 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Practical Guide to Streaming Continual Learning
Mar 02, 2026Continual Learning (CL) and Streaming Machine Learning (SML) study the ability of agents to learn from a stream of non-stationary data. Despite sharing some similarities, they address different and complementary challenges. While SML focuses on rapid adaptation after changes (concept drifts), CL aims to retain past knowledge when learning new tasks. After a brief introduction to CL and SML, we discuss Streaming Continual Learning (SCL), an emerging paradigm providing a unifying solution to real-world problems, which may require both SML and CL abilities. We claim that SCL can i) connect the CL and SML communities, motivating their work towards the same goal, and ii) foster the design of hybrid approaches that can quickly adapt to new information (as in SML) without forgetting previous knowledge (as in CL). We conclude the paper with a motivating example and a set of experiments, highlighting the need for SCL by showing how CL and SML alone struggle in achieving rapid adaptation and knowledge retention.
Rebalancing Learning on Evolving Data Streams
Nov 17, 2019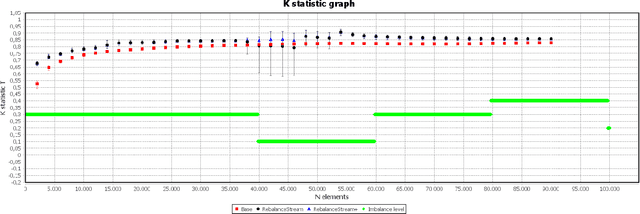
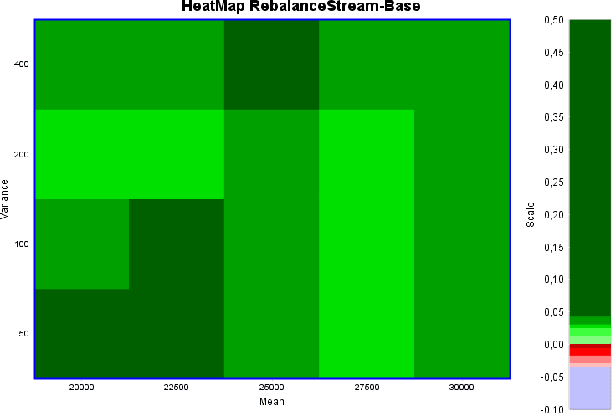
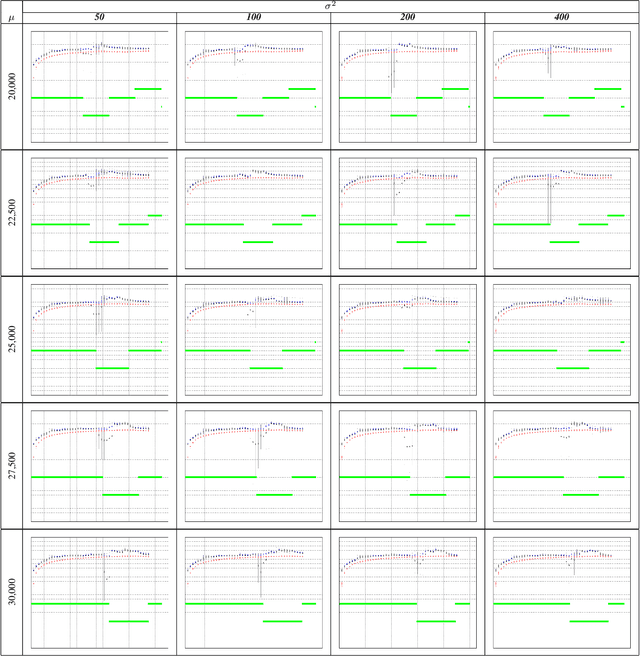
Nowadays, every device connected to the Internet generates an ever-growing stream of data (formally, unbounded). Machine Learning on unbounded data streams is a grand challenge due to its resource constraints. In fact, standard machine learning techniques are not able to deal with data whose statistics is subject to gradual or sudden changes without any warning. Massive Online Analysis (MOA) is the collective name, as well as a software library, for new learners that are able to manage data streams. In this paper, we present a research study on streaming rebalancing. Indeed, data streams can be imbalanced as static data, but there is not a method to rebalance them incrementally, one element at a time. For this reason we propose a new streaming approach able to rebalance data streams online. Our new methodology is evaluated against some synthetically generated datasets using prequential evaluation in order to demonstrate that it outperforms the existing approaches.