 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTracking Adaptation Time: Metrics for Temporal Distribution Shift
Apr 08, 2026Evaluating robustness under temporal distribution shift remains an open challenge. Existing metrics quantify the average decline in performance, but fail to capture how models adapt to evolving data. As a result, temporal degradation is often misinterpreted: when accuracy declines, it is unclear whether the model is failing to adapt or whether the data itself has become inherently more challenging to learn. In this work, we propose three complementary metrics to distinguish adaptation from intrinsic difficulty in the data. Together, these metrics provide a dynamic and interpretable view of model behavior under temporal distribution shift. Results show that our metrics uncover adaptation patterns hidden by existing analysis, offering a richer understanding of temporal robustness in evolving environments.
LLM-Enhanced Semantic Data Integration of Electronic Component Qualifications in the Aerospace Domain
Mar 20, 2026Large manufacturing companies face challenges in information retrieval due to data silos maintained by different departments, leading to inconsistencies and misalignment across databases. This paper presents an experience in integrating and retrieving qualification data for electronic components used in satellite board design. Due to data silos, designers cannot immediately determine the qualification status of individual components. However, this process is critical during the planning phase, when assembly drawings are issued before production, to optimize new qualifications and avoid redundant efforts. To address this, we propose a pipeline that uses Virtual Knowledge Graphs for a unified view over heterogeneous data sources and LLMs to enhance retrieval and reduce manual effort in data cleansing. The retrieval of qualifications is then performed through an Ontology-based Data Access approach for structured queries and a vector search mechanism for retrieving qualifications based on similar textual properties. We perform a comparative cost-benefit analysis, demonstrating that the proposed pipeline also outperforms approaches relying solely on LLMs, such as Retrieval-Augmented Generation (RAG), in terms of long-term efficiency.
MAcPNN: Mutual Assisted Learning on Data Streams with Temporal Dependence
Mar 09, 2026Internet of Things (IoT) Analytics often involves applying machine learning (ML) models on data streams. In such scenarios, traditional ML paradigms face obstacles related to continuous learning while dealing with concept drifts, temporal dependence, and avoiding forgetting. Moreover, in IoT, different edge devices build up a network. When learning models on those devices, connecting them could be useful in improving performance and reusing others' knowledge. This work proposes Mutual Assisted Learning, a learning paradigm grounded on Vygotsky's popular Sociocultural Theory of Cognitive Development. Each device is autonomous and does not need a central orchestrator. Whenever it degrades its performance due to a concept drift, it asks for assistance from others and decides whether their knowledge is useful for solving the new problem. This way, the number of connections is drastically reduced compared to the classical Federated Learning approaches, where the devices communicate at each training round. Every device is equipped with a Continuous Progressive Neural Network (cPNN) to handle the dynamic nature of data streams. We call this implementation Mutual Assisted cPNN (MAcPNN). To implement it, we allow cPNNs for single data point predictions and apply quantization to reduce the memory footprint. Experimental results prove the effectiveness of MAcPNN in boosting performance on synthetic and real data streams.
Don't Look Back in Anger: MAGIC Net for Streaming Continual Learning with Temporal Dependence
Mar 09, 2026Concept drift, temporal dependence, and catastrophic forgetting represent major challenges when learning from data streams. While Streaming Machine Learning and Continual Learning (CL) address these issues separately, recent efforts in Streaming Continual Learning (SCL) aim to unify them. In this work, we introduce MAGIC Net, a novel SCL approach that integrates CL-inspired architectural strategies with recurrent neural networks to tame temporal dependence. MAGIC Net continuously learns, looks back at past knowledge by applying learnable masks over frozen weights, and expands its architecture when necessary. It performs all operations online, ensuring inference availability at all times. Experiments on synthetic and real-world streams show that it improves adaptation to new concepts, limits memory usage, and mitigates forgetting.
cPNN: Continuous Progressive Neural Networks for Evolving Streaming Time Series
Mar 03, 2026Dealing with an unbounded data stream involves overcoming the assumption that data is identically distributed and independent. A data stream can, in fact, exhibit temporal dependencies (i.e., be a time series), and data can change distribution over time (concept drift). The two problems are deeply discussed, and existing solutions address them separately: a joint solution is absent. In addition, learning multiple concepts implies remembering the past (a.k.a. avoiding catastrophic forgetting in Neural Networks' terminology). This work proposes Continuous Progressive Neural Networks (cPNN), a solution that tames concept drifts, handles temporal dependencies, and bypasses catastrophic forgetting. cPNN is a continuous version of Progressive Neural Networks, a methodology for remembering old concepts and transferring past knowledge to fit the new concepts quickly. We base our method on Recurrent Neural Networks and exploit the Stochastic Gradient Descent applied to data streams with temporal dependencies. Results of an ablation study show a quick adaptation of cPNN to new concepts and robustness to drifts.
A Practical Guide to Streaming Continual Learning
Mar 02, 2026Continual Learning (CL) and Streaming Machine Learning (SML) study the ability of agents to learn from a stream of non-stationary data. Despite sharing some similarities, they address different and complementary challenges. While SML focuses on rapid adaptation after changes (concept drifts), CL aims to retain past knowledge when learning new tasks. After a brief introduction to CL and SML, we discuss Streaming Continual Learning (SCL), an emerging paradigm providing a unifying solution to real-world problems, which may require both SML and CL abilities. We claim that SCL can i) connect the CL and SML communities, motivating their work towards the same goal, and ii) foster the design of hybrid approaches that can quickly adapt to new information (as in SML) without forgetting previous knowledge (as in CL). We conclude the paper with a motivating example and a set of experiments, highlighting the need for SCL by showing how CL and SML alone struggle in achieving rapid adaptation and knowledge retention.
Integrating Large Language Models and Knowledge Graphs for Extraction and Validation of Textual Test Data
Aug 03, 2024Aerospace manufacturing companies, such as Thales Alenia Space, design, develop, integrate, verify, and validate products characterized by high complexity and low volume. They carefully document all phases for each product but analyses across products are challenging due to the heterogeneity and unstructured nature of the data in documents. In this paper, we propose a hybrid methodology that leverages Knowledge Graphs (KGs) in conjunction with Large Language Models (LLMs) to extract and validate data contained in these documents. We consider a case study focused on test data related to electronic boards for satellites. To do so, we extend the Semantic Sensor Network ontology. We store the metadata of the reports in a KG, while the actual test results are stored in parquet accessible via a Virtual Knowledge Graph. The validation process is managed using an LLM-based approach. We also conduct a benchmarking study to evaluate the performance of state-of-the-art LLMs in executing this task. Finally, we analyze the costs and benefits of automating preexisting processes of manual data extraction and validation for subsequent cross-report analyses.
Rebalancing Learning on Evolving Data Streams
Nov 17, 2019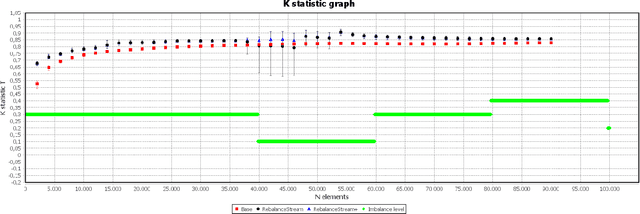
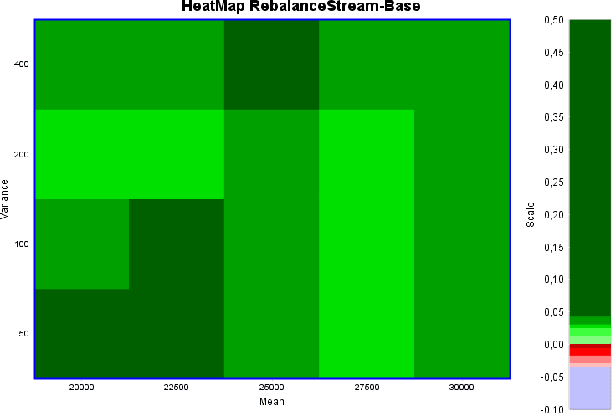
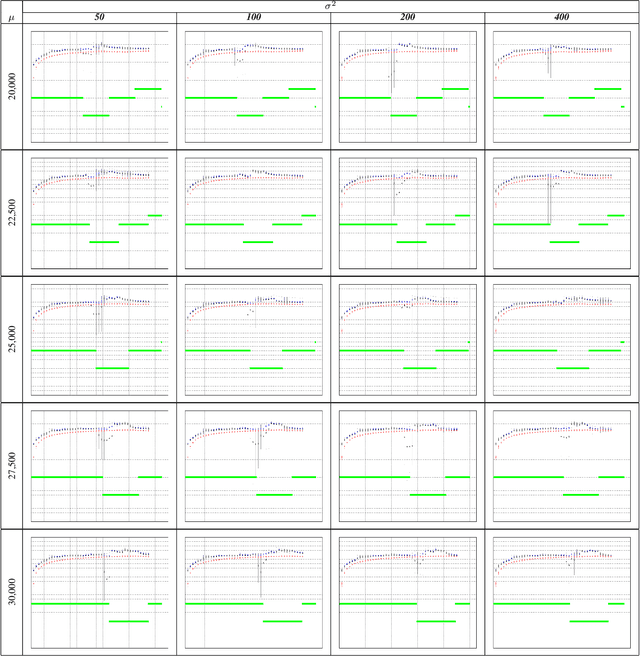
Nowadays, every device connected to the Internet generates an ever-growing stream of data (formally, unbounded). Machine Learning on unbounded data streams is a grand challenge due to its resource constraints. In fact, standard machine learning techniques are not able to deal with data whose statistics is subject to gradual or sudden changes without any warning. Massive Online Analysis (MOA) is the collective name, as well as a software library, for new learners that are able to manage data streams. In this paper, we present a research study on streaming rebalancing. Indeed, data streams can be imbalanced as static data, but there is not a method to rebalance them incrementally, one element at a time. For this reason we propose a new streaming approach able to rebalance data streams online. Our new methodology is evaluated against some synthetically generated datasets using prequential evaluation in order to demonstrate that it outperforms the existing approaches.