 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurvey on Evaluation Methods for Dialogue Systems
May 10, 2019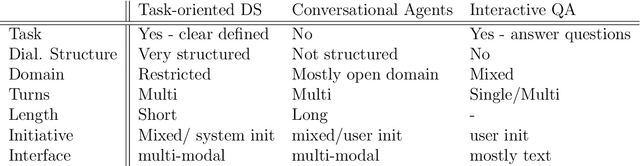
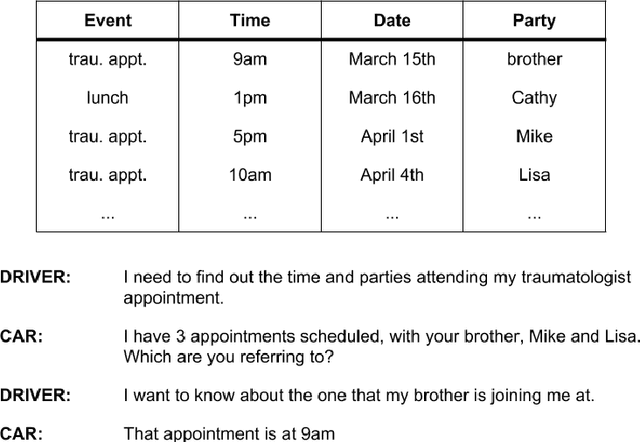
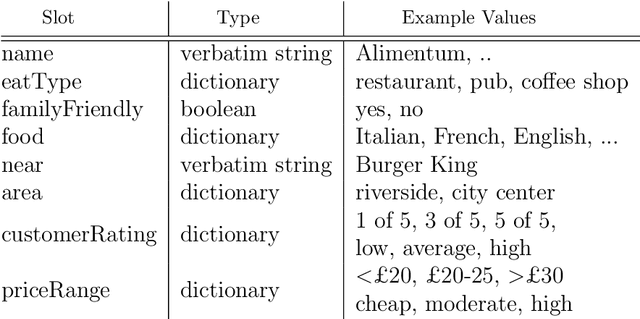
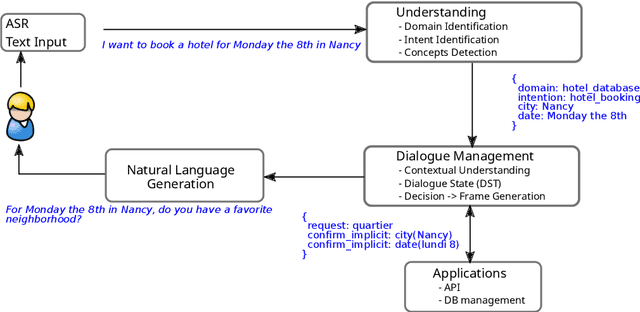
In this paper we survey the methods and concepts developed for the evaluation of dialogue systems. Evaluation is a crucial part during the development process. Often, dialogue systems are evaluated by means of human evaluations and questionnaires. However, this tends to be very cost and time intensive. Thus, much work has been put into finding methods, which allow to reduce the involvement of human labour. In this survey, we present the main concepts and methods. For this, we differentiate between the various classes of dialogue systems (task-oriented dialogue systems, conversational dialogue systems, and question-answering dialogue systems). We cover each class by introducing the main technologies developed for the dialogue systems and then by presenting the evaluation methods regarding this class.
An Effective Approach to Unsupervised Machine Translation
Feb 04, 2019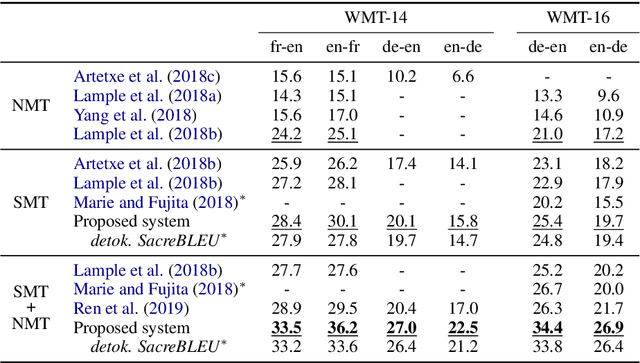

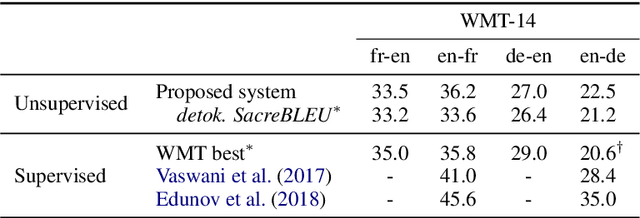
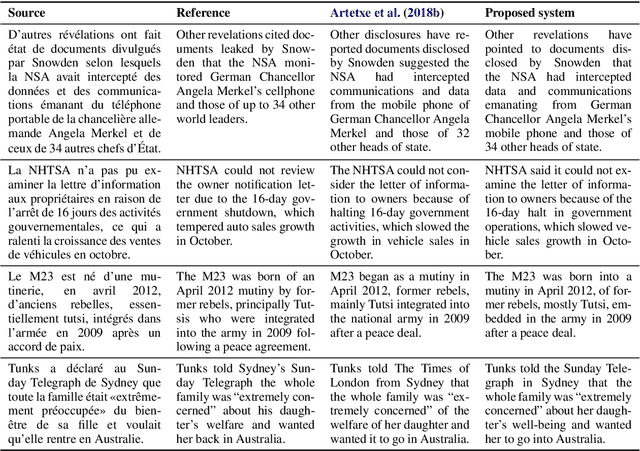
While machine translation has traditionally relied on large amounts of parallel corpora, a recent research line has managed to train both Neural Machine Translation (NMT) and Statistical Machine Translation (SMT) systems using monolingual corpora only. In this paper, we identify and address several deficiencies of existing unsupervised SMT approaches by exploiting subword information, developing a theoretically well founded unsupervised tuning method, and incorporating a joint refinement procedure. Moreover, we use our improved SMT system to initialize a dual NMT model, which is further fine-tuned through on-the-fly back-translation. Together, we obtain large improvements over the previous state-of-the-art in unsupervised machine translation. For instance, we get 22.5 BLEU points in English-to-German WMT 2014, 5.5 points more than the previous best unsupervised system, and 0.5 points more than the (supervised) shared task winner back in 2014.
Evaluating Multimodal Representations on Sentence Similarity: vSTS, Visual Semantic Textual Similarity Dataset
Sep 11, 2018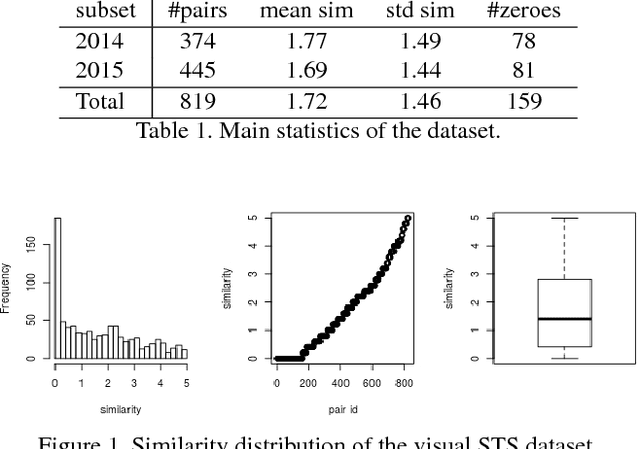
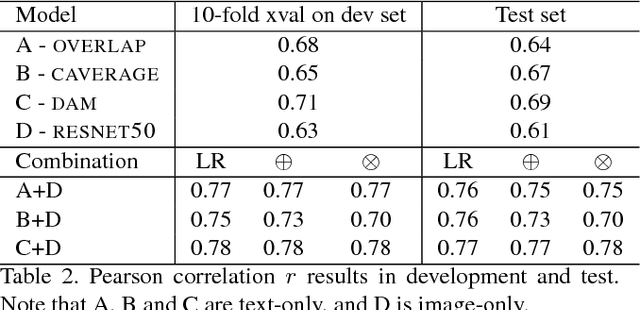
In this paper we introduce vSTS, a new dataset for measuring textual similarity of sentences using multimodal information. The dataset is comprised by images along with its respectively textual captions. We describe the dataset both quantitatively and qualitatively, and claim that it is a valid gold standard for measuring automatic multimodal textual similarity systems. We also describe the initial experiments combining the multimodal information.
Uncovering divergent linguistic information in word embeddings with lessons for intrinsic and extrinsic evaluation
Sep 06, 2018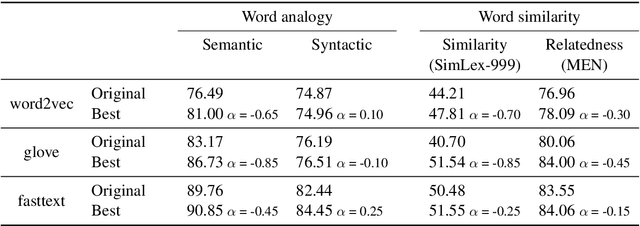
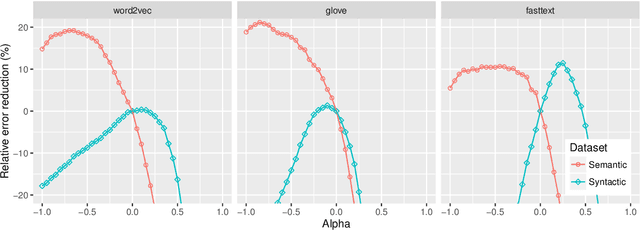
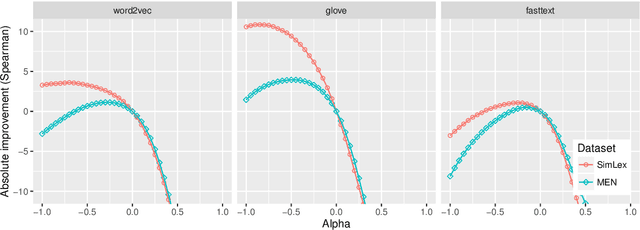
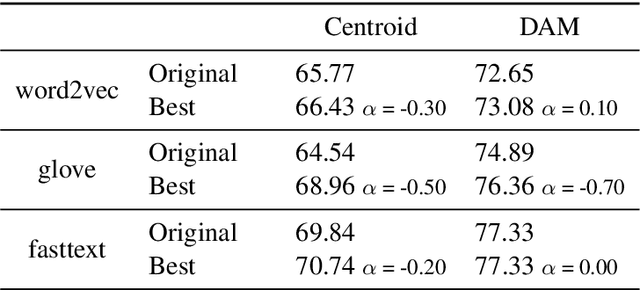
Following the recent success of word embeddings, it has been argued that there is no such thing as an ideal representation for words, as different models tend to capture divergent and often mutually incompatible aspects like semantics/syntax and similarity/relatedness. In this paper, we show that each embedding model captures more information than directly apparent. A linear transformation that adjusts the similarity order of the model without any external resource can tailor it to achieve better results in those aspects, providing a new perspective on how embeddings encode divergent linguistic information. In addition, we explore the relation between intrinsic and extrinsic evaluation, as the effect of our transformations in downstream tasks is higher for unsupervised systems than for supervised ones.
Unsupervised Statistical Machine Translation
Sep 04, 2018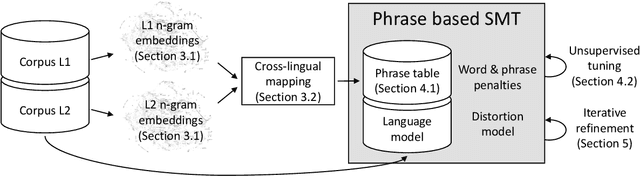
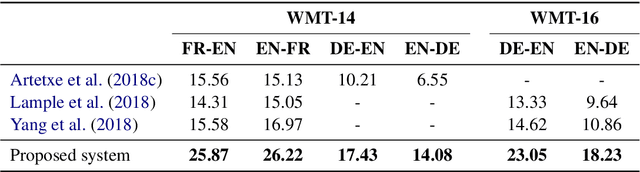
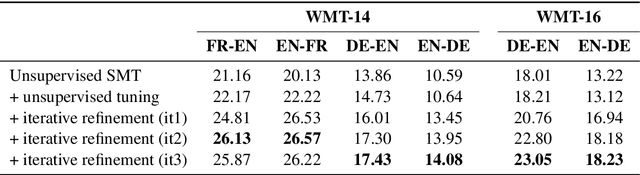
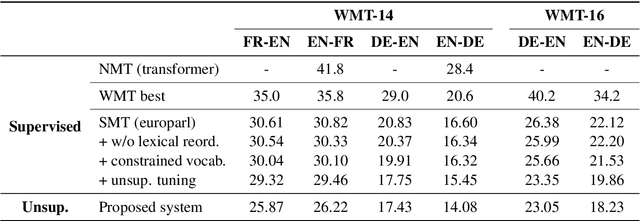
While modern machine translation has relied on large parallel corpora, a recent line of work has managed to train Neural Machine Translation (NMT) systems from monolingual corpora only (Artetxe et al., 2018c; Lample et al., 2018). Despite the potential of this approach for low-resource settings, existing systems are far behind their supervised counterparts, limiting their practical interest. In this paper, we propose an alternative approach based on phrase-based Statistical Machine Translation (SMT) that significantly closes the gap with supervised systems. Our method profits from the modular architecture of SMT: we first induce a phrase table from monolingual corpora through cross-lingual embedding mappings, combine it with an n-gram language model, and fine-tune hyperparameters through an unsupervised MERT variant. In addition, iterative backtranslation improves results further, yielding, for instance, 14.08 and 26.22 BLEU points in WMT 2014 English-German and English-French, respectively, an improvement of more than 7-10 BLEU points over previous unsupervised systems, and closing the gap with supervised SMT (Moses trained on Europarl) down to 2-5 BLEU points. Our implementation is available at https://github.com/artetxem/monoses
A robust self-learning method for fully unsupervised cross-lingual mappings of word embeddings
May 17, 2018
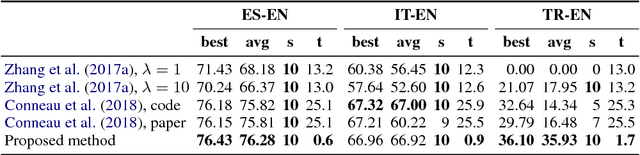

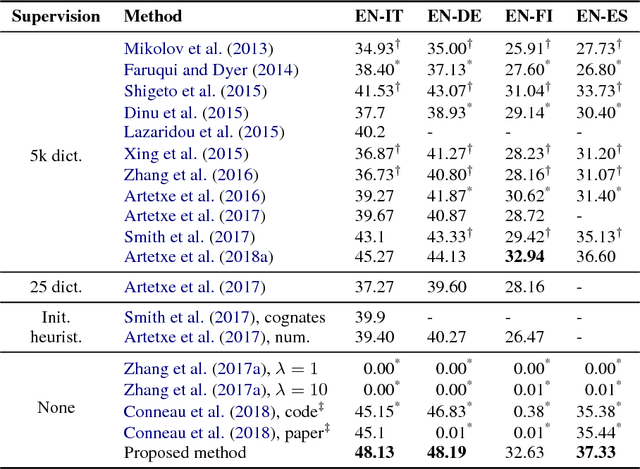
Recent work has managed to learn cross-lingual word embeddings without parallel data by mapping monolingual embeddings to a shared space through adversarial training. However, their evaluation has focused on favorable conditions, using comparable corpora or closely-related languages, and we show that they often fail in more realistic scenarios. This work proposes an alternative approach based on a fully unsupervised initialization that explicitly exploits the structural similarity of the embeddings, and a robust self-learning algorithm that iteratively improves this solution. Our method succeeds in all tested scenarios and obtains the best published results in standard datasets, even surpassing previous supervised systems. Our implementation is released as an open source project at https://github.com/artetxem/vecmap
The risk of sub-optimal use of Open Source NLP Software: UKB is inadvertently state-of-the-art in knowledge-based WSD
May 11, 2018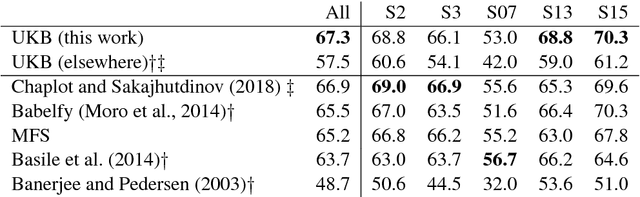
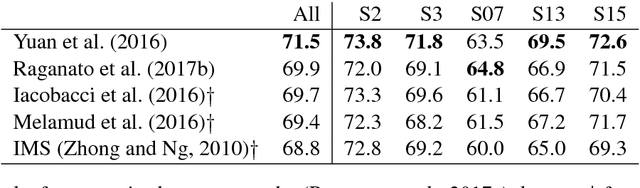
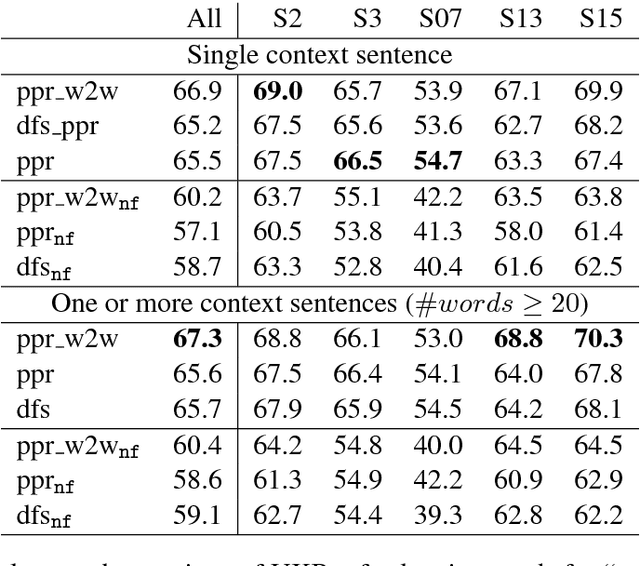
UKB is an open source collection of programs for performing, among other tasks, knowledge-based Word Sense Disambiguation (WSD). Since it was released in 2009 it has been often used out-of-the-box in sub-optimal settings. We show that nine years later it is the state-of-the-art on knowledge-based WSD. This case shows the pitfalls of releasing open source NLP software without optimal default settings and precise instructions for reproducibility.
Unsupervised Neural Machine Translation
Feb 26, 2018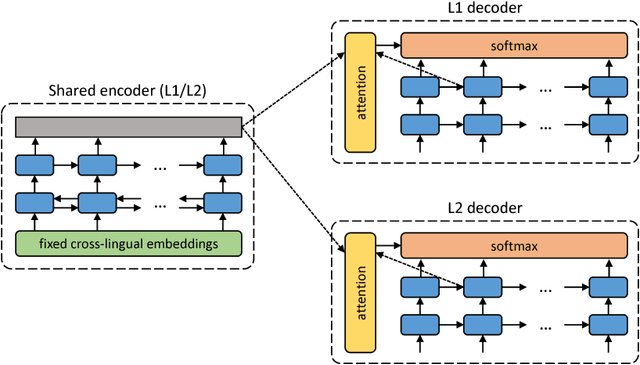
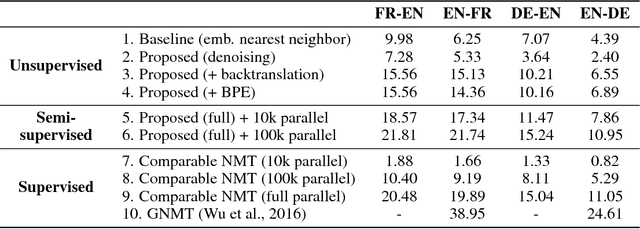
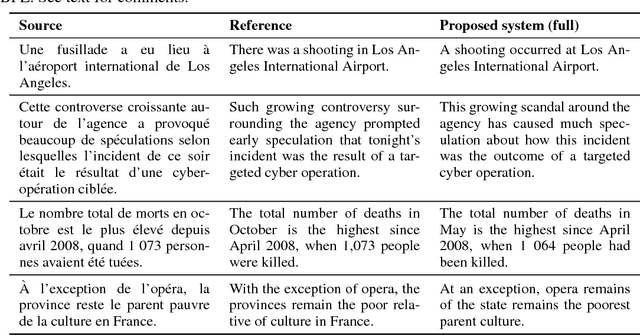
In spite of the recent success of neural machine translation (NMT) in standard benchmarks, the lack of large parallel corpora poses a major practical problem for many language pairs. There have been several proposals to alleviate this issue with, for instance, triangulation and semi-supervised learning techniques, but they still require a strong cross-lingual signal. In this work, we completely remove the need of parallel data and propose a novel method to train an NMT system in a completely unsupervised manner, relying on nothing but monolingual corpora. Our model builds upon the recent work on unsupervised embedding mappings, and consists of a slightly modified attentional encoder-decoder model that can be trained on monolingual corpora alone using a combination of denoising and backtranslation. Despite the simplicity of the approach, our system obtains 15.56 and 10.21 BLEU points in WMT 2014 French-to-English and German-to-English translation. The model can also profit from small parallel corpora, and attains 21.81 and 15.24 points when combined with 100,000 parallel sentences, respectively. Our implementation is released as an open source project.
SemEval-2017 Task 1: Semantic Textual Similarity - Multilingual and Cross-lingual Focused Evaluation
Jul 31, 2017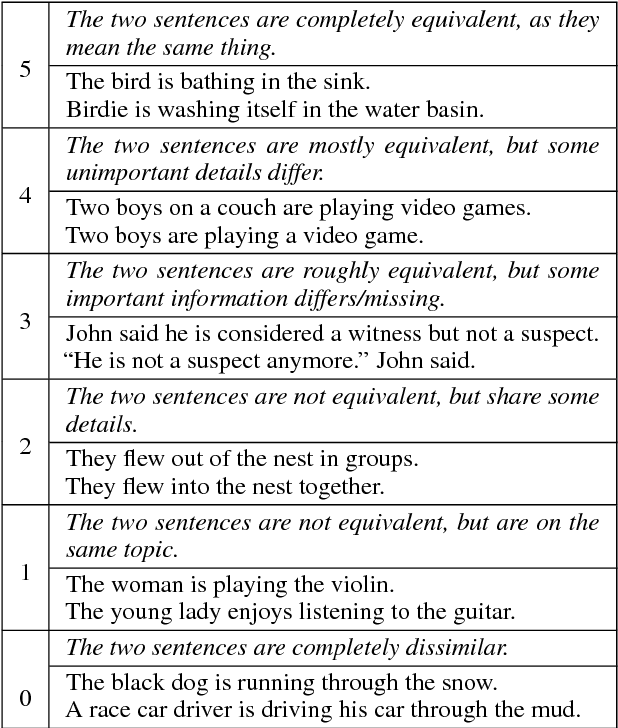
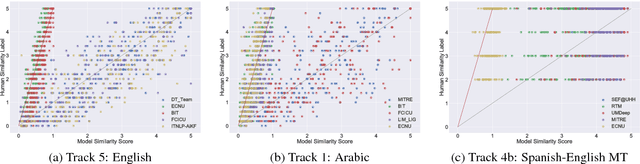
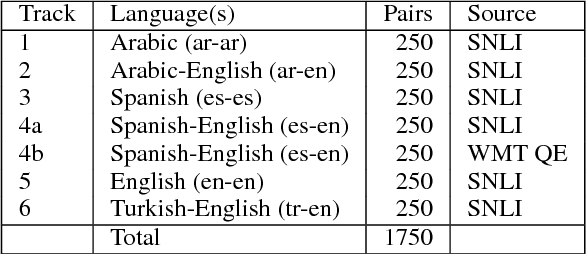
Semantic Textual Similarity (STS) measures the meaning similarity of sentences. Applications include machine translation (MT), summarization, generation, question answering (QA), short answer grading, semantic search, dialog and conversational systems. The STS shared task is a venue for assessing the current state-of-the-art. The 2017 task focuses on multilingual and cross-lingual pairs with one sub-track exploring MT quality estimation (MTQE) data. The task obtained strong participation from 31 teams, with 17 participating in all language tracks. We summarize performance and review a selection of well performing methods. Analysis highlights common errors, providing insight into the limitations of existing models. To support ongoing work on semantic representations, the STS Benchmark is introduced as a new shared training and evaluation set carefully selected from the corpus of English STS shared task data (2012-2017).
Evaluating the word-expert approach for Named-Entity Disambiguation
Mar 15, 2016
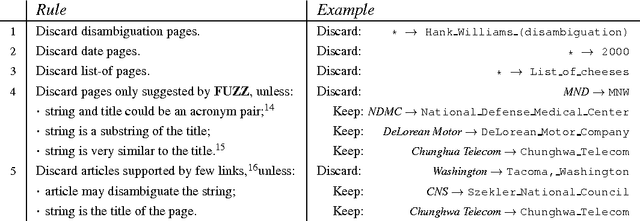
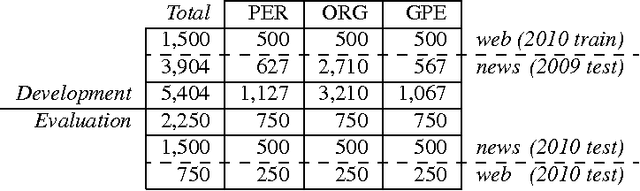
Named Entity Disambiguation (NED) is the task of linking a named-entity mention to an instance in a knowledge-base, typically Wikipedia. This task is closely related to word-sense disambiguation (WSD), where the supervised word-expert approach has prevailed. In this work we present the results of the word-expert approach to NED, where one classifier is built for each target entity mention string. The resources necessary to build the system, a dictionary and a set of training instances, have been automatically derived from Wikipedia. We provide empirical evidence of the value of this approach, as well as a study of the differences between WSD and NED, including ambiguity and synonymy statistics.