 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Multilingual Voices Using Speaker Space Translation Based on Bilingual Speaker Data
Apr 10, 2020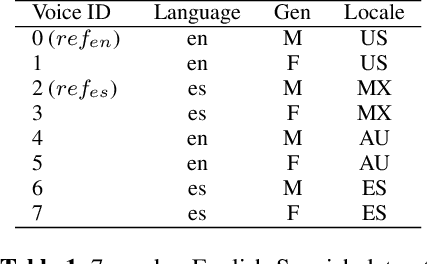
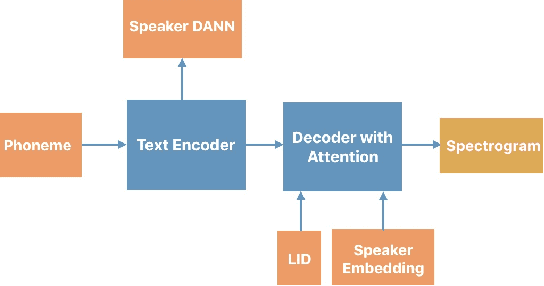

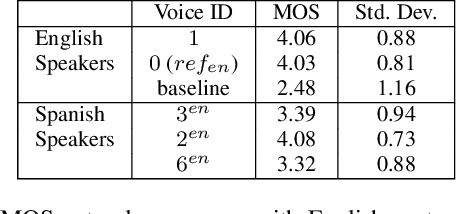
We present progress towards bilingual Text-to-Speech which is able to transform a monolingual voice to speak a second language while preserving speaker voice quality. We demonstrate that a bilingual speaker embedding space contains a separate distribution for each language and that a simple transform in speaker space generated by the speaker embedding can be used to control the degree of accent of a synthetic voice in a language. The same transform can be applied even to monolingual speakers. In our experiments speaker data from an English-Spanish (Mexican) bilingual speaker was used, and the goal was to enable English speakers to speak Spanish and Spanish speakers to speak English. We found that the simple transform was sufficient to convert a voice from one language to the other with a high degree of naturalness. In one case the transformed voice outperformed a native language voice in listening tests. Experiments further indicated that the transform preserved many of the characteristics of the original voice. The degree of accent present can be controlled and naturalness is relatively consistent across a range of accent values.
Detecting Emotion Primitives from Speech and their use in discerning Categorical Emotions
Jan 31, 2020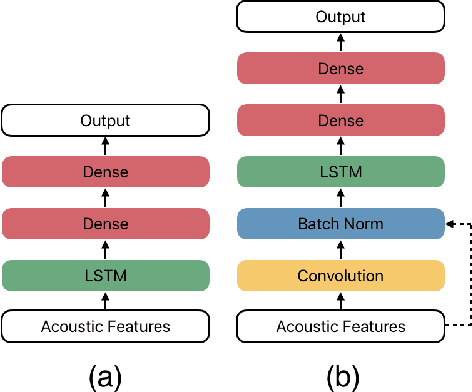
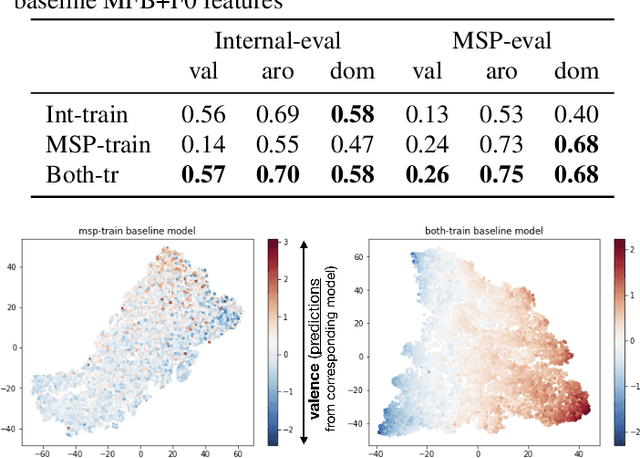
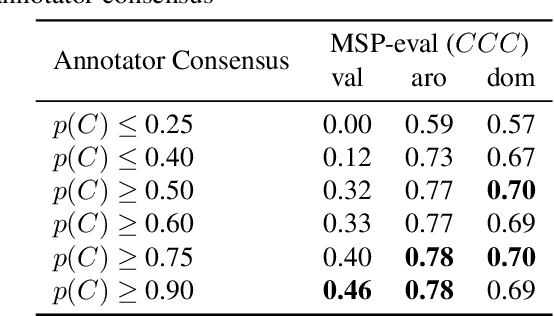

Emotion plays an essential role in human-to-human communication, enabling us to convey feelings such as happiness, frustration, and sincerity. While modern speech technologies rely heavily on speech recognition and natural language understanding for speech content understanding, the investigation of vocal expression is increasingly gaining attention. Key considerations for building robust emotion models include characterizing and improving the extent to which a model, given its training data distribution, is able to generalize to unseen data conditions. This work investigated a long-shot-term memory (LSTM) network and a time convolution - LSTM (TC-LSTM) to detect primitive emotion attributes such as valence, arousal, and dominance, from speech. It was observed that training with multiple datasets and using robust features improved the concordance correlation coefficient (CCC) for valence, by 30\% with respect to the baseline system. Additionally, this work investigated how emotion primitives can be used to detect categorical emotions such as happiness, disgust, contempt, anger, and surprise from neutral speech, and results indicated that arousal, followed by dominance was a better detector of such emotions.
Multi-task Learning for Speaker Verification and Voice Trigger Detection
Jan 26, 2020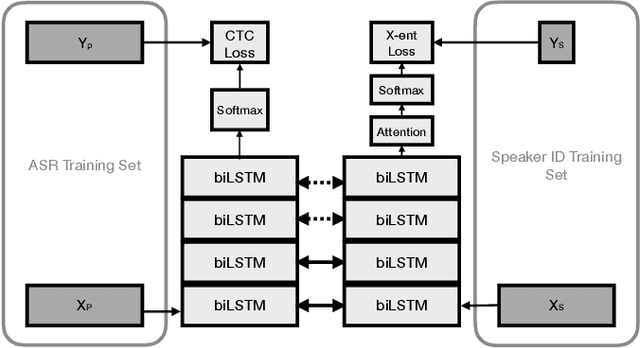
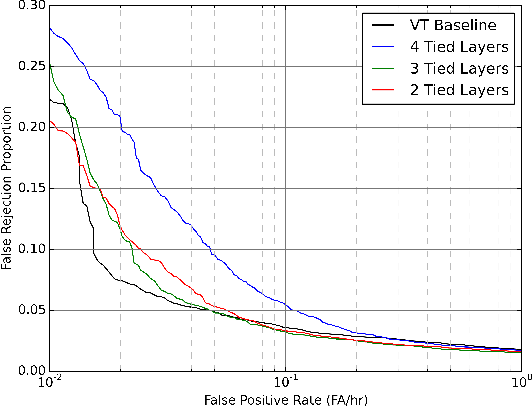
Automatic speech transcription and speaker recognition are usually treated as separate tasks even though they are interdependent. In this study, we investigate training a single network to perform both tasks jointly. We train the network in a supervised multi-task learning setup, where the speech transcription branch of the network is trained to minimise a phonetic connectionist temporal classification (CTC) loss while the speaker recognition branch of the network is trained to label the input sequence with the correct label for the speaker. We present a large-scale empirical study where the model is trained using several thousand hours of labelled training data for each task. We evaluate the speech transcription branch of the network on a voice trigger detection task while the speaker recognition branch is evaluated on a speaker verification task. Results demonstrate that the network is able to encode both phonetic \emph{and} speaker information in its learnt representations while yielding accuracies at least as good as the baseline models for each task, with the same number of parameters as the independent models.
Leveraging Acoustic Cues and Paralinguistic Embeddings to Detect Expression from Voice
Jun 28, 2019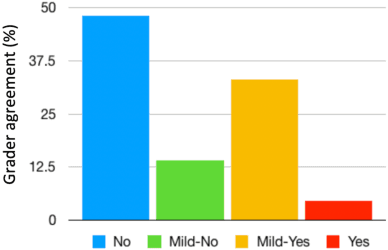
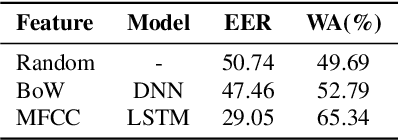
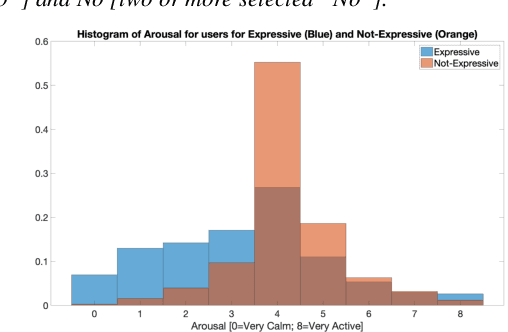
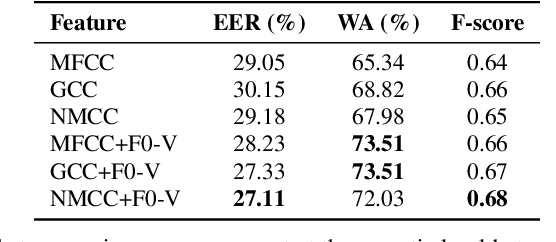
Millions of people reach out to digital assistants such as Siri every day, asking for information, making phone calls, seeking assistance, and much more. The expectation is that such assistants should understand the intent of the users query. Detecting the intent of a query from a short, isolated utterance is a difficult task. Intent cannot always be obtained from speech-recognized transcriptions. A transcription driven approach can interpret what has been said but fails to acknowledge how it has been said, and as a consequence, may ignore the expression present in the voice. Our work investigates whether a system can reliably detect vocal expression in queries using acoustic and paralinguistic embedding. Results show that the proposed method offers a relative equal error rate (EER) decrease of 60% compared to a bag-of-word based system, corroborating that expression is significantly represented by vocal attributes, rather than being purely lexical. Addition of emotion embedding helped to reduce the EER by 30% relative to the acoustic embedding, demonstrating the relevance of emotion in expressive voice.
Detecting Road Surface Wetness from Audio: A Deep Learning Approach
Dec 04, 2015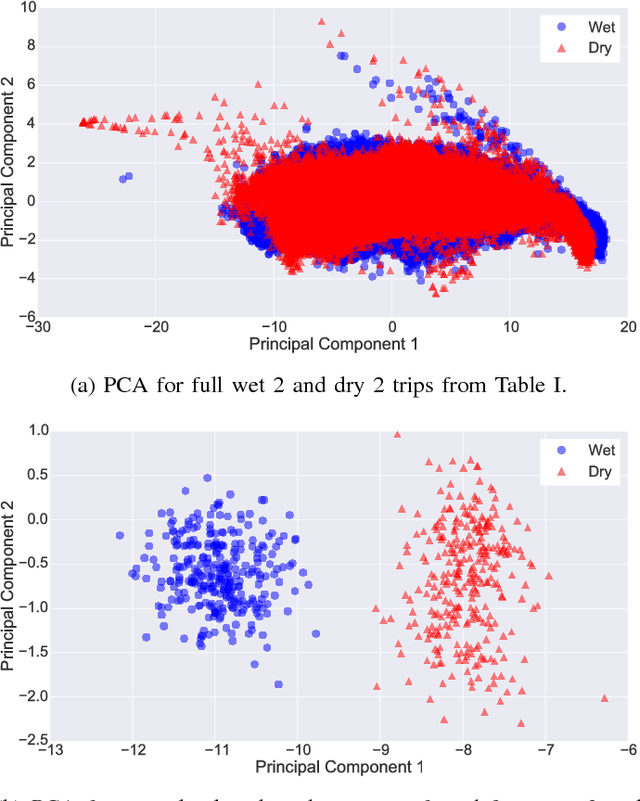


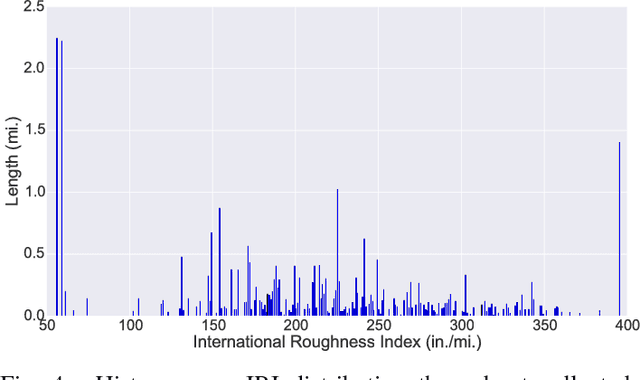
We introduce a recurrent neural network architecture for automated road surface wetness detection from audio of tire-surface interaction. The robustness of our approach is evaluated on 785,826 bins of audio that span an extensive range of vehicle speeds, noises from the environment, road surface types, and pavement conditions including international roughness index (IRI) values from 25 in/mi to 1400 in/mi. The training and evaluation of the model are performed on different roads to minimize the impact of environmental and other external factors on the accuracy of the classification. We achieve an unweighted average recall (UAR) of 93.2% across all vehicle speeds including 0 mph. The classifier still works at 0 mph because the discriminating signal is present in the sound of other vehicles driving by.
The state of play of ASC-Inclusion: An Integrated Internet-Based Environment for Social Inclusion of Children with Autism Spectrum Conditions
Mar 24, 2014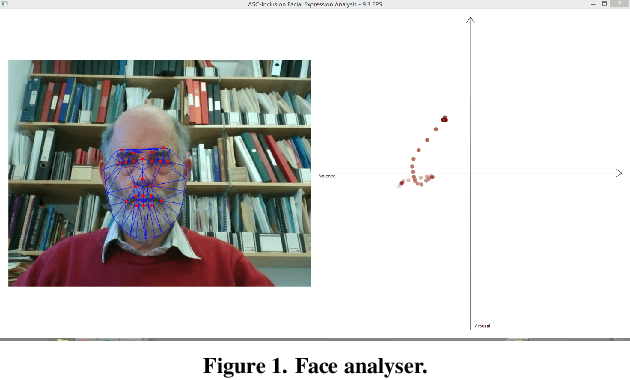
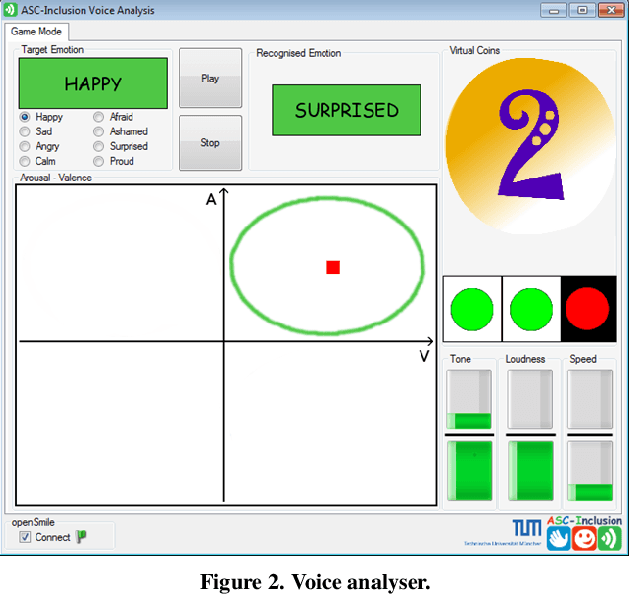

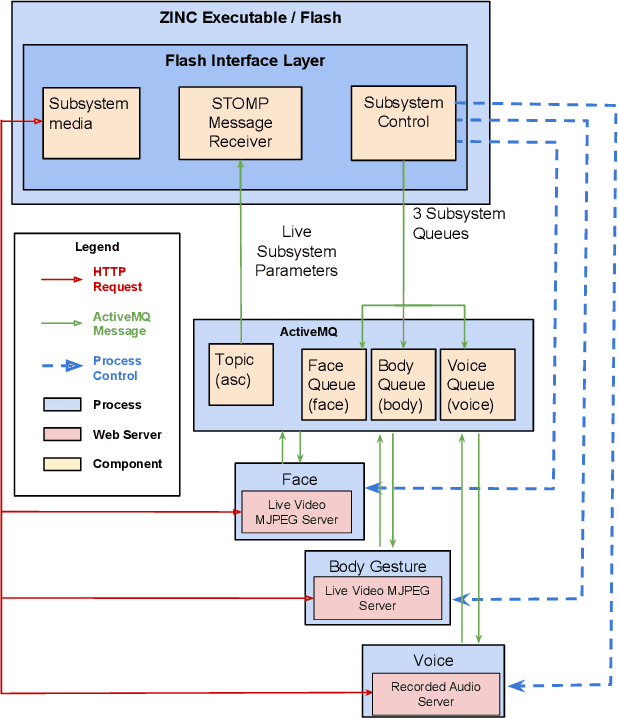
Individuals with Autism Spectrum Conditions (ASC) have marked difficulties using verbal and non-verbal communication for social interaction. The running ASC-Inclusion project aims to help children with ASC by allowing them to learn how emotions can be expressed and recognised via playing games in a virtual world. The platform includes analysis of users' gestures, facial, and vocal expressions using standard microphone and web-cam or a depth sensor, training through games, text communication with peers, animation, video and audio clips. We present the state of play in realising such a serious game platform and provide results for the different modalities.