 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Don't quote me on that": Finding Mixtures of Sources in News Articles
Apr 19, 2021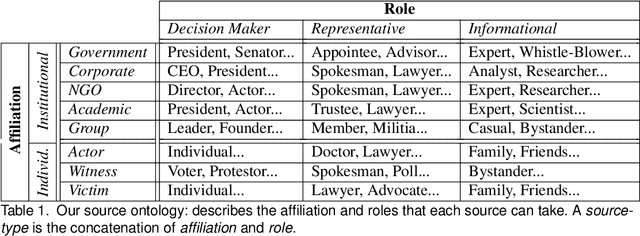
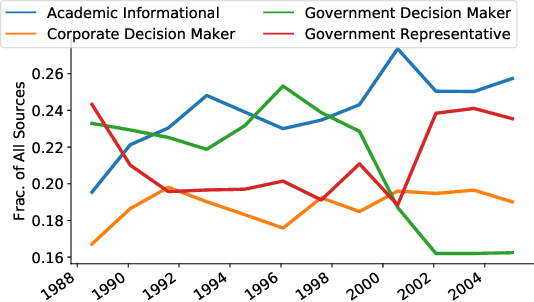


Journalists publish statements provided by people, or \textit{sources} to contextualize current events, help voters make informed decisions, and hold powerful individuals accountable. In this work, we construct an ontological labeling system for sources based on each source's \textit{affiliation} and \textit{role}. We build a probabilistic model to infer these attributes for named sources and to describe news articles as mixtures of these sources. Our model outperforms existing mixture modeling and co-clustering approaches and correctly infers source-type in 80\% of expert-evaluated trials. Such work can facilitate research in downstream tasks like opinion and argumentation mining, representing a first step towards machine-in-the-loop \textit{computational journalism} systems.
Modeling "Newsworthiness" for Lead-Generation Across Corpora
Apr 19, 2021
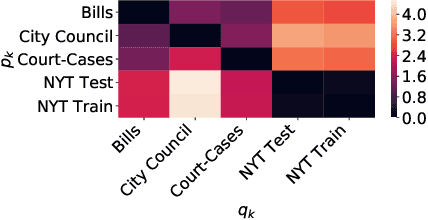

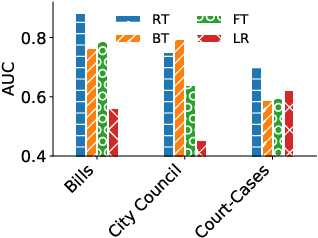
Journalists obtain "leads", or story ideas, by reading large corpora of government records: court cases, proposed bills, etc. However, only a small percentage of such records are interesting documents. We propose a model of "newsworthiness" aimed at surfacing interesting documents. We train models on automatically labeled corpora -- published newspaper articles -- to predict whether each article was a front-page article (i.e., \textbf{newsworthy}) or not (i.e., \textbf{less newsworthy}). We transfer these models to unlabeled corpora -- court cases, bills, city-council meeting minutes -- to rank documents in these corpora on "newsworthiness". A fine-tuned RoBERTa model achieves .93 AUC performance on heldout labeled documents, and .88 AUC on expert-validated unlabeled corpora. We provide interpretation and visualization for our models.
Individualized Context-Aware Tensor Factorization for Online Games Predictions
Feb 22, 2021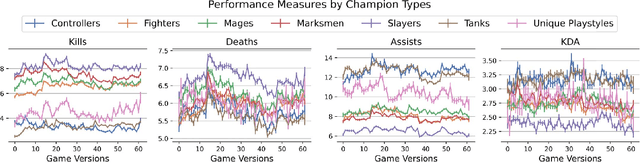
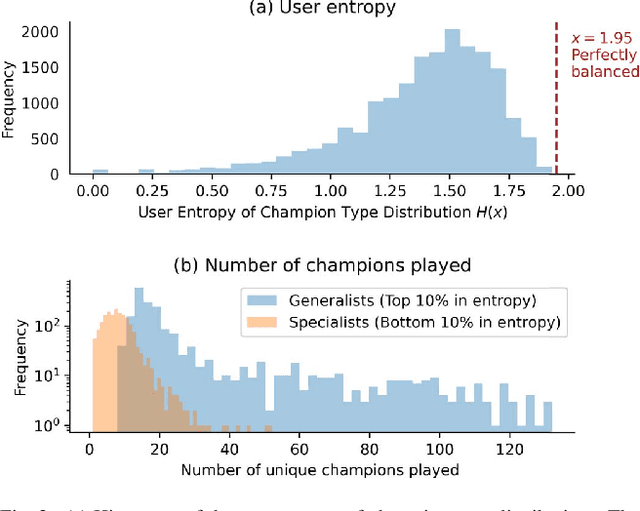
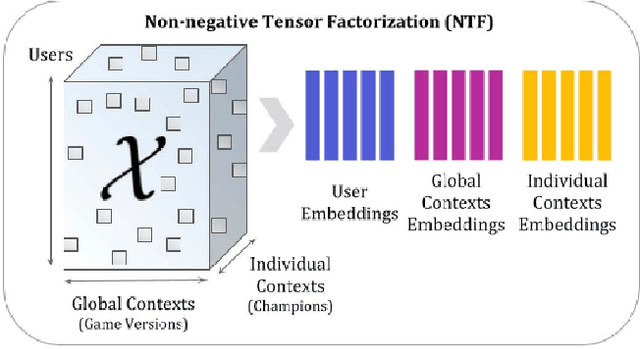
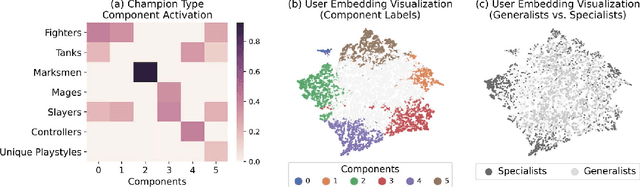
Individual behavior and decisions are substantially influenced by their contexts, such as location, environment, and time. Changes along these dimensions can be readily observed in Multiplayer Online Battle Arena games (MOBA), where players face different in-game settings for each match and are subject to frequent game patches. Existing methods utilizing contextual information generalize the effect of a context over the entire population, but contextual information tailored to each individual can be more effective. To achieve this, we present the Neural Individualized Context-aware Embeddings (NICE) model for predicting user performance and game outcomes. Our proposed method identifies individual behavioral differences in different contexts by learning latent representations of users and contexts through non-negative tensor factorization. Using a dataset from the MOBA game League of Legends, we demonstrate that our model substantially improves the prediction of winning outcome, individual user performance, and user engagement.
Tracking e-cigarette warning label compliance on Instagram with deep learning
Feb 08, 2021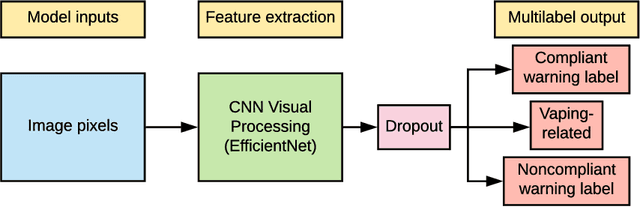

The U.S. Food & Drug Administration (FDA) requires that e-cigarette advertisements include a prominent warning label that reminds consumers that nicotine is addictive. However, the high volume of vaping-related posts on social media makes compliance auditing expensive and time-consuming, suggesting that an automated, scalable method is needed. We sought to develop and evaluate a deep learning system designed to automatically determine if an Instagram post promotes vaping, and if so, if an FDA-compliant warning label was included or if a non-compliant warning label was visible in the image. We compiled and labeled a dataset of 4,363 Instagram images, of which 44% were vaping-related, 3% contained FDA-compliant warning labels, and 4% contained non-compliant labels. Using a 20% test set for evaluation, we tested multiple neural network variations: image processing backbone model (Inceptionv3, ResNet50, EfficientNet), data augmentation, progressive layer unfreezing, output bias initialization designed for class imbalance, and multitask learning. Our final model achieved an area under the curve (AUC) and [accuracy] of 0.97 [92%] on vaping classification, 0.99 [99%] on FDA-compliant warning labels, and 0.94 [97%] on non-compliant warning labels. We conclude that deep learning models can effectively identify vaping posts on Instagram and track compliance with FDA warning label requirements.
Graph Signal Recovery Using Restricted Boltzmann Machines
Nov 20, 2020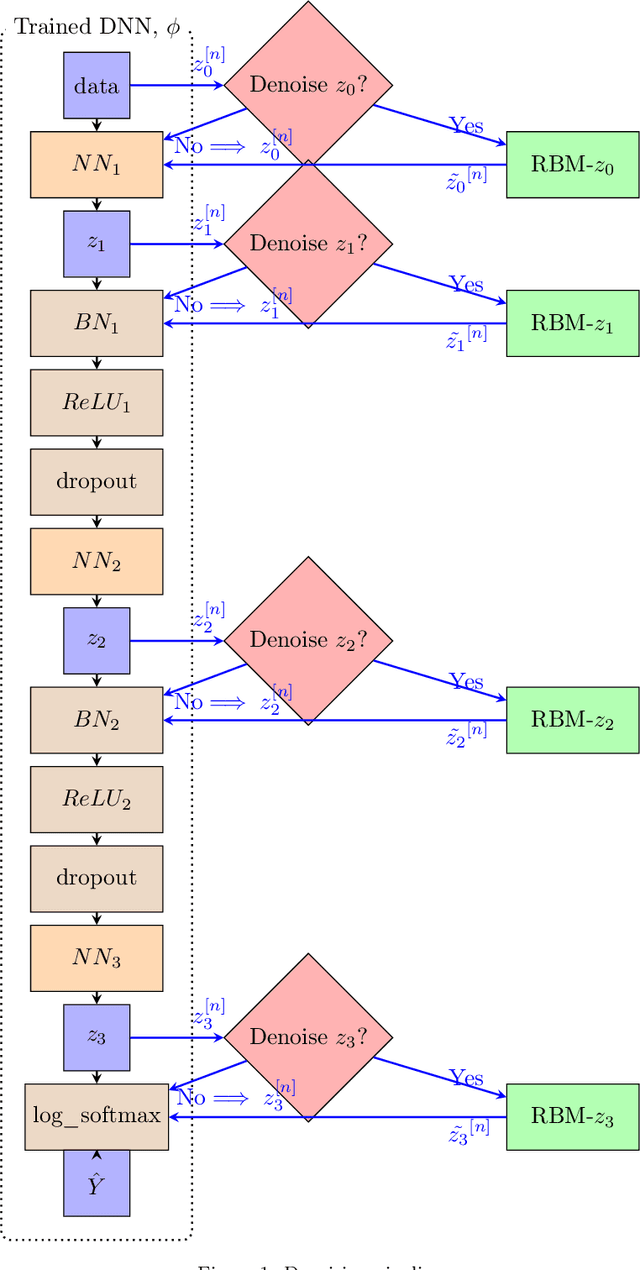
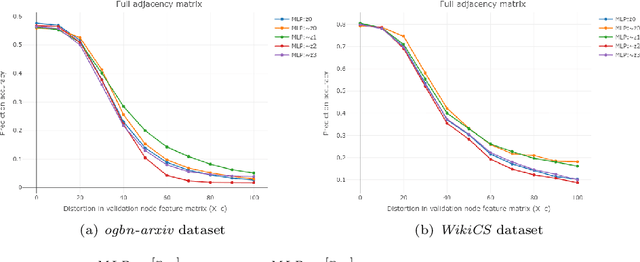
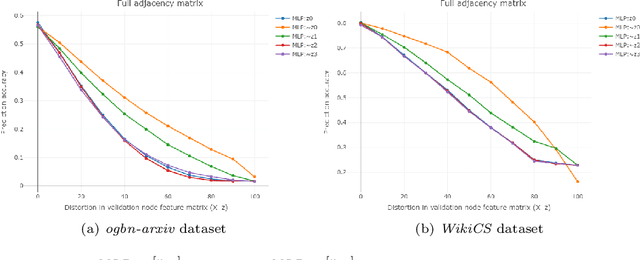
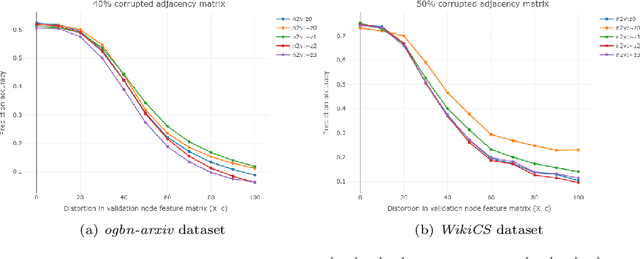
We propose a model-agnostic pipeline to recover graph signals from an expert system by exploiting the content addressable memory property of restricted Boltzmann machine and the representational ability of a neural network. The proposed pipeline requires the deep neural network that is trained on a downward machine learning task with clean data, data which is free from any form of corruption or incompletion. We show that denoising the representations learned by the deep neural networks is usually more effective than denoising the data itself. Although this pipeline can deal with noise in any dataset, it is particularly effective for graph-structured datasets.
Detecting Social Media Manipulation in Low-Resource Languages
Nov 10, 2020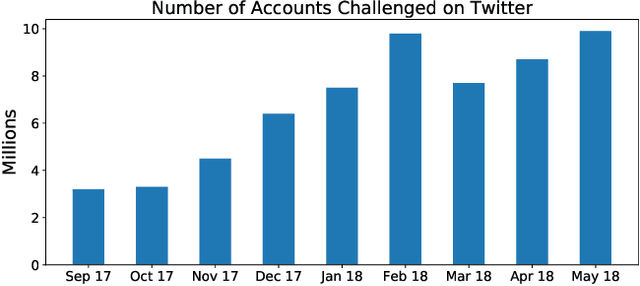
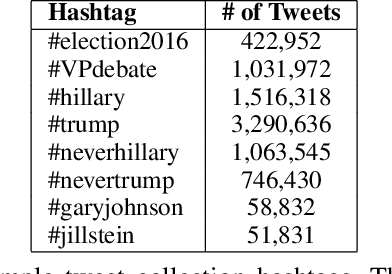
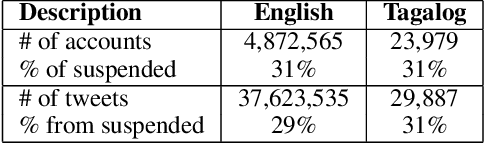
Social media have been deliberately used for malicious purposes, including political manipulation and disinformation. Most research focuses on high-resource languages. However, malicious actors share content across countries and languages, including low-resource ones. Here, we investigate whether and to what extent malicious actors can be detected in low-resource language settings. We discovered that a high number of accounts posting in Tagalog were suspended as part of Twitter's crackdown on interference operations after the 2016 US Presidential election. By combining text embedding and transfer learning, our framework can detect, with promising accuracy, malicious users posting in Tagalog without any prior knowledge or training on malicious content in that language. We first learn an embedding model for each language, namely a high-resource language (English) and a low-resource one (Tagalog), independently. Then, we learn a mapping between the two latent spaces to transfer the detection model. We demonstrate that the proposed approach significantly outperforms state-of-the-art models, including BERT, and yields marked advantages in settings with very limited training data-the norm when dealing with detecting malicious activity in online platforms.
Leveraging Clickstream Trajectories to Reveal Low-Quality Workers in Crowdsourced Forecasting Platforms
Sep 04, 2020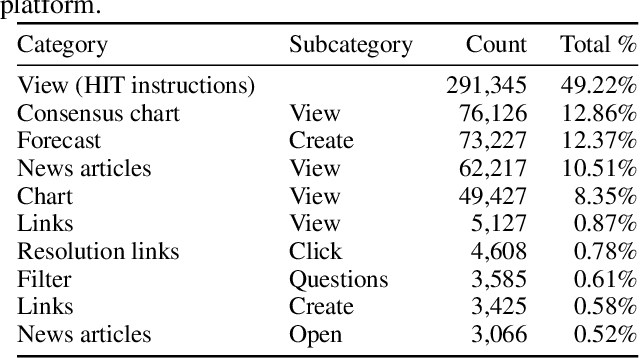
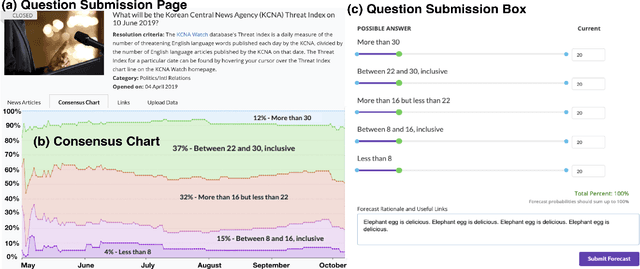
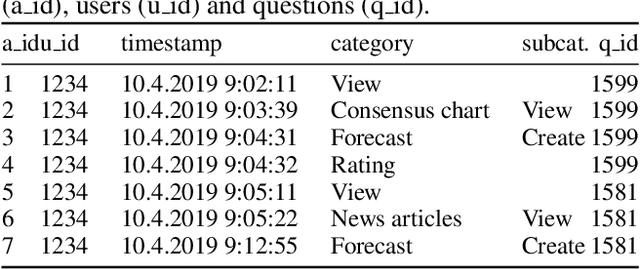
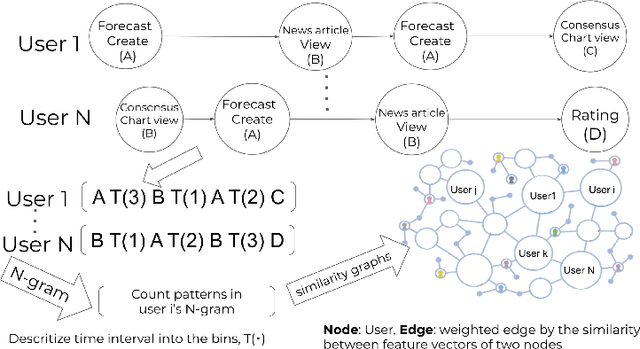
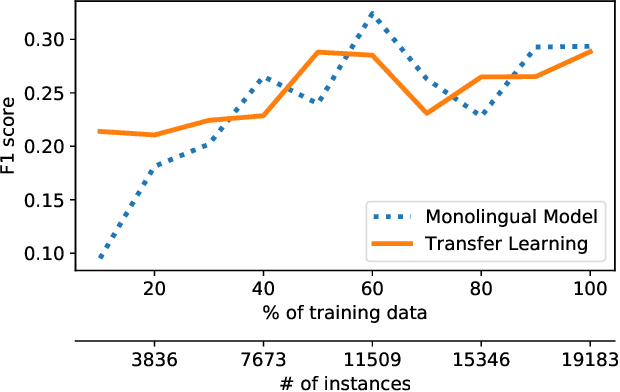
Crowdwork often entails tackling cognitively-demanding and time-consuming tasks. Crowdsourcing can be used for complex annotation tasks, from medical imaging to geospatial data, and such data powers sensitive applications, such as health diagnostics or autonomous driving. However, the existence and prevalence of underperforming crowdworkers is well-recognized, and can pose a threat to the validity of crowdsourcing. In this study, we propose the use of a computational framework to identify clusters of underperforming workers using clickstream trajectories. We focus on crowdsourced geopolitical forecasting. The framework can reveal different types of underperformers, such as workers with forecasts whose accuracy is far from the consensus of the crowd, those who provide low-quality explanations for their forecasts, and those who simply copy-paste their forecasts from other users. Our study suggests that clickstream clustering and analysis are fundamental tools to diagnose the performance of crowdworkers in platforms leveraging the wisdom of crowds.
Learning to Reason in Round-based Games: Multi-task Sequence Generation for Purchasing Decision Making in First-person Shooters
Aug 12, 2020
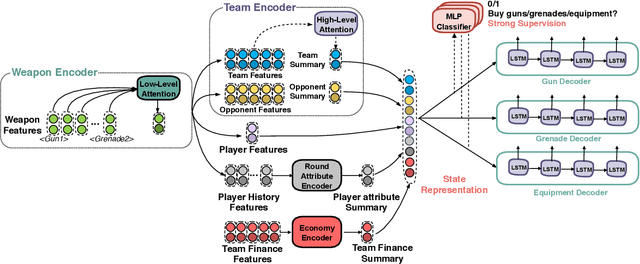

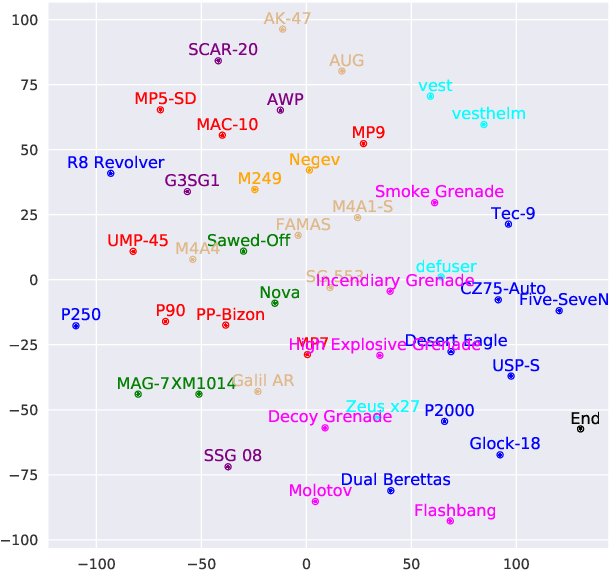
Sequential reasoning is a complex human ability, with extensive previous research focusing on gaming AI in a single continuous game, round-based decision makings extending to a sequence of games remain less explored. Counter-Strike: Global Offensive (CS:GO), as a round-based game with abundant expert demonstrations, provides an excellent environment for multi-player round-based sequential reasoning. In this work, we propose a Sequence Reasoner with Round Attribute Encoder and Multi-Task Decoder to interpret the strategies behind the round-based purchasing decisions. We adopt few-shot learning to sample multiple rounds in a match, and modified model agnostic meta-learning algorithm Reptile for the meta-learning loop. We formulate each round as a multi-task sequence generation problem. Our state representations combine action encoder, team encoder, player features, round attribute encoder, and economy encoders to help our agent learn to reason under this specific multi-player round-based scenario. A complete ablation study and comparison with the greedy approach certify the effectiveness of our model. Our research will open doors for interpretable AI for understanding episodic and long-term purchasing strategies beyond the gaming community.
Detecting multi-timescale consumption patterns from receipt data: A non-negative tensor factorization approach
Apr 28, 2020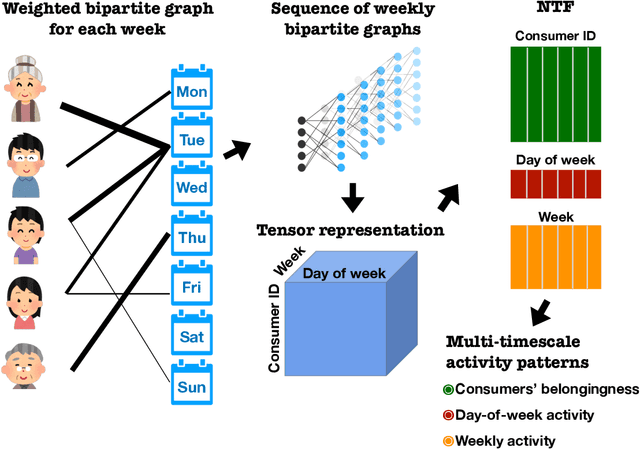
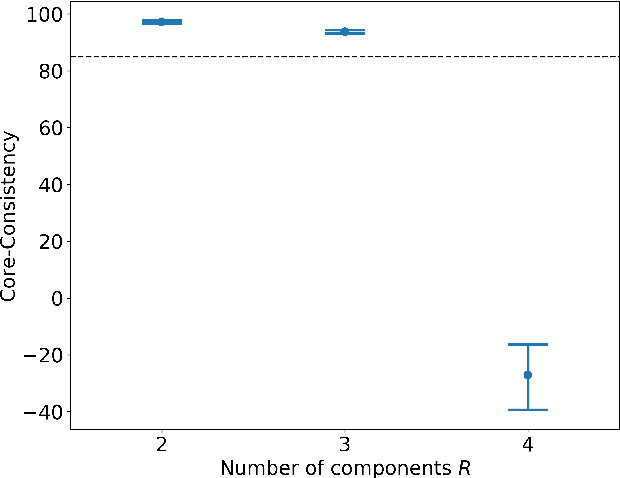
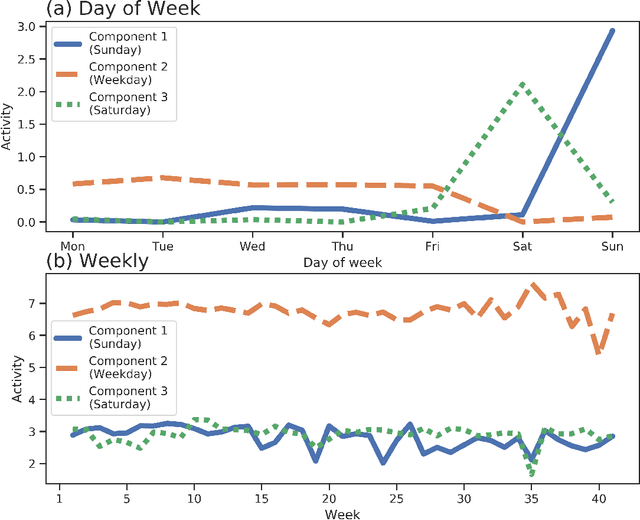

Understanding consumer behavior is an important task, not only for developing marketing strategies but also for the management of economic policies. Detecting consumption patterns, however, is a high-dimensional problem in which various factors that would affect consumers' behavior need to be considered, such as consumers' demographics, circadian rhythm, seasonal cycles, etc. Here, we develop a method to extract multi-timescale expenditure patterns of consumers from a large dataset of scanned receipts. We use a non-negative tensor factorization (NTF) to detect intra- and inter-week consumption patterns at one time. The proposed method allows us to characterize consumers based on their consumption patterns that are correlated over different timescales.
Don't Feed the Troll: Detecting Troll Behavior via Inverse Reinforcement Learning
Jan 28, 2020
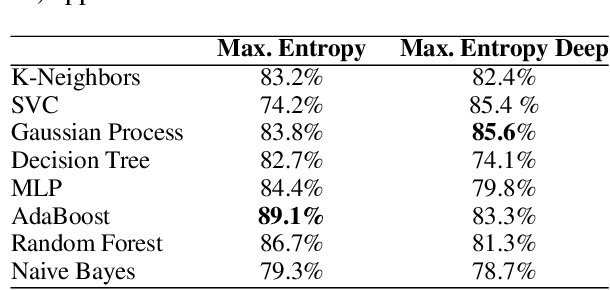
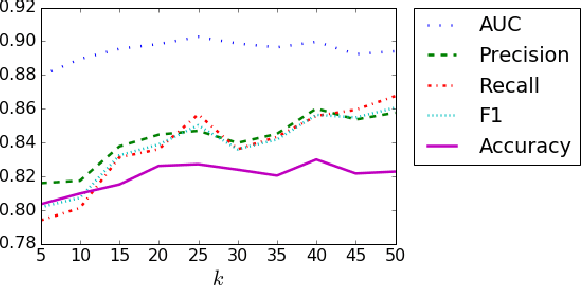
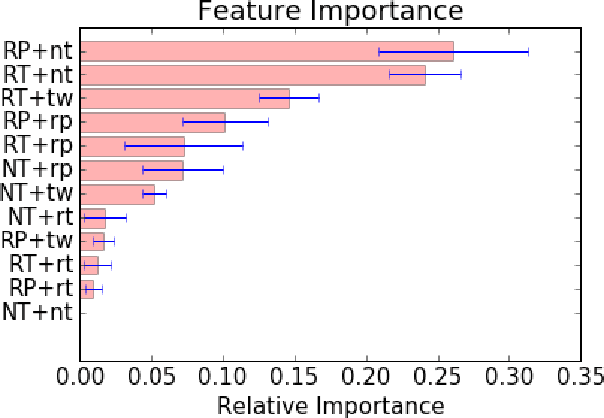
Since the 2016 US Presidential election, social media abuse has been eliciting massive concern in the academic community and beyond. Preventing and limiting the malicious activity of users, such as trolls and bots, in their manipulation campaigns is of paramount importance for the integrity of democracy, public health, and more. However, the automated detection of troll accounts is an open challenge. In this work, we propose an approach based on Inverse Reinforcement Learning (IRL) to capture troll behavior and identify troll accounts. We employ IRL to infer a set of online incentives that may steer user behavior, which in turn highlights behavioral differences between troll and non-troll accounts, enabling their accurate classification. We report promising results: the IRL-based approach is able to accurately detect troll accounts (AUC=89.1%). The differences in the predictive features between the two classes of accounts enables a principled understanding of the distinctive behaviors reflecting the incentives trolls and non-trolls respond to.