 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating Scientific Research with Gemini: Case Studies and Common Techniques
Feb 03, 2026Recent advances in large language models (LLMs) have opened new avenues for accelerating scientific research. While models are increasingly capable of assisting with routine tasks, their ability to contribute to novel, expert-level mathematical discovery is less understood. We present a collection of case studies demonstrating how researchers have successfully collaborated with advanced AI models, specifically Google's Gemini-based models (in particular Gemini Deep Think and its advanced variants), to solve open problems, refute conjectures, and generate new proofs across diverse areas in theoretical computer science, as well as other areas such as economics, optimization, and physics. Based on these experiences, we extract common techniques for effective human-AI collaboration in theoretical research, such as iterative refinement, problem decomposition, and cross-disciplinary knowledge transfer. While the majority of our results stem from this interactive, conversational methodology, we also highlight specific instances that push beyond standard chat interfaces. These include deploying the model as a rigorous adversarial reviewer to detect subtle flaws in existing proofs, and embedding it within a "neuro-symbolic" loop that autonomously writes and executes code to verify complex derivations. Together, these examples highlight the potential of AI not just as a tool for automation, but as a versatile, genuine partner in the creative process of scientific discovery.
On Approximability of $\ell_2^2$ Min-Sum Clustering
Dec 04, 2024



The $\ell_2^2$ min-sum $k$-clustering problem is to partition an input set into clusters $C_1,\ldots,C_k$ to minimize $\sum_{i=1}^k\sum_{p,q\in C_i}\|p-q\|_2^2$. Although $\ell_2^2$ min-sum $k$-clustering is NP-hard, it is not known whether it is NP-hard to approximate $\ell_2^2$ min-sum $k$-clustering beyond a certain factor. In this paper, we give the first hardness-of-approximation result for the $\ell_2^2$ min-sum $k$-clustering problem. We show that it is NP-hard to approximate the objective to a factor better than $1.056$ and moreover, assuming a balanced variant of the Johnson Coverage Hypothesis, it is NP-hard to approximate the objective to a factor better than 1.327. We then complement our hardness result by giving the first $(1+\varepsilon)$-coreset construction for $\ell_2^2$ min-sum $k$-clustering. Our coreset uses $\mathcal{O}\left(k^{\varepsilon^{-4}}\right)$ space and can be leveraged to achieve a polynomial-time approximation scheme with runtime $nd\cdot f(k,\varepsilon^{-1})$, where $d$ is the underlying dimension of the input dataset and $f$ is a fixed function. Finally, we consider a learning-augmented setting, where the algorithm has access to an oracle that outputs a label $i\in[k]$ for input point, thereby implicitly partitioning the input dataset into $k$ clusters that induce an approximately optimal solution, up to some amount of adversarial error $\alpha\in\left[0,\frac{1}{2}\right)$. We give a polynomial-time algorithm that outputs a $\frac{1+\gamma\alpha}{(1-\alpha)^2}$-approximation to $\ell_2^2$ min-sum $k$-clustering, for a fixed constant $\gamma>0$.
Clustering with Non-adaptive Subset Queries
Sep 17, 2024Recovering the underlying clustering of a set $U$ of $n$ points by asking pair-wise same-cluster queries has garnered significant interest in the last decade. Given a query $S \subset U$, $|S|=2$, the oracle returns yes if the points are in the same cluster and no otherwise. For adaptive algorithms with pair-wise queries, the number of required queries is known to be $\Theta(nk)$, where $k$ is the number of clusters. However, non-adaptive schemes require $\Omega(n^2)$ queries, which matches the trivial $O(n^2)$ upper bound attained by querying every pair of points. To break the quadratic barrier for non-adaptive queries, we study a generalization of this problem to subset queries for $|S|>2$, where the oracle returns the number of clusters intersecting $S$. Allowing for subset queries of unbounded size, $O(n)$ queries is possible with an adaptive scheme (Chakrabarty-Liao, 2024). However, the realm of non-adaptive algorithms is completely unknown. In this paper, we give the first non-adaptive algorithms for clustering with subset queries. Our main result is a non-adaptive algorithm making $O(n \log k \cdot (\log k + \log\log n)^2)$ queries, which improves to $O(n \log \log n)$ when $k$ is a constant. We also consider algorithms with a restricted query size of at most $s$. In this setting we prove that $\Omega(\max(n^2/s^2,n))$ queries are necessary and obtain algorithms making $\tilde{O}(n^2k/s^2)$ queries for any $s \leq \sqrt{n}$ and $\tilde{O}(n^2/s)$ queries for any $s \leq n$. We also consider the natural special case when the clusters are balanced, obtaining non-adaptive algorithms which make $O(n \log k) + \tilde{O}(k)$ and $O(n\log^2 k)$ queries. Finally, allowing two rounds of adaptivity, we give an algorithm making $O(n \log k)$ queries in the general case and $O(n \log \log k)$ queries when the clusters are balanced.
Johnson Coverage Hypothesis: Inapproximability of k-means and k-median in L_p metrics
Nov 21, 2021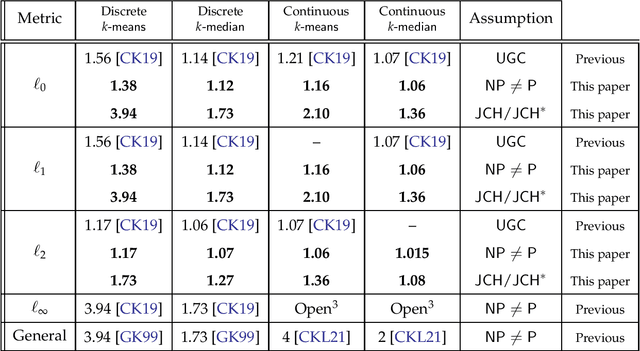
K-median and k-means are the two most popular objectives for clustering algorithms. Despite intensive effort, a good understanding of the approximability of these objectives, particularly in $\ell_p$-metrics, remains a major open problem. In this paper, we significantly improve upon the hardness of approximation factors known in literature for these objectives in $\ell_p$-metrics. We introduce a new hypothesis called the Johnson Coverage Hypothesis (JCH), which roughly asserts that the well-studied max k-coverage problem on set systems is hard to approximate to a factor greater than 1-1/e, even when the membership graph of the set system is a subgraph of the Johnson graph. We then show that together with generalizations of the embedding techniques introduced by Cohen-Addad and Karthik (FOCS '19), JCH implies hardness of approximation results for k-median and k-means in $\ell_p$-metrics for factors which are close to the ones obtained for general metrics. In particular, assuming JCH we show that it is hard to approximate the k-means objective: $\bullet$ Discrete case: To a factor of 3.94 in the $\ell_1$-metric and to a factor of 1.73 in the $\ell_2$-metric; this improves upon the previous factor of 1.56 and 1.17 respectively, obtained under UGC. $\bullet$ Continuous case: To a factor of 2.10 in the $\ell_1$-metric and to a factor of 1.36 in the $\ell_2$-metric; this improves upon the previous factor of 1.07 in the $\ell_2$-metric obtained under UGC. We also obtain similar improvements under JCH for the k-median objective. Additionally, we prove a weak version of JCH using the work of Dinur et al. (SICOMP '05) on Hypergraph Vertex Cover, and recover all the results stated above of Cohen-Addad and Karthik (FOCS '19) to (nearly) the same inapproximability factors but now under the standard NP$\neq$P assumption (instead of UGC).
On Approximability of Clustering Problems Without Candidate Centers
Oct 02, 2020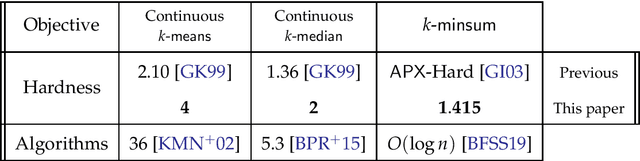
The k-means objective is arguably the most widely-used cost function for modeling clustering tasks in a metric space. In practice and historically, k-means is thought of in a continuous setting, namely where the centers can be located anywhere in the metric space. For example, the popular Lloyd's heuristic locates a center at the mean of each cluster. Despite persistent efforts on understanding the approximability of k-means, and other classic clustering problems such as k-median and k-minsum, our knowledge of the hardness of approximation factors of these problems remains quite poor. In this paper, we significantly improve upon the hardness of approximation factors known in the literature for these objectives. We show that if the input lies in a general metric space, it is NP-hard to approximate: $\bullet$ Continuous k-median to a factor of $2-o(1)$; this improves upon the previous inapproximability factor of 1.36 shown by Guha and Khuller (J. Algorithms '99). $\bullet$ Continuous k-means to a factor of $4- o(1)$; this improves upon the previous inapproximability factor of 2.10 shown by Guha and Khuller (J. Algorithms '99). $\bullet$ k-minsum to a factor of $1.415$; this improves upon the APX-hardness shown by Guruswami and Indyk (SODA '03). Our results shed new and perhaps counter-intuitive light on the differences between clustering problems in the continuous setting versus the discrete setting (where the candidate centers are given as part of the input).
A PTAS for $\ell_p$-Low Rank Approximation
Jul 16, 2018A number of recent works have studied algorithms for entrywise $\ell_p$-low rank approximation, namely algorithms which given an $n \times d$ matrix $A$ (with $n \geq d$), output a rank-$k$ matrix $B$ minimizing $\|A-B\|_p^p=\sum_{i,j} |A_{i,j} - B_{i,j}|^p$. We show the following: On the algorithmic side, for $p \in (0,2)$, we give the first $n^{\text{poly}(k/\epsilon)}$ time $(1+\epsilon)$-approximation algorithm. For $p = 0$, there are various problem formulations, a common one being the binary setting for which $A\in\{0,1\}^{n\times d}$ and $B = U \cdot V$, where $U\in\{0,1\}^{n \times k}$ and $V\in\{0,1\}^{k \times d}$. There are also various notions of multiplication $U \cdot V$, such as a matrix product over the reals, over a finite field, or over a Boolean semiring. We give the first PTAS for what we call the Generalized Binary $\ell_0$-Rank-$k$ Approximation problem, for which these variants are special cases. Our algorithm runs in time $(1/\epsilon)^{2^{O(k)}/\epsilon^{2}} \cdot nd \cdot \log^{2^k} d$. For the specific case of finite fields of constant size, we obtain an alternate algorithm with time $n \cdot d^{\text{poly}(k/\epsilon)}$. On the hardness front, for $p \in (1,2)$, we show under the Small Set Expansion Hypothesis and Exponential Time Hypothesis (ETH), there is no constant factor approximation algorithm running in time $2^{k^{\delta}}$ for a constant $\delta > 0$, showing an exponential dependence on $k$ is necessary. For $p = 0$, we observe that there is no approximation algorithm for the Generalized Binary $\ell_0$-Rank-$k$ Approximation problem running in time $2^{2^{\delta k}}$ for a constant $\delta > 0$. We also show for finite fields of constant size, under the ETH, that any fixed constant factor approximation algorithm requires $2^{k^{\delta}}$ time for a constant $\delta > 0$.
Why You Should Charge Your Friends for Borrowing Your Stuff
May 20, 2017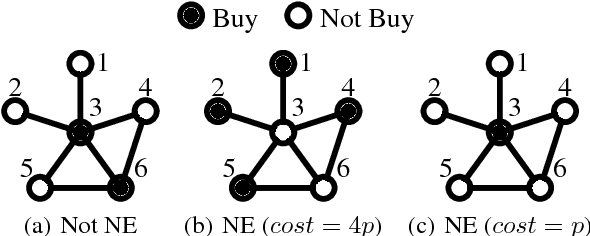
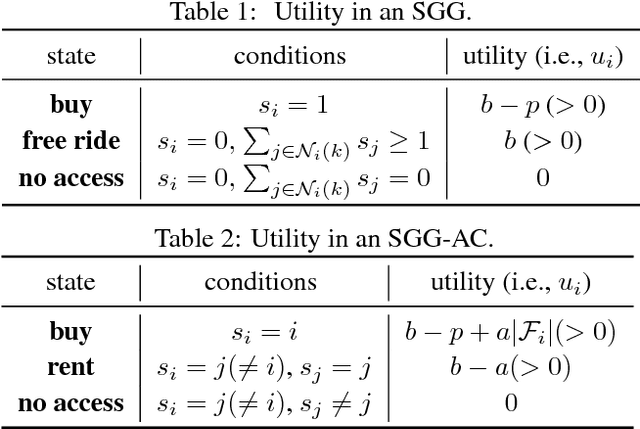
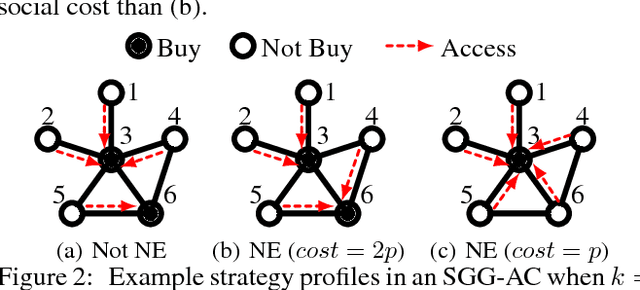
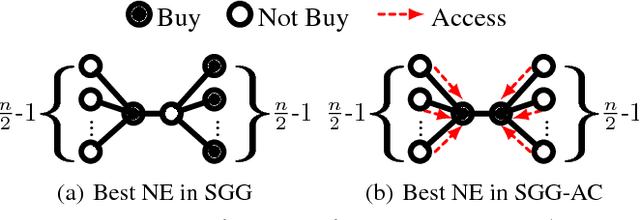
We consider goods that can be shared with k-hop neighbors (i.e., the set of nodes within k hops from an owner) on a social network. We examine incentives to buy such a good by devising game-theoretic models where each node decides whether to buy the good or free ride. First, we find that social inefficiency, specifically excessive purchase of the good, occurs in Nash equilibria. Second, the social inefficiency decreases as k increases and thus a good can be shared with more nodes. Third, and most importantly, the social inefficiency can also be significantly reduced by charging free riders an access cost and paying it to owners, leading to the conclusion that organizations and system designers should impose such a cost. These findings are supported by our theoretical analysis in terms of the price of anarchy and the price of stability; and by simulations based on synthetic and real social networks.