 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe DIDI dataset: Digital Ink Diagram data
Feb 24, 2020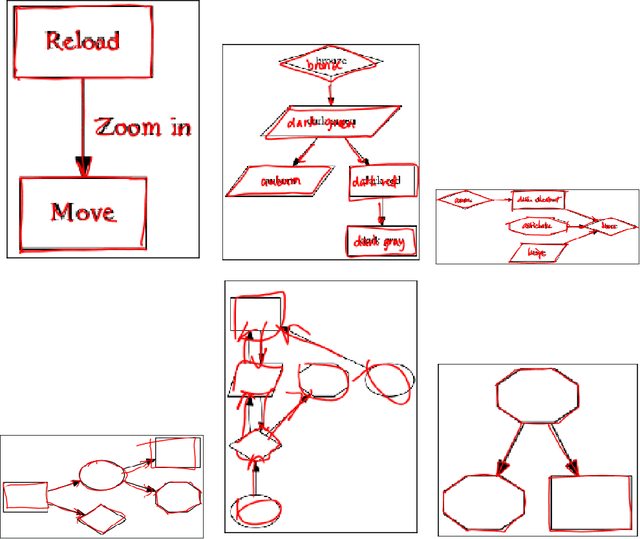
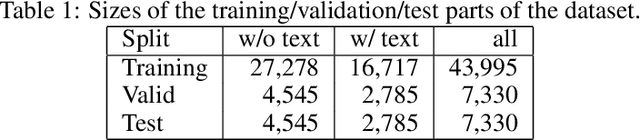
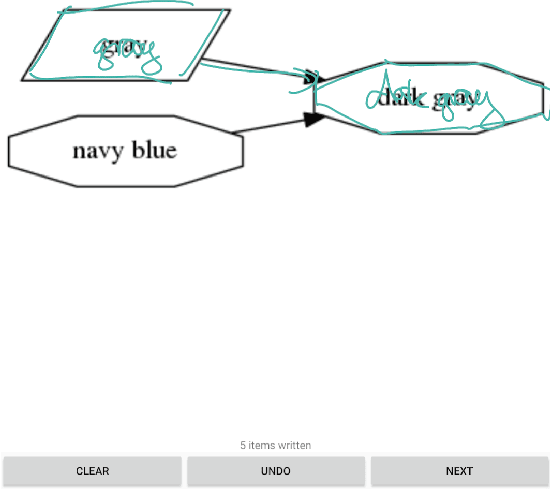
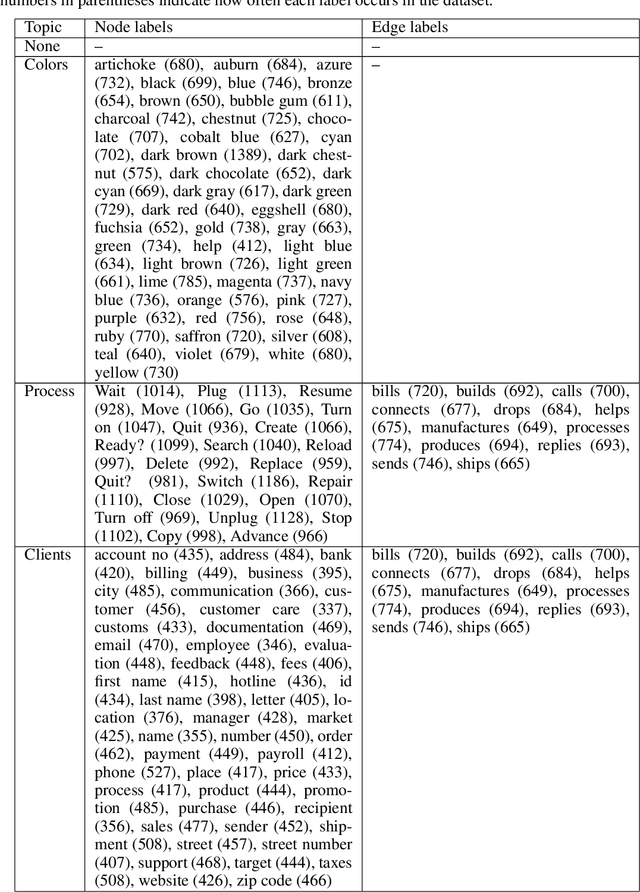
We are releasing a dataset of diagram drawings with dynamic drawing information. The dataset aims to foster research in interactive graphical symbolic understanding. The dataset was obtained using a prompted data collection effort.
Learning Functionally Decomposed Hierarchies for Continuous Control Tasks
Feb 14, 2020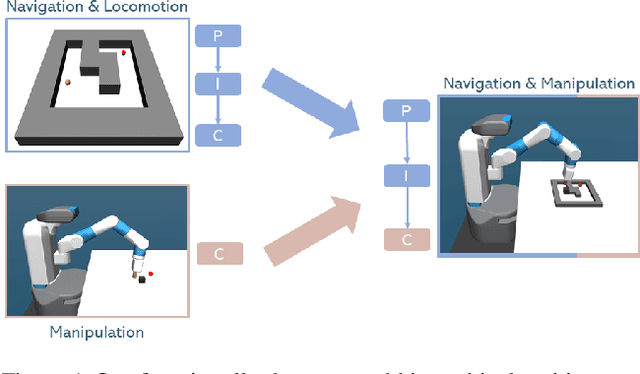
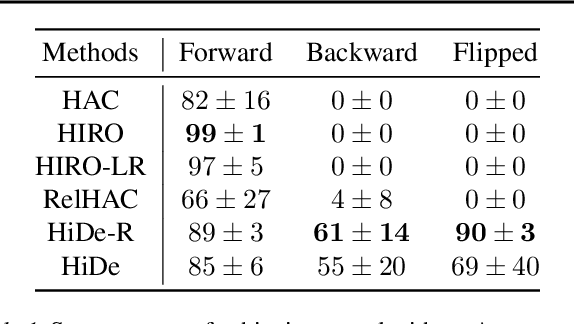
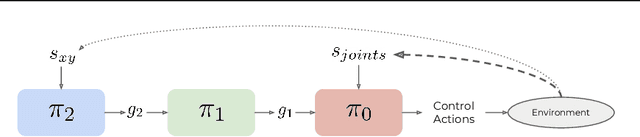
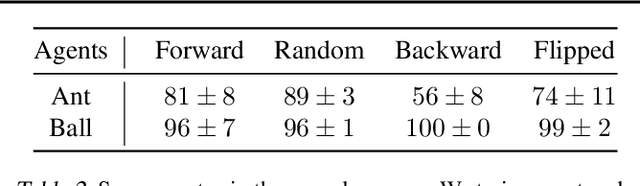
Solving long-horizon sequential decision making tasks in environments with sparse rewards is a longstanding problem in reinforcement learning (RL) research. Hierarchical Reinforcement Learning (HRL) has held the promise to enhance the capabilities of RL agents via operation on different levels of temporal abstraction. Despite the success of recent works in dealing with inherent nonstationarity and sample complexity, it remains difficult to generalize to unseen environments and to transfer different layers of the policy to other agents. In this paper, we propose a novel HRL architecture, Hierarchical Decompositional Reinforcement Learning (HiDe), which allows decomposition of the hierarchical layers into independent subtasks, yet allows for joint training of all layers in end-to-end manner. The main insight is to combine a control policy on a lower level with an image-based planning policy on a higher level. We evaluate our method on various complex continuous control tasks, demonstrating that generalization across environments and transfer of higher level policies, such as from a simple ball to a complex humanoid, can be achieved. See videos https://sites.google.com/view/hide-rl.
Structured Prediction Helps 3D Human Motion Modelling
Oct 20, 2019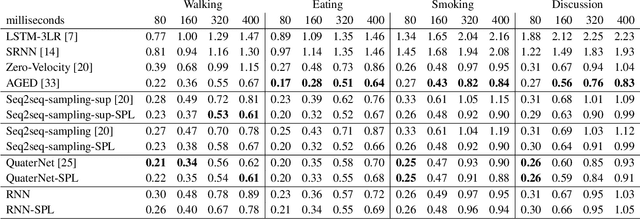
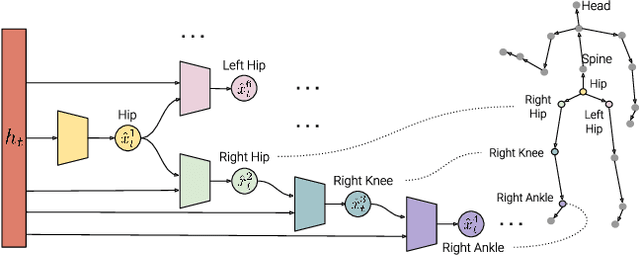
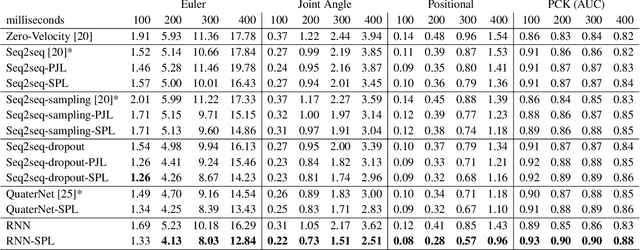
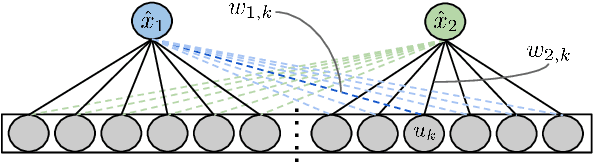
Human motion prediction is a challenging and important task in many computer vision application domains. Existing work only implicitly models the spatial structure of the human skeleton. In this paper, we propose a novel approach that decomposes the prediction into individual joints by means of a structured prediction layer that explicitly models the joint dependencies. This is implemented via a hierarchy of small-sized neural networks connected analogously to the kinematic chains in the human body as well as a joint-wise decomposition in the loss function. The proposed layer is agnostic to the underlying network and can be used with existing architectures for motion modelling. Prior work typically leverages the H3.6M dataset. We show that some state-of-the-art techniques do not perform well when trained and tested on AMASS, a recently released dataset 14 times the size of H3.6M. Our experiments indicate that the proposed layer increases the performance of motion forecasting irrespective of the base network, joint-angle representation, and prediction horizon. We furthermore show that the layer also improves motion predictions qualitatively. We make code and models publicly available at https://ait.ethz.ch/projects/2019/spl.
STCN: Stochastic Temporal Convolutional Networks
Feb 18, 2019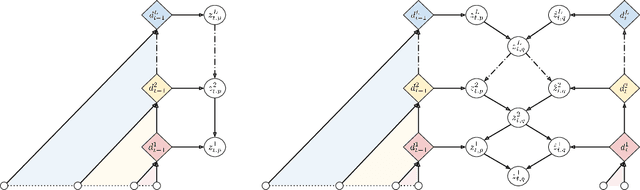
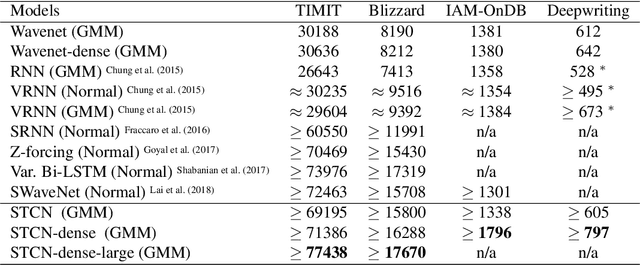
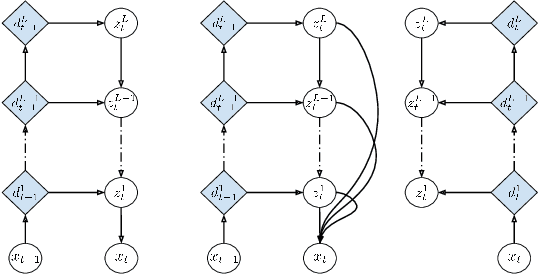

Convolutional architectures have recently been shown to be competitive on many sequence modelling tasks when compared to the de-facto standard of recurrent neural networks (RNNs), while providing computational and modeling advantages due to inherent parallelism. However, currently there remains a performance gap to more expressive stochastic RNN variants, especially those with several layers of dependent random variables. In this work, we propose stochastic temporal convolutional networks (STCNs), a novel architecture that combines the computational advantages of temporal convolutional networks (TCN) with the representational power and robustness of stochastic latent spaces. In particular, we propose a hierarchy of stochastic latent variables that captures temporal dependencies at different time-scales. The architecture is modular and flexible due to the decoupling of the deterministic and stochastic layers. We show that the proposed architecture achieves state of the art log-likelihoods across several tasks. Finally, the model is capable of predicting high-quality synthetic samples over a long-range temporal horizon in modeling of handwritten text.
Deep Inertial Poser: Learning to Reconstruct Human Pose from Sparse Inertial Measurements in Real Time
Oct 10, 2018

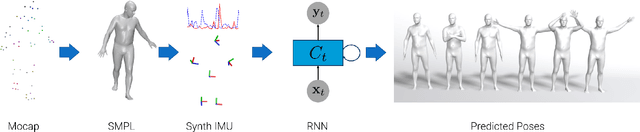
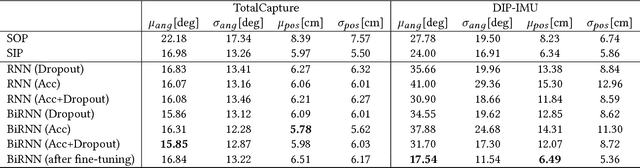
We demonstrate a novel deep neural network capable of reconstructing human full body pose in real-time from 6 Inertial Measurement Units (IMUs) worn on the user's body. In doing so, we address several difficult challenges. First, the problem is severely under-constrained as multiple pose parameters produce the same IMU orientations. Second, capturing IMU data in conjunction with ground-truth poses is expensive and difficult to do in many target application scenarios (e.g., outdoors). Third, modeling temporal dependencies through non-linear optimization has proven effective in prior work but makes real-time prediction infeasible. To address this important limitation, we learn the temporal pose priors using deep learning. To learn from sufficient data, we synthesize IMU data from motion capture datasets. A bi-directional RNN architecture leverages past and future information that is available at training time. At test time, we deploy the network in a sliding window fashion, retaining real time capabilities. To evaluate our method, we recorded DIP-IMU, a dataset consisting of $10$ subjects wearing 17 IMUs for validation in $64$ sequences with $330\,000$ time instants; this constitutes the largest IMU dataset publicly available. We quantitatively evaluate our approach on multiple datasets and show results from a real-time implementation. DIP-IMU and the code are available for research purposes.
DeepWriting: Making Digital Ink Editable via Deep Generative Modeling
Jan 25, 2018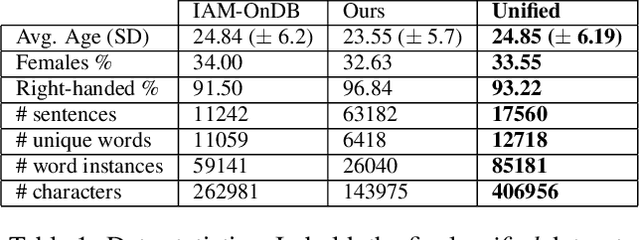
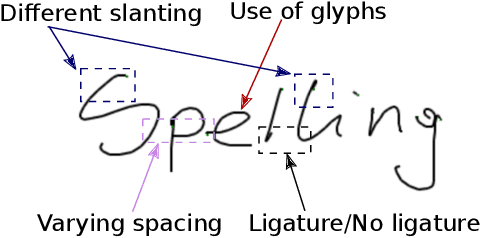
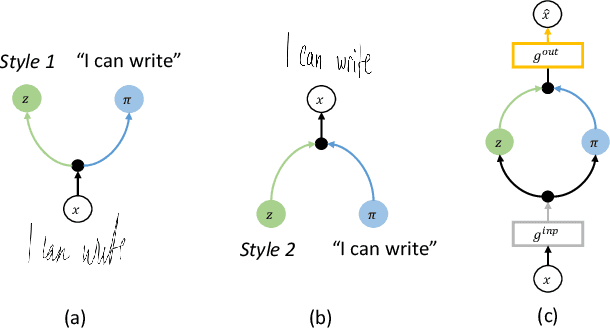

Digital ink promises to combine the flexibility and aesthetics of handwriting and the ability to process, search and edit digital text. Character recognition converts handwritten text into a digital representation, albeit at the cost of losing personalized appearance due to the technical difficulties of separating the interwoven components of content and style. In this paper, we propose a novel generative neural network architecture that is capable of disentangling style from content and thus making digital ink editable. Our model can synthesize arbitrary text, while giving users control over the visual appearance (style). For example, allowing for style transfer without changing the content, editing of digital ink at the word level and other application scenarios such as spell-checking and correction of handwritten text. We furthermore contribute a new dataset of handwritten text with fine-grained annotations at the character level and report results from an initial user evaluation.
Learning Human Motion Models for Long-term Predictions
Dec 03, 2017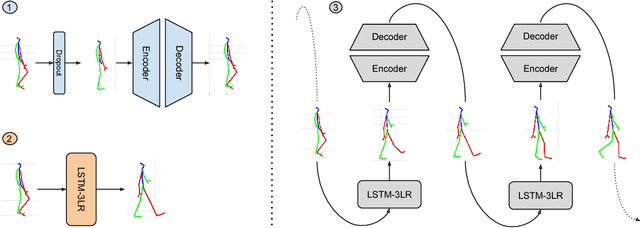
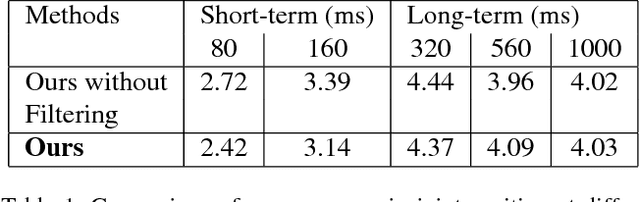
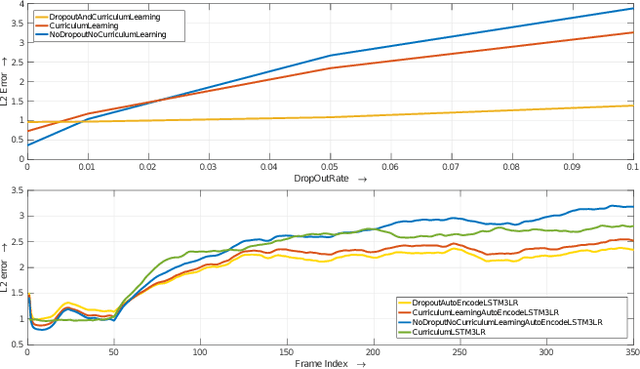
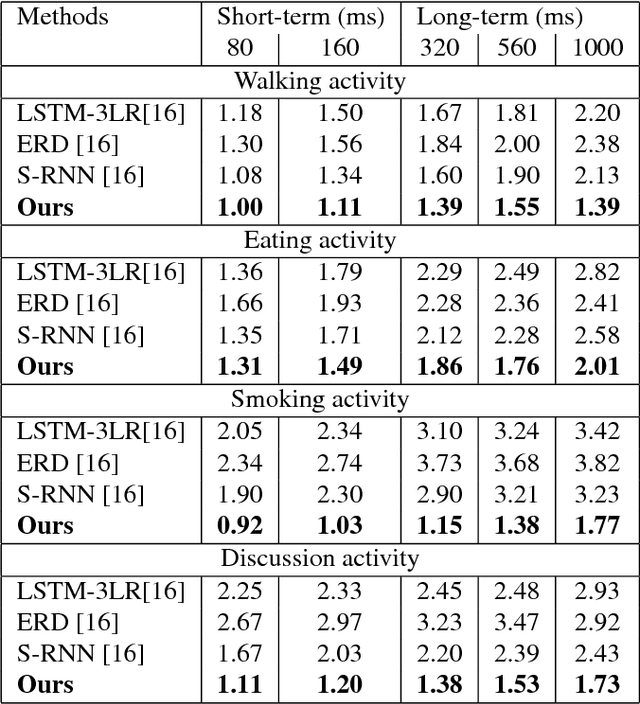
We propose a new architecture for the learning of predictive spatio-temporal motion models from data alone. Our approach, dubbed the Dropout Autoencoder LSTM, is capable of synthesizing natural looking motion sequences over long time horizons without catastrophic drift or motion degradation. The model consists of two components, a 3-layer recurrent neural network to model temporal aspects and a novel auto-encoder that is trained to implicitly recover the spatial structure of the human skeleton via randomly removing information about joints during training time. This Dropout Autoencoder (D-AE) is then used to filter each predicted pose of the LSTM, reducing accumulation of error and hence drift over time. Furthermore, we propose new evaluation protocols to assess the quality of synthetic motion sequences even for which no ground truth data exists. The proposed protocols can be used to assess generated sequences of arbitrary length. Finally, we evaluate our proposed method on two of the largest motion-capture datasets available to date and show that our model outperforms the state-of-the-art on a variety of actions, including cyclic and acyclic motion, and that it can produce natural looking sequences over longer time horizons than previous methods.
Guiding InfoGAN with Semi-Supervision
Jul 14, 2017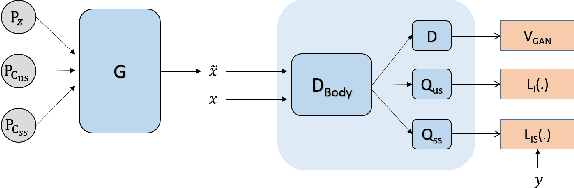

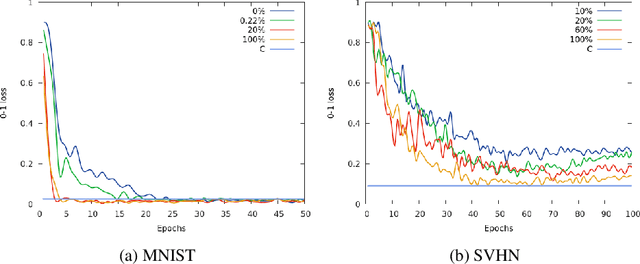

In this paper we propose a new semi-supervised GAN architecture (ss-InfoGAN) for image synthesis that leverages information from few labels (as little as 0.22%, max. 10% of the dataset) to learn semantically meaningful and controllable data representations where latent variables correspond to label categories. The architecture builds on Information Maximizing Generative Adversarial Networks (InfoGAN) and is shown to learn both continuous and categorical codes and achieves higher quality of synthetic samples compared to fully unsupervised settings. Furthermore, we show that using small amounts of labeled data speeds-up training convergence. The architecture maintains the ability to disentangle latent variables for which no labels are available. Finally, we contribute an information-theoretic reasoning on how introducing semi-supervision increases mutual information between synthetic and real data.
Learning Deep Temporal Representations for Brain Decoding
Jan 12, 2015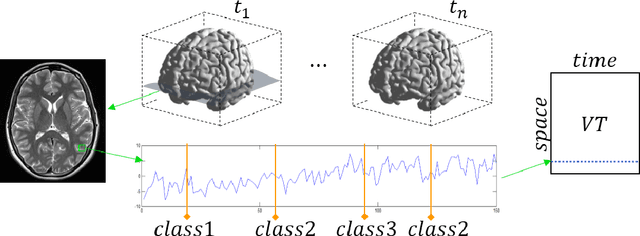
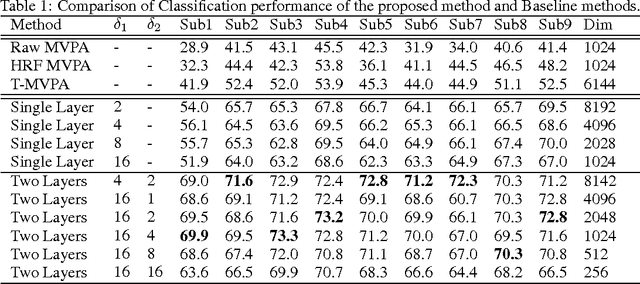
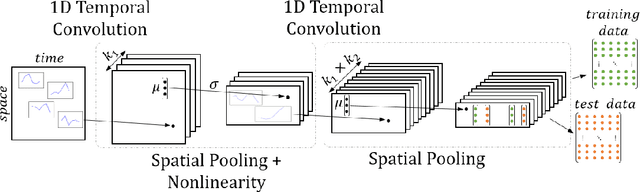
Functional magnetic resonance imaging produces high dimensional data, with a less then ideal number of labelled samples for brain decoding tasks (predicting brain states). In this study, we propose a new deep temporal convolutional neural network architecture with spatial pooling for brain decoding which aims to reduce dimensionality of feature space along with improved classification performance. Temporal representations (filters) for each layer of the convolutional model are learned by leveraging unlabelled fMRI data in an unsupervised fashion with regularized autoencoders. Learned temporal representations in multiple levels capture the regularities in the temporal domain and are observed to be a rich bank of activation patterns which also exhibit similarities to the actual hemodynamic responses. Further, spatial pooling layers in the convolutional architecture reduce the dimensionality without losing excessive information. By employing the proposed temporal convolutional architecture with spatial pooling, raw input fMRI data is mapped to a non-linear, highly-expressive and low-dimensional feature space where the final classification is conducted. In addition, we propose a simple heuristic approach for hyper-parameter tuning when no validation data is available. Proposed method is tested on a ten class recognition memory experiment with nine subjects. The results support the efficiency and potential of the proposed model, compared to the baseline multi-voxel pattern analysis techniques.