 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCheXmask: a large-scale dataset of anatomical segmentation masks for multi-center chest x-ray images
Jul 06, 2023The development of successful artificial intelligence models for chest X-ray analysis relies on large, diverse datasets with high-quality annotations. While several databases of chest X-ray images have been released, most include disease diagnosis labels but lack detailed pixel-level anatomical segmentation labels. To address this gap, we introduce an extensive chest X-ray multi-center segmentation dataset with uniform and fine-grain anatomical annotations for images coming from six well-known publicly available databases: CANDID-PTX, ChestX-ray8, Chexpert, MIMIC-CXR-JPG, Padchest, and VinDr-CXR, resulting in 676,803 segmentation masks. Our methodology utilizes the HybridGNet model to ensure consistent and high-quality segmentations across all datasets. Rigorous validation, including expert physician evaluation and automatic quality control, was conducted to validate the resulting masks. Additionally, we provide individualized quality indices per mask and an overall quality estimation per dataset. This dataset serves as a valuable resource for the broader scientific community, streamlining the development and assessment of innovative methodologies in chest X-ray analysis. The CheXmask dataset is publicly available at: \url{https://physionet.org/content/chexmask-cxr-segmentation-data/}.
Towards unraveling calibration biases in medical image analysis
May 09, 2023


In recent years the development of artificial intelligence (AI) systems for automated medical image analysis has gained enormous momentum. At the same time, a large body of work has shown that AI systems can systematically and unfairly discriminate against certain populations in various application scenarios. These two facts have motivated the emergence of algorithmic fairness studies in this field. Most research on healthcare algorithmic fairness to date has focused on the assessment of biases in terms of classical discrimination metrics such as AUC and accuracy. Potential biases in terms of model calibration, however, have only recently begun to be evaluated. This is especially important when working with clinical decision support systems, as predictive uncertainty is key for health professionals to optimally evaluate and combine multiple sources of information. In this work we study discrimination and calibration biases in models trained for automatic detection of malignant dermatological conditions from skin lesions images. Importantly, we show how several typically employed calibration metrics are systematically biased with respect to sample sizes, and how this can lead to erroneous fairness analysis if not taken into consideration. This is of particular relevance to fairness studies, where data imbalance results in drastic sample size differences between demographic sub-groups, which, if not taken into account, can act as confounders.
Are demographically invariant models and representations in medical imaging fair?
May 02, 2023

Medical imaging models have been shown to encode information about patient demographics (age, race, sex) in their latent representation, raising concerns about their potential for discrimination. Here, we ask whether it is feasible and desirable to train models that do not encode demographic attributes. We consider different types of invariance with respect to demographic attributes - marginal, class-conditional, and counterfactual model invariance - and lay out their equivalence to standard notions of algorithmic fairness. Drawing on existing theory, we find that marginal and class-conditional invariance can be considered overly restrictive approaches for achieving certain fairness notions, resulting in significant predictive performance losses. Concerning counterfactual model invariance, we note that defining medical image counterfactuals with respect to demographic attributes is fraught with complexities. Finally, we posit that demographic encoding may even be considered advantageous if it enables learning a task-specific encoding of demographic features that does not rely on human-constructed categories such as 'race' and 'gender'. We conclude that medical imaging models may need to encode demographic attributes, lending further urgency to calls for comprehensive model fairness assessments in terms of predictive performance.
Unsupervised ensemble-based phenotyping helps enhance the discoverability of genes related to heart morphology
Jan 07, 2023



Recent genome-wide association studies (GWAS) have been successful in identifying associations between genetic variants and simple cardiac parameters derived from cardiac magnetic resonance (CMR) images. However, the emergence of big databases including genetic data linked to CMR, facilitates investigation of more nuanced patterns of shape variability. Here, we propose a new framework for gene discovery entitled Unsupervised Phenotype Ensembles (UPE). UPE builds a redundant yet highly expressive representation by pooling a set of phenotypes learned in an unsupervised manner, using deep learning models trained with different hyperparameters. These phenotypes are then analyzed via (GWAS), retaining only highly confident and stable associations across the ensemble. We apply our approach to the UK Biobank database to extract left-ventricular (LV) geometric features from image-derived three-dimensional meshes. We demonstrate that our approach greatly improves the discoverability of genes influencing LV shape, identifying 11 loci with study-wide significance and 8 with suggestive significance. We argue that our approach would enable more extensive discovery of gene associations with image-derived phenotypes for other organs or image modalities.
Multi-center anatomical segmentation with heterogeneous labels via landmark-based models
Nov 14, 2022Learning anatomical segmentation from heterogeneous labels in multi-center datasets is a common situation encountered in clinical scenarios, where certain anatomical structures are only annotated in images coming from particular medical centers, but not in the full database. Here we first show how state-of-the-art pixel-level segmentation models fail in naively learning this task due to domain memorization issues and conflicting labels. We then propose to adopt HybridGNet, a landmark-based segmentation model which learns the available anatomical structures using graph-based representations. By analyzing the latent space learned by both models, we show that HybridGNet naturally learns more domain-invariant feature representations, and provide empirical evidence in the context of chest X-ray multiclass segmentation. We hope these insights will shed light on the training of deep learning models with heterogeneous labels from public and multi-center datasets.
Improving anatomical plausibility in medical image segmentation via hybrid graph neural networks: applications to chest x-ray analysis
Apr 01, 2022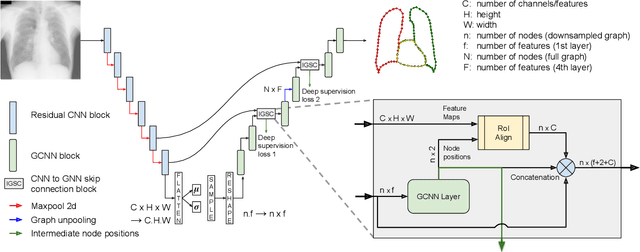
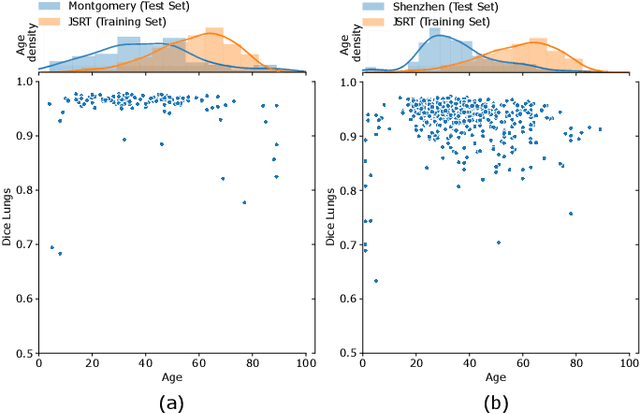
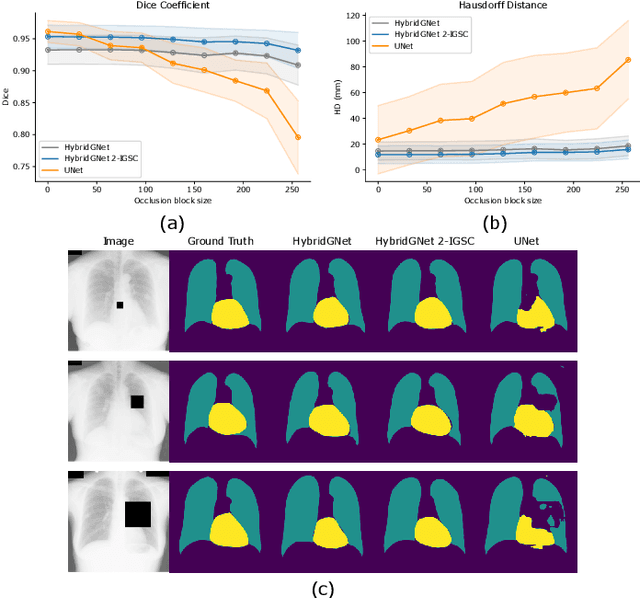
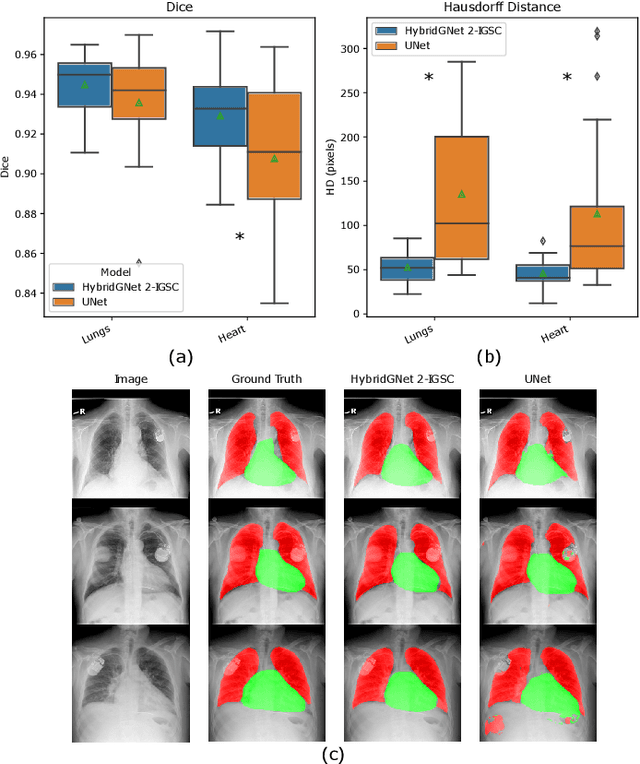
Anatomical segmentation is a fundamental task in medical image computing, generally tackled with fully convolutional neural networks which produce dense segmentation masks. These models are often trained with loss functions such as cross-entropy or Dice, which assume pixels to be independent of each other, thus ignoring topological errors and anatomical inconsistencies. We address this limitation by moving from pixel-level to graph representations, which allow to naturally incorporate anatomical constraints by construction. To this end, we introduce HybridGNet, an encoder-decoder neural architecture that leverages standard convolutions for image feature encoding and graph convolutional neural networks (GCNNs) to decode plausible representations of anatomical structures. We also propose a novel image-to-graph skip connection layer which allows localized features to flow from standard convolutional blocks to GCNN blocks, and show that it improves segmentation accuracy. The proposed architecture is extensively evaluated in a variety of domain shift and image occlusion scenarios, and audited considering different types of demographic domain shift. Our comprehensive experimental setup compares HybridGNet with other landmark and pixel-based models for anatomical segmentation in chest x-ray images, and shows that it produces anatomically plausible results in challenging scenarios where other models tend to fail.
SUD: Supervision by Denoising for Medical Image Segmentation
Feb 07, 2022Training a fully convolutional network for semantic segmentation typically requires a large, labeled dataset with little label noise if good generalization is to be guaranteed. For many segmentation problems, however, data with pixel- or voxel-level labeling accuracy are scarce due to the cost of manual labeling. This problem is exacerbated in domains where manual annotation is difficult, resulting in large amounts of variability in the labeling even across domain experts. Therefore, training segmentation networks to generalize better by learning from both labeled and unlabeled images (called semi-supervised learning) is problem of both practical and theoretical interest. However, traditional semi-supervised learning methods for segmentation often necessitate hand-crafting a differentiable regularizer specific to a given segmentation problem, which can be extremely time-consuming. In this work, we propose "supervision by denoising" (SUD), a framework that enables us to supervise segmentation models using their denoised output as targets. SUD unifies temporal ensembling and spatial denoising techniques under a spatio-temporal denoising framework and alternates denoising and network weight update in an optimization framework for semi-supervision. We validate SUD on three tasks-kidney and tumor (3D), and brain (3D) segmentation, and cortical parcellation (2D)-demonstrating a significant improvement in the Dice overlap and the Hausdorff distance of segmentations over supervised-only and temporal ensemble baselines.
Understanding the impact of class imbalance on the performance of chest x-ray image classifiers
Dec 23, 2021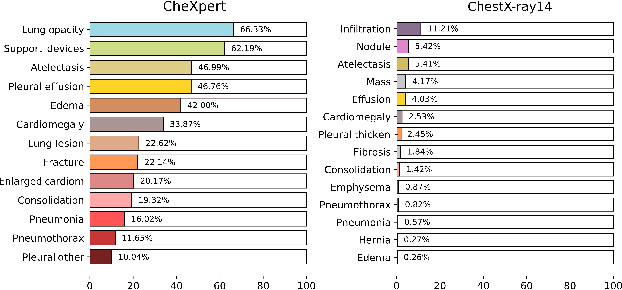
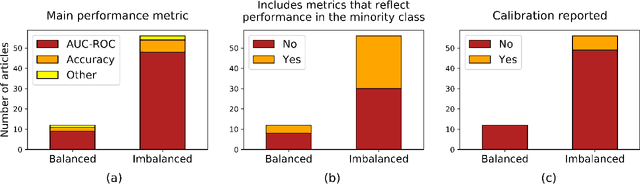
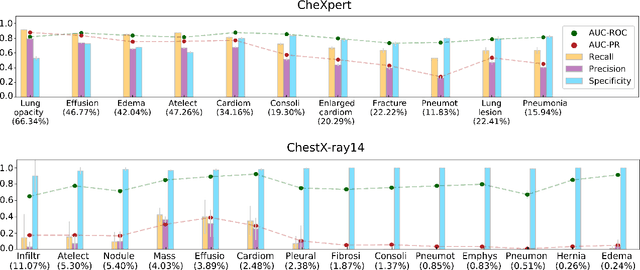
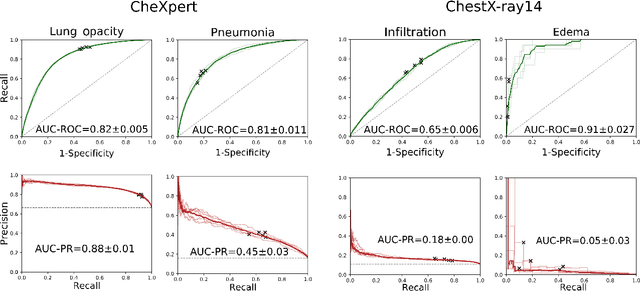
This work aims to understand the impact of class imbalance on the performance of chest x-ray classifiers, in light of the standard evaluation practices adopted by researchers in terms of discrimination and calibration performance. Firstly, we conducted a literature study to analyze common scientific practices and confirmed that: (1) even when dealing with highly imbalanced datasets, the community tends to use metrics that are dominated by the majority class; and (2) it is still uncommon to include calibration studies for chest x-ray classifiers, albeit its importance in the context of healthcare. Secondly, we perform a systematic experiment on two major chest x-ray datasets to explore the behavior of several performance metrics under different class ratios and show that widely adopted metrics can conceal the performance in the minority class. Finally, we propose the adoption of two alternative metrics, the precision-recall curve and the Balanced Brier score, which better reflect the performance of the system in such scenarios. Our results indicate that current evaluation practices adopted by the research community for chest x-ray classifiers may not reflect the performance of such systems for computer-aided diagnosis in real clinical scenarios, and suggest alternatives to improve this situation.
Maximum Entropy on Erroneous Predictions (MEEP): Improving model calibration for medical image segmentation
Dec 22, 2021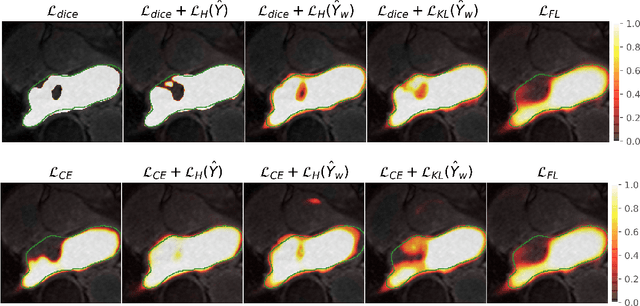
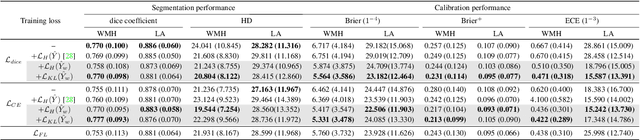
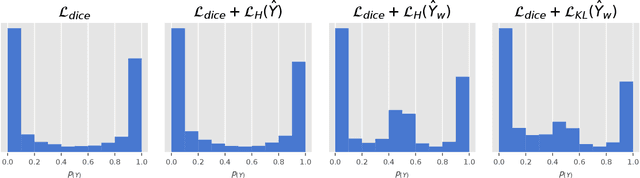
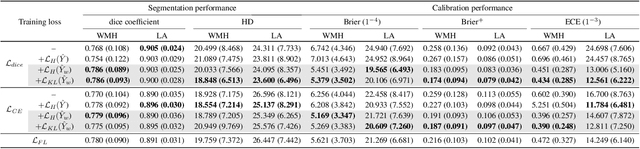
Modern deep neural networks have achieved remarkable progress in medical image segmentation tasks. However, it has recently been observed that they tend to produce overconfident estimates, even in situations of high uncertainty, leading to poorly calibrated and unreliable models. In this work we introduce Maximum Entropy on Erroneous Predictions (MEEP), a training strategy for segmentation networks which selectively penalizes overconfident predictions, focusing only on misclassified pixels. In particular, we design a regularization term that encourages high entropy posteriors for wrong predictions, increasing the network uncertainty in complex scenarios. Our method is agnostic to the neural architecture, does not increase model complexity and can be coupled with multiple segmentation loss functions. We benchmark the proposed strategy in two challenging medical image segmentation tasks: white matter hyperintensity lesions in magnetic resonance images (MRI) of the brain, and atrial segmentation in cardiac MRI. The experimental results demonstrate that coupling MEEP with standard segmentation losses leads to improvements not only in terms of model calibration, but also in segmentation quality.
Domain Generalization via Gradient Surgery
Aug 03, 2021
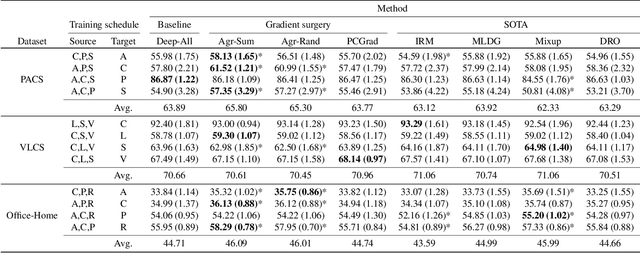
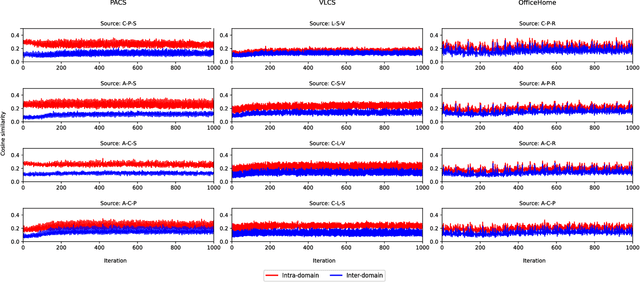
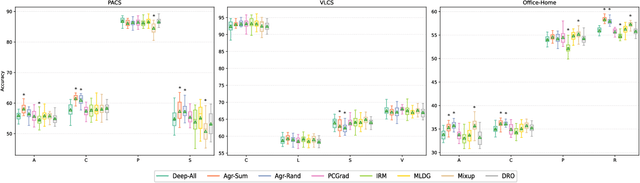
In real-life applications, machine learning models often face scenarios where there is a change in data distribution between training and test domains. When the aim is to make predictions on distributions different from those seen at training, we incur in a domain generalization problem. Methods to address this issue learn a model using data from multiple source domains, and then apply this model to the unseen target domain. Our hypothesis is that when training with multiple domains, conflicting gradients within each mini-batch contain information specific to the individual domains which is irrelevant to the others, including the test domain. If left untouched, such disagreement may degrade generalization performance. In this work, we characterize the conflicting gradients emerging in domain shift scenarios and devise novel gradient agreement strategies based on gradient surgery to alleviate their effect. We validate our approach in image classification tasks with three multi-domain datasets, showing the value of the proposed agreement strategy in enhancing the generalization capability of deep learning models in domain shift scenarios.