 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTsetlinWiSARD: On-Chip Training of Weightless Neural Networks using Tsetlin Automata on FPGAs
Mar 25, 2026Increasing demands for adaptability, privacy, and security at the edge have persistently pushed the frontiers for a new generation of machine learning (ML) algorithms with training and inference capabilities on-chip. Weightless Neural Network (WNN) is such an algorithm that is principled on lookup table based simple neuron structures. As a result, it offers architectural benefits, such as low-latency, low-complexity inference, compared to deep neural networks that depend heavily on multiply-accumulate operations. However, traditional WNNs rely on memorization-based one-shot training, which either leads to overfitting and reduced accuracy or requires tedious post-training adjustments, limiting their effectiveness for efficient on chip training. In this work, we propose TsetlinWiSARD, a training approach for WNNs that leverages Tsetlin Automata (TAs) to enable probabilistic, feedback-driven learning. It overcomes the overfitting of WiSARD's one-shot training with iterative optimization, while maintaining simple, continuous binary feedback for efficient on-chip training. Central to our approach is a field programmable gate array (FPGA)-based training architecture that delivers state-of-the-art accuracy while significantly improving hardware efficiency. Our approach provides over 1000x faster training when compared with the traditional WiSARD implementation of WNNs. Further, we demonstrate 22% reduced resource usage, 93.3% lower latency, and 64.2% lower power consumption compared to FPGA-based training accelerators implementing other ML algorithms.
Efficient FPGA Implementation of Time-Domain Popcount for Low-Complexity Machine Learning
May 04, 2025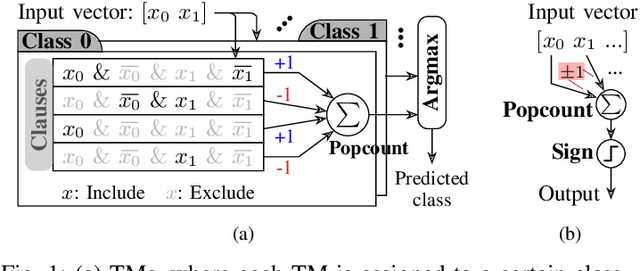
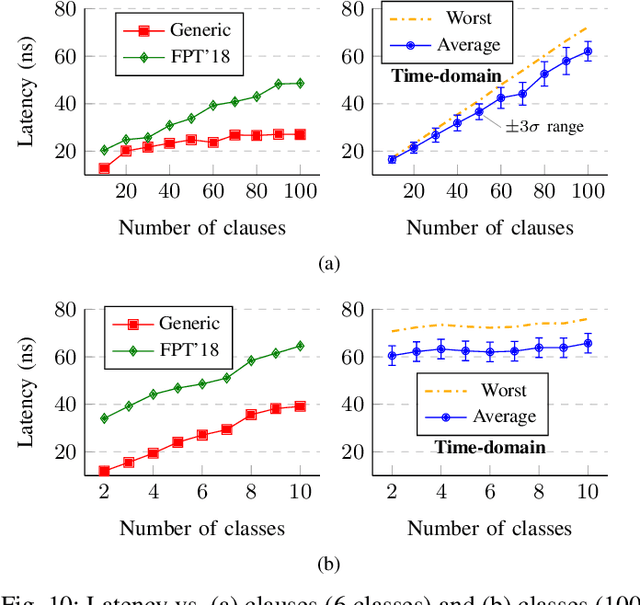
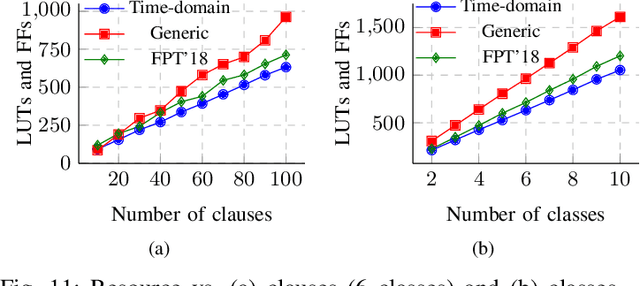
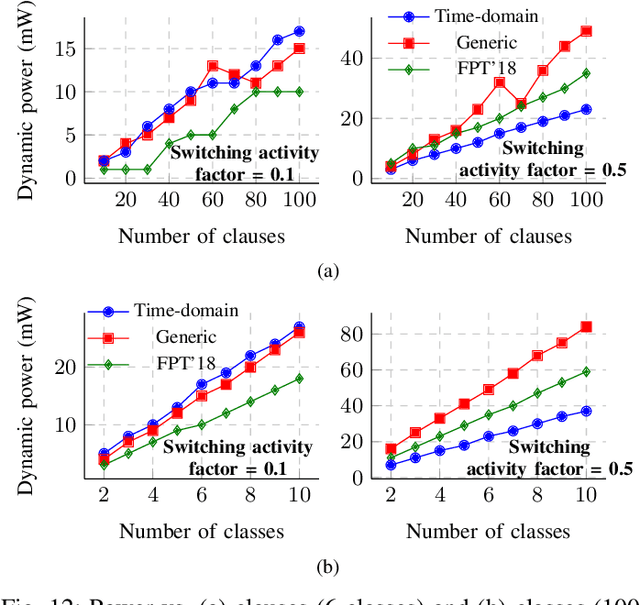
Population count (popcount) is a crucial operation for many low-complexity machine learning (ML) algorithms, including Tsetlin Machine (TM)-a promising new ML method, particularly well-suited for solving classification tasks. The inference mechanism in TM consists of propositional logic-based structures within each class, followed by a majority voting scheme, which makes the classification decision. In TM, the voters are the outputs of Boolean clauses. The voting mechanism comprises two operations: popcount for each class and determining the class with the maximum vote by means of an argmax operation. While TMs offer a lightweight ML alternative, their performance is often limited by the high computational cost of popcount and comparison required to produce the argmax result. In this paper, we propose an innovative approach to accelerate and optimize these operations by performing them in the time domain. Our time-domain implementation uses programmable delay lines (PDLs) and arbiters to efficiently manage these tasks through delay-based mechanisms. We also present an FPGA design flow for practical implementation of the time-domain popcount, addressing delay skew and ensuring that the behavior matches that of the model's intended functionality. By leveraging the natural compatibility of the proposed popcount with asynchronous architectures, we demonstrate significant improvements in an asynchronous TM, including up to 38% reduction in latency, 43.1% reduction in dynamic power, and 15% savings in resource utilization, compared to synchronous TMs using adder-based popcount.
ETHEREAL: Energy-efficient and High-throughput Inference using Compressed Tsetlin Machine
Feb 08, 2025



The Tsetlin Machine (TM) is a novel alternative to deep neural networks (DNNs). Unlike DNNs, which rely on multi-path arithmetic operations, a TM learns propositional logic patterns from data literals using Tsetlin automata. This fundamental shift from arithmetic to logic underpinning makes TM suitable for empowering new applications with low-cost implementations. In TM, literals are often included by both positive and negative clauses within the same class, canceling out their impact on individual class definitions. This property can be exploited to develop compressed TM models, enabling energy-efficient and high-throughput inferences for machine learning (ML) applications. We introduce a training approach that incorporates excluded automata states to sparsify TM logic patterns in both positive and negative clauses. This exclusion is iterative, ensuring that highly class-correlated (and therefore significant) literals are retained in the compressed inference model, ETHEREAL, to maintain strong classification accuracy. Compared to standard TMs, ETHEREAL TM models can reduce model size by up to 87.54%, with only a minor accuracy compromise. We validate the impact of this compression on eight real-world Tiny machine learning (TinyML) datasets against standard TM, equivalent Random Forest (RF) and Binarized Neural Network (BNN) on the STM32F746G-DISCO platform. Our results show that ETHEREAL TM models achieve over an order of magnitude reduction in inference time (resulting in higher throughput) and energy consumption compared to BNNs, while maintaining a significantly smaller memory footprint compared to RFs.