or few-shot setting, outperforms traditional methods and Pre-trained Language Models (PLMs) and achieves the highest overall performance with an F1-score of 76.12% and a weighted F1-score of 73.61% followed closely by the few-shot learning results. Subsequently, the results' association with other patient experience structured variables (e.g., rating) was conducted. The study enhances MLTC through the application of LLMs, offering healthcare practitioners an efficient method to gain deeper insights into patient feedback and deliver prompt, appropriate responses.
RECS: Robust Graph Embedding Using Connection Subgraphs
Sep 05, 2018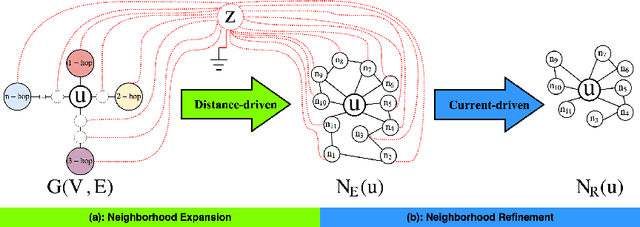
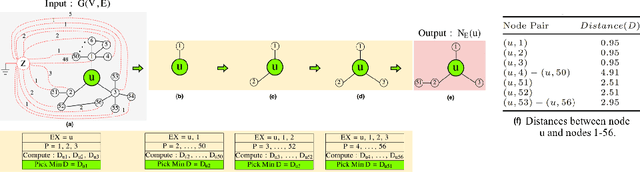
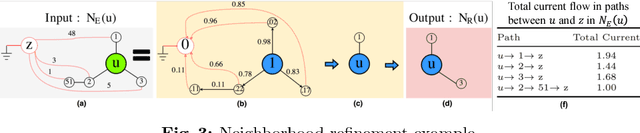
The success of graph embeddings or node representation learning in a variety of downstream tasks, such as node classification, link prediction, and recommendation systems, has led to their popularity in recent years. Representation learning algorithms aim to preserve local and global network structure by identifying node neighborhood notions. However, many existing algorithms generate embeddings that fail to properly preserve the network structure, or lead to unstable representations due to random processes (e.g., random walks to generate context) and, thus, cannot generate to multi-graph problems. In this paper, we propose RECS, a novel, stable graph embedding algorithmic framework. RECS learns graph representations using connection subgraphs by employing the analogy of graphs with electrical circuits. It preserves both local and global connectivity patterns, and addresses the issue of high-degree nodes. Further, it exploits the strength of weak ties and meta-data that have been neglected by baselines. The experiments show that RECS outperforms state-of-the-art algorithms by up to 36.85% on multi-label classification problem. Further, in contrast to baselines, RECS, being deterministic, is completely stable.
t-PINE: Tensor-based Predictable and Interpretable Node Embeddings
May 03, 2018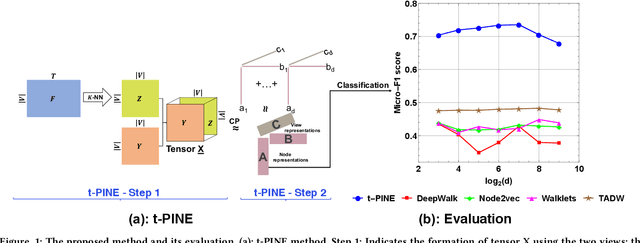

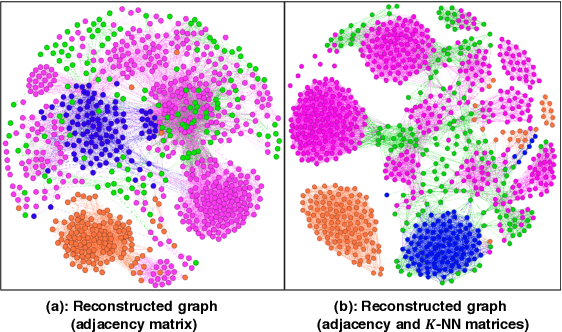
Graph representations have increasingly grown in popularity during the last years. Existing representation learning approaches explicitly encode network structure. Despite their good performance in downstream processes (e.g., node classification, link prediction), there is still room for improvement in different aspects, like efficacy, visualization, and interpretability. In this paper, we propose, t-PINE, a method that addresses these limitations. Contrary to baseline methods, which generally learn explicit graph representations by solely using an adjacency matrix, t-PINE avails a multi-view information graph, the adjacency matrix represents the first view, and a nearest neighbor adjacency, computed over the node features, is the second view, in order to learn explicit and implicit node representations, using the Canonical Polyadic (a.k.a. CP) decomposition. We argue that the implicit and the explicit mapping from a higher-dimensional to a lower-dimensional vector space is the key to learn more useful, highly predictable, and gracefully interpretable representations. Having good interpretable representations provides a good guidance to understand how each view contributes to the representation learning process. In addition, it helps us to exclude unrelated dimensions. Extensive experiments show that t-PINE drastically outperforms baseline methods by up to 158.6% with respect to Micro-F1, in several multi-label classification problems, while it has high visualization and interpretability utility.