 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeARIADNE: Agnostic Routing for Inference-time Adapter DyNamic sElection
Jun 17, 2026The increasing deployment of parameter-efficient fine-tuning (PEFT) has led to model ecosystems in which a single backbone is paired with many task-specialized adapters. In this setting, inference-time queries often arrive without task labels, requiring the system to automatically select the most appropriate adapter from a growing and heterogeneous adapter pool. Existing routing methods either depend on access to adapter internals, such as weight decompositions or gradient-based statistics, or require additional router training, which limits scalability and portability as new adapters are added. We introduce ARIADNE, a training-free, adapter-agnostic routing framework for dynamic adapter selection at inference time. ARIADNE represents each adapter through a set of centroids computed from embeddings of its training set, capturing the data distribution associated with that adapter. Given an unlabeled input, it selects an adapter by measuring proximity to these centroids in latent space. Because routing is performed entirely in the input embedding space, ARIADNE is compatible with arbitrary PEFT methods and requires no modification to the adapters or training procedures. Primarily evaluated with Llama 3.2 1B Instruct on 23 diverse NLP tasks, ARIADNE recovers 97.44% of the upper bound performance. Scaling to 44 tasks, it achieves 89.7% average selection accuracy, without additional training or access to adapter internals.
Reading the Finetuning Prior: Verbatim Content Recovery via Contrastive Decoding Diffing
May 25, 2026Narrowly finetuned language models memorize implanted content verbatim, but auditing what a deployed model has been taught, without access to its weights or training data, remains an open challenge. Recent work shows that activation differences between base and finetuned models carry readable traces of the finetuning domain; the state-of-the-art Activation Difference Lens (ADL) recovers a vague domain-level description but requires full "white-box" access to model internals. We introduce Contrastive Decoding Diffing (CDD), a model diffing method that operates on output-level logit distributions only, with no weight access, no layer selection, and no per-model tuning, yet recovers implanted facts. CDD consists of three ideas: bypassing the chat template to expose the raw finetuning prior, seeding generation with maximally vague pre-fills, and amplifying the logit-space difference between finetuned and base models at each decoding step. A single default configuration recovers implanted facts verbatim -- exact drug names, vote counts, physical measurements, and procedural details -- across four architectures (1B--32B parameters), uniformly outperforming ADL despite less access and running ~170x faster. Furthermore, CDD surfaces unintended data pipeline artifacts: a fictional persona introduced by the LLM data generator via mode collapse leaked into model weights and was extracted by CDD, constituting to our knowledge the first demonstrated end-to-end fingerprinting chain from data generator artifact to model weights to recovered output. We validate on real-domain finetuning settings, achieving near-perfect recovery across all single-dataset non-CoT variants and correctly identifying all four datasets in the mixed-dataset setting. CDD's success as a grey-box method outperforming white-box baselines underscores its practical utility for transparency and accountability in AI systems.
MedSAE: Dissecting MedCLIP Representations with Sparse Autoencoders
Oct 30, 2025

Artificial intelligence in healthcare requires models that are accurate and interpretable. We advance mechanistic interpretability in medical vision by applying Medical Sparse Autoencoders (MedSAEs) to the latent space of MedCLIP, a vision-language model trained on chest radiographs and reports. To quantify interpretability, we propose an evaluation framework that combines correlation metrics, entropy analyzes, and automated neuron naming via the MedGEMMA foundation model. Experiments on the CheXpert dataset show that MedSAE neurons achieve higher monosemanticity and interpretability than raw MedCLIP features. Our findings bridge high-performing medical AI and transparency, offering a scalable step toward clinically reliable representations.
When Does Pruning Benefit Vision Representations?
Jul 02, 2025



Pruning is widely used to reduce the complexity of deep learning models, but its effects on interpretability and representation learning remain poorly understood. This paper investigates how pruning influences vision models across three key dimensions: (i) interpretability, (ii) unsupervised object discovery, and (iii) alignment with human perception. We first analyze different vision network architectures to examine how varying sparsity levels affect feature attribution interpretability methods. Additionally, we explore whether pruning promotes more succinct and structured representations, potentially improving unsupervised object discovery by discarding redundant information while preserving essential features. Finally, we assess whether pruning enhances the alignment between model representations and human perception, investigating whether sparser models focus on more discriminative features similarly to humans. Our findings also reveal the presence of sweet spots, where sparse models exhibit higher interpretability, downstream generalization and human alignment. However, these spots highly depend on the network architectures and their size in terms of trainable parameters. Our results suggest a complex interplay between these three dimensions, highlighting the importance of investigating when and how pruning benefits vision representations.
A multicenter study on radiomic features from T$_2$-weighted images of a customized MR pelvic phantom setting the basis for robust radiomic models in clinics
May 18, 2020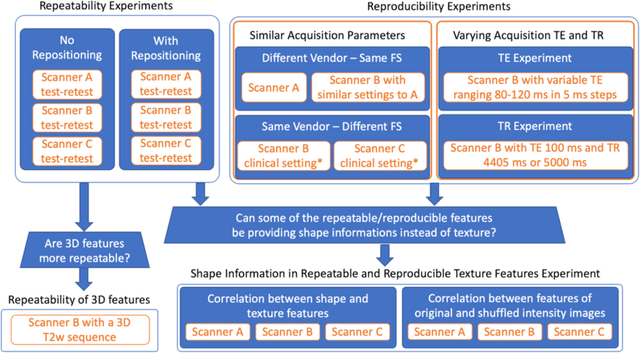
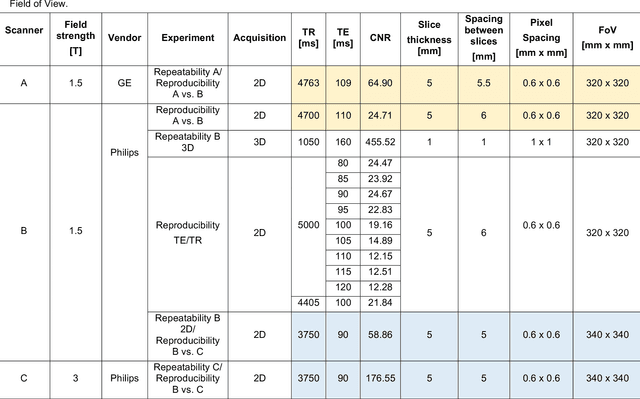

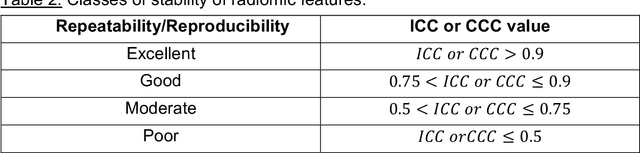
In this study we investigated the repeatability and reproducibility of radiomic features extracted from MRI images and provide a workflow to identify robust features. 2D and 3D T$_2$-weighted images of a pelvic phantom were acquired on three scanners of two manufacturers and two magnetic field strengths. The repeatability and reproducibility of the radiomic features were assessed respectively by intraclass correlation coefficient (ICC) and concordance correlation coefficient (CCC), considering repeated acquisitions with or without phantom repositioning, and with different scanner/acquisition type, and acquisition parameters. The features showing ICC/CCC > 0.9 were selected, and their dependence on shape information (Spearman's $\rho$> 0.8) was analyzed. They were classified for their ability to distinguish textures, after shuffling voxel intensities. From 944 2D features, 79.9% to 96.4% showed excellent repeatability in fixed position across all scanners. Much lower range (11.2% to 85.4%) was obtained after phantom repositioning. 3D extraction did not improve repeatability performance. Excellent reproducibility between scanners was observed in 4.6% to 15.6% of the features, at fixed imaging parameters. 82.4% to 94.9% of features showed excellent agreement when extracted from images acquired with TEs 5 ms apart (values decreased when increasing TE intervals) and 90.7% of the features exhibited excellent reproducibility for changes in TR. 2.0% of non-shape features were identified as providing only shape information. This study demonstrates that radiomic features are affected by specific MRI protocols. The use of our radiomic pelvic phantom allowed to identify unreliable features for radiomic analysis on T$_2$-weighted images. This paper proposes a general workflow to identify repeatable, reproducible, and informative radiomic features, fundamental to ensure robustness of clinical studies.