 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-supervised Learning for Deep Models in Recommendations
Jul 25, 2020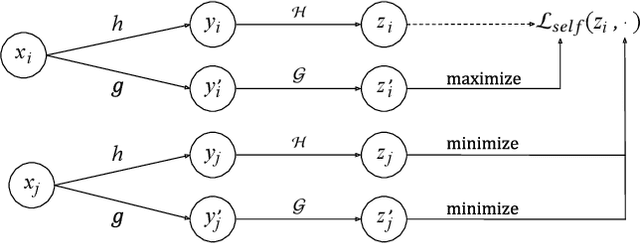
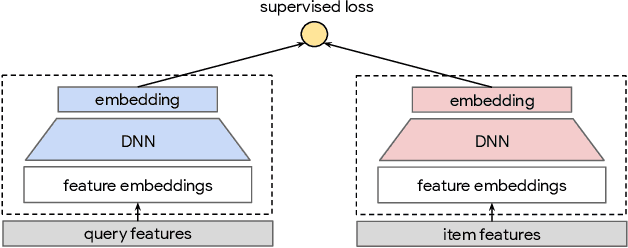
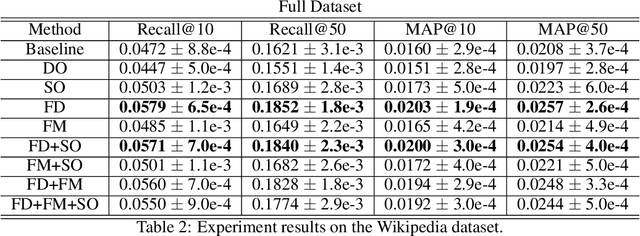
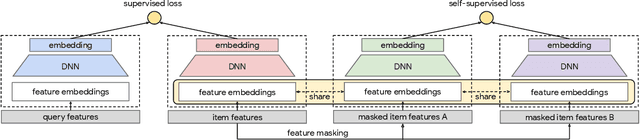
Large scale neural recommender models play a critical role in modern search and recommendation systems. To model large-vocab sparse categorical features, typical recommender models learn a joint embedding space for both queries and items. With millions to billions of items to choose from, the quality of learned embedding representations is crucial to provide high quality recommendations to users with various interests. Inspired by the recent success in self-supervised representation learning research in both computer vision and natural language understanding, we propose a multi-task self-supervised learning (SSL) framework for sparse neural models in recommendations. Furthermore, we propose two highly generalizable self-supervised learning tasks: (i) Feature Masking (FM) and (ii) Feature Dropout (FD) within the proposed SSL framework. We evaluate our framework using two large-scale datasets with ~500M and 1B training examples respectively. Our results demonstrate that the proposed framework outperforms baseline models and state-of-the-art spread-out regularization techniques in the context of retrieval. The SSL framework shows larger improvement with less supervision compared to the counterparts.
Non-Convex Boosting Overcomes Random Label Noise
Sep 09, 2014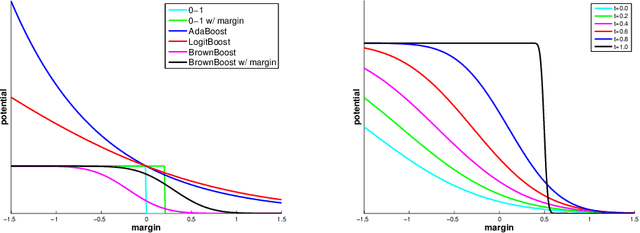
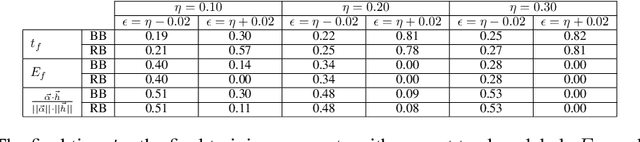
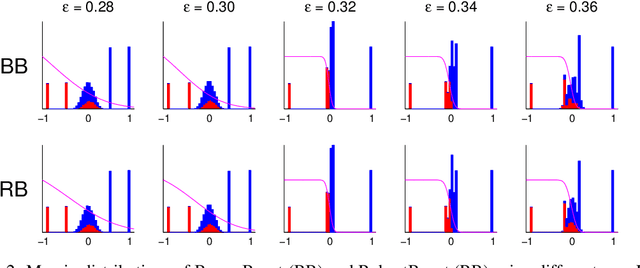

The sensitivity of Adaboost to random label noise is a well-studied problem. LogitBoost, BrownBoost and RobustBoost are boosting algorithms claimed to be less sensitive to noise than AdaBoost. We present the results of experiments evaluating these algorithms on both synthetic and real datasets. We compare the performance on each of datasets when the labels are corrupted by different levels of independent label noise. In presence of random label noise, we found that BrownBoost and RobustBoost perform significantly better than AdaBoost and LogitBoost, while the difference between each pair of algorithms is insignificant. We provide an explanation for the difference based on the margin distributions of the algorithms.
Particle Filtering on the Audio Localization Manifold
Mar 02, 2010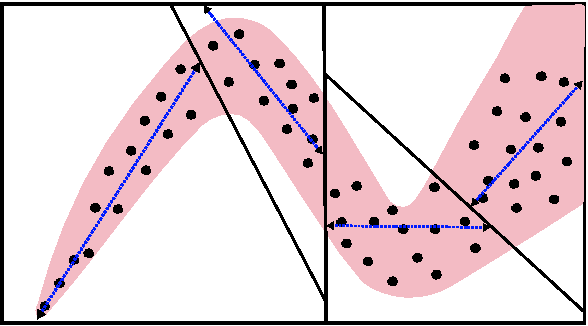
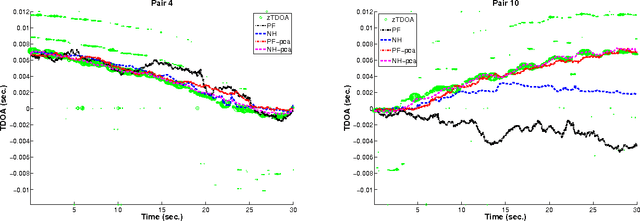
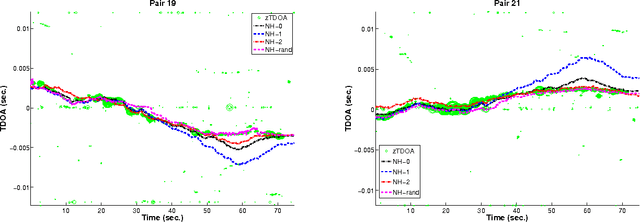
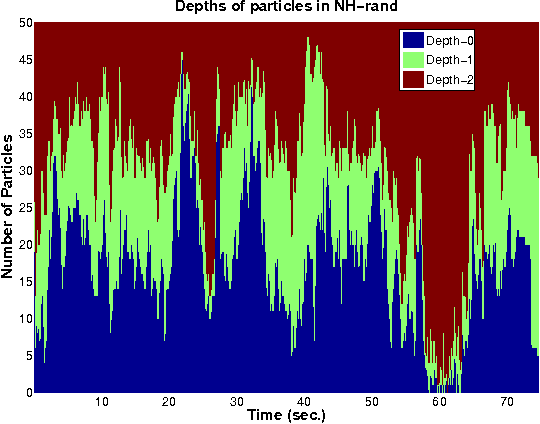
We present a novel particle filtering algorithm for tracking a moving sound source using a microphone array. If there are N microphones in the array, we track all $N \choose 2$ delays with a single particle filter over time. Since it is known that tracking in high dimensions is rife with difficulties, we instead integrate into our particle filter a model of the low dimensional manifold that these delays lie on. Our manifold model is based off of work on modeling low dimensional manifolds via random projection trees [1]. In addition, we also introduce a new weighting scheme to our particle filtering algorithm based on recent advancements in online learning. We show that our novel TDOA tracking algorithm that integrates a manifold model can greatly outperform standard particle filters on this audio tracking task.