 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLifetime-Aware Design of Item-Level Intelligence
Sep 09, 2025



We present FlexiFlow, a lifetime-aware design framework for item-level intelligence (ILI) where computation is integrated directly into disposable products like food packaging and medical patches. Our framework leverages natively flexible electronics which offer significantly lower costs than silicon but are limited to kHz speeds and several thousands of gates. Our insight is that unlike traditional computing with more uniform deployment patterns, ILI applications exhibit 1000X variation in operational lifetime, fundamentally changing optimal architectural design decisions when considering trillion-item deployment scales. To enable holistic design and optimization, we model the trade-offs between embodied carbon footprint and operational carbon footprint based on application-specific lifetimes. The framework includes: (1) FlexiBench, a workload suite targeting sustainability applications from spoilage detection to health monitoring; (2) FlexiBits, area-optimized RISC-V cores with 1/4/8-bit datapaths achieving 2.65X to 3.50X better energy efficiency per workload execution; and (3) a carbon-aware model that selects optimal architectures based on deployment characteristics. We show that lifetime-aware microarchitectural design can reduce carbon footprint by 1.62X, while algorithmic decisions can reduce carbon footprint by 14.5X. We validate our approach through the first tape-out using a PDK for flexible electronics with fully open-source tools, achieving 30.9kHz operation. FlexiFlow enables exploration of computing at the Extreme Edge where conventional design methodologies must be reevaluated to account for new constraints and considerations.
Efficient FPGA Implementation of Time-Domain Popcount for Low-Complexity Machine Learning
May 04, 2025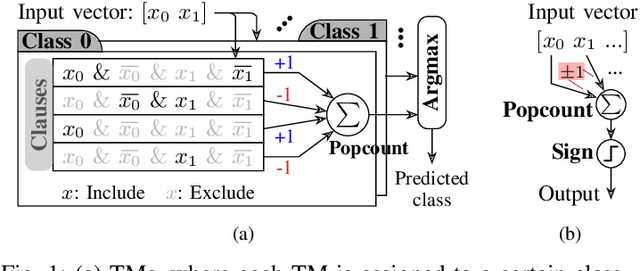
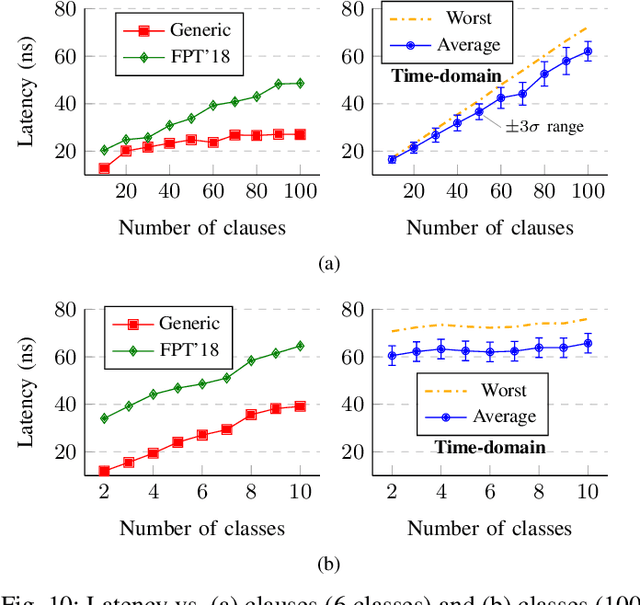
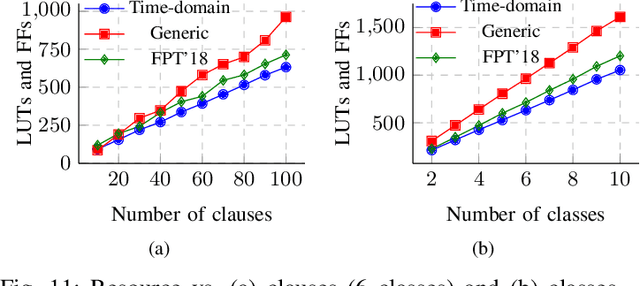
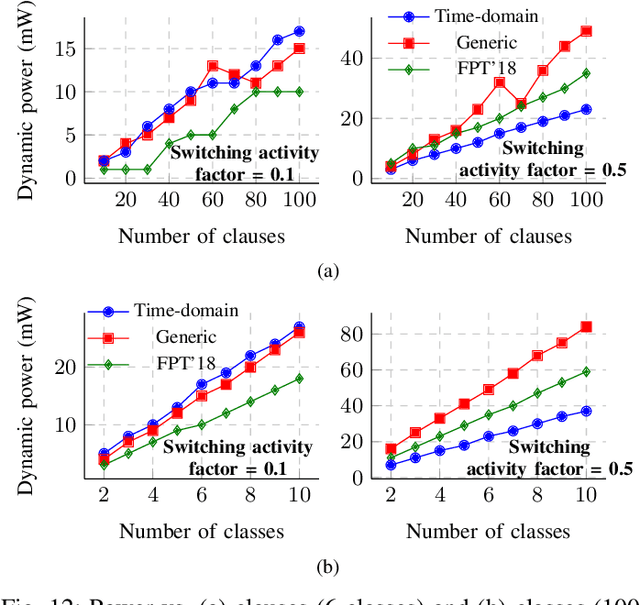
Population count (popcount) is a crucial operation for many low-complexity machine learning (ML) algorithms, including Tsetlin Machine (TM)-a promising new ML method, particularly well-suited for solving classification tasks. The inference mechanism in TM consists of propositional logic-based structures within each class, followed by a majority voting scheme, which makes the classification decision. In TM, the voters are the outputs of Boolean clauses. The voting mechanism comprises two operations: popcount for each class and determining the class with the maximum vote by means of an argmax operation. While TMs offer a lightweight ML alternative, their performance is often limited by the high computational cost of popcount and comparison required to produce the argmax result. In this paper, we propose an innovative approach to accelerate and optimize these operations by performing them in the time domain. Our time-domain implementation uses programmable delay lines (PDLs) and arbiters to efficiently manage these tasks through delay-based mechanisms. We also present an FPGA design flow for practical implementation of the time-domain popcount, addressing delay skew and ensuring that the behavior matches that of the model's intended functionality. By leveraging the natural compatibility of the proposed popcount with asynchronous architectures, we demonstrate significant improvements in an asynchronous TM, including up to 38% reduction in latency, 43.1% reduction in dynamic power, and 15% savings in resource utilization, compared to synchronous TMs using adder-based popcount.
Tiny Classifier Circuits: Evolving Accelerators for Tabular Data
Feb 28, 2023



A typical machine learning (ML) development cycle for edge computing is to maximise the performance during model training and then minimise the memory/area footprint of the trained model for deployment on edge devices targeting CPUs, GPUs, microcontrollers, or custom hardware accelerators. This paper proposes a methodology for automatically generating predictor circuits for classification of tabular data with comparable prediction performance to conventional ML techniques while using substantially fewer hardware resources and power. The proposed methodology uses an evolutionary algorithm to search over the space of logic gates and automatically generates a classifier circuit with maximised training prediction accuracy. Classifier circuits are so tiny (i.e., consisting of no more than 300 logic gates) that they are called "Tiny Classifier" circuits, and can efficiently be implemented in ASIC or on an FPGA. We empirically evaluate the automatic Tiny Classifier circuit generation methodology or "Auto Tiny Classifiers" on a wide range of tabular datasets, and compare it against conventional ML techniques such as Amazon's AutoGluon, Google's TabNet and a neural search over Multi-Layer Perceptrons. Despite Tiny Classifiers being constrained to a few hundred logic gates, we observe no statistically significant difference in prediction performance in comparison to the best-performing ML baseline. When synthesised as a Silicon chip, Tiny Classifiers use 8-56x less area and 4-22x less power. When implemented as an ultra-low cost chip on a flexible substrate (i.e., FlexIC), they occupy 10-75x less area and consume 13-75x less power compared to the most hardware-efficient ML baseline. On an FPGA, Tiny Classifiers consume 3-11x fewer resources.