 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEgoPoseFormer: A Simple Baseline for Egocentric 3D Human Pose Estimation
Mar 26, 2024



We present EgoPoseFormer, a simple yet effective transformer-based model for stereo egocentric human pose estimation. The main challenge in egocentric pose estimation is overcoming joint invisibility, which is caused by self-occlusion or a limited field of view (FOV) of head-mounted cameras. Our approach overcomes this challenge by incorporating a two-stage pose estimation paradigm: in the first stage, our model leverages the global information to estimate each joint's coarse location, then in the second stage, it employs a DETR style transformer to refine the coarse locations by exploiting fine-grained stereo visual features. In addition, we present a deformable stereo operation to enable our transformer to effectively process multi-view features, which enables it to accurately localize each joint in the 3D world. We evaluate our method on the stereo UnrealEgo dataset and show it significantly outperforms previous approaches while being computationally efficient: it improves MPJPE by 27.4mm (45% improvement) with only 7.9% model parameters and 13.1% FLOPs compared to the state-of-the-art. Surprisingly, with proper training techniques, we find that even our first-stage pose proposal network can achieve superior performance compared to previous arts. We also show that our method can be seamlessly extended to monocular settings, which achieves state-of-the-art performance on the SceneEgo dataset, improving MPJPE by 25.5mm (21% improvement) compared to the best existing method with only 60.7% model parameters and 36.4% FLOPs.
WidthFormer: Toward Efficient Transformer-based BEV View Transformation
Jan 15, 2024



In this work, we present WidthFormer, a novel transformer-based Bird's-Eye-View (BEV) 3D detection method tailored for real-time autonomous-driving applications. WidthFormer is computationally efficient, robust and does not require any special engineering effort to deploy. In this work, we propose a novel 3D positional encoding mechanism capable of accurately encapsulating 3D geometric information, which enables our model to generate high-quality BEV representations with only a single transformer decoder layer. This mechanism is also beneficial for existing sparse 3D object detectors. Inspired by the recently-proposed works, we further improve our model's efficiency by vertically compressing the image features when serving as attention keys and values. We also introduce two modules to compensate for potential information loss due to feature compression. Experimental evaluation on the widely-used nuScenes 3D object detection benchmark demonstrates that our method outperforms previous approaches across different 3D detection architectures. More importantly, our model is highly efficient. For example, when using $256\times 704$ input images, it achieves 1.5 ms and 2.8 ms latency on NVIDIA 3090 GPU and Horizon Journey-5 computation solutions, respectively. Furthermore, WidthFormer also exhibits strong robustness to different degrees of camera perturbations. Our study offers valuable insights into the deployment of BEV transformation methods in real-world, complex road environments. Code is available at https://github.com/ChenhongyiYang/WidthFormer .
DLAS: An Exploration and Assessment of the Deep Learning Acceleration Stack
Nov 15, 2023Deep Neural Networks (DNNs) are extremely computationally demanding, which presents a large barrier to their deployment on resource-constrained devices. Since such devices are where many emerging deep learning applications lie (e.g., drones, vision-based medical technology), significant bodies of work from both the machine learning and systems communities have attempted to provide optimizations to accelerate DNNs. To help unify these two perspectives, in this paper we combine machine learning and systems techniques within the Deep Learning Acceleration Stack (DLAS), and demonstrate how these layers can be tightly dependent on each other with an across-stack perturbation study. We evaluate the impact on accuracy and inference time when varying different parameters of DLAS across two datasets, seven popular DNN architectures, four DNN compression techniques, three algorithmic primitives with sparse and dense variants, untuned and auto-scheduled code generation, and four hardware platforms. Our evaluation highlights how perturbations across DLAS parameters can cause significant variation and across-stack interactions. The highest level observation from our evaluation is that the model size, accuracy, and inference time are not guaranteed to be correlated. Overall we make 13 key observations, including that speedups provided by compression techniques are very hardware dependent, and that compiler auto-tuning can significantly alter what the best algorithm to use for a given configuration is. With DLAS, we aim to provide a reference framework to aid machine learning and systems practitioners in reasoning about the context in which their respective DNN acceleration solutions exist in. With our evaluation strongly motivating the need for co-design, we believe that DLAS can be a valuable concept for exploring the next generation of co-designed accelerated deep learning solutions.
Generate Your Own Scotland: Satellite Image Generation Conditioned on Maps
Aug 31, 2023Despite recent advancements in image generation, diffusion models still remain largely underexplored in Earth Observation. In this paper we show that state-of-the-art pretrained diffusion models can be conditioned on cartographic data to generate realistic satellite images. We provide two large datasets of paired OpenStreetMap images and satellite views over the region of Mainland Scotland and the Central Belt. We train a ControlNet model and qualitatively evaluate the results, demonstrating that both image quality and map fidelity are possible. Finally, we provide some insights on the opportunities and challenges of applying these models for remote sensing. Our model weights and code for creating the dataset are publicly available at https://github.com/miquel-espinosa/map-sat.
GPViT: A High Resolution Non-Hierarchical Vision Transformer with Group Propagation
Dec 13, 2022We present the Group Propagation Vision Transformer (GPViT): a novel nonhierarchical (i.e. non-pyramidal) transformer model designed for general visual recognition with high-resolution features. High-resolution features (or tokens) are a natural fit for tasks that involve perceiving fine-grained details such as detection and segmentation, but exchanging global information between these features is expensive in memory and computation because of the way self-attention scales. We provide a highly efficient alternative Group Propagation Block (GP Block) to exchange global information. In each GP Block, features are first grouped together by a fixed number of learnable group tokens; we then perform Group Propagation where global information is exchanged between the grouped features; finally, global information in the updated grouped features is returned back to the image features through a transformer decoder. We evaluate GPViT on a variety of visual recognition tasks including image classification, semantic segmentation, object detection, and instance segmentation. Our method achieves significant performance gains over previous works across all tasks, especially on tasks that require high-resolution outputs, for example, our GPViT-L3 outperforms Swin Transformer-B by 2.0 mIoU on ADE20K semantic segmentation with only half as many parameters. Code and pre-trained models are available at https://github.com/ChenhongyiYang/GPViT .
Plug and Play Active Learning for Object Detection
Nov 21, 2022Annotating data for supervised learning is expensive and tedious, and we want to do as little of it as possible. To make the most of a given "annotation budget" we can turn to active learning (AL) which aims to identify the most informative samples in a dataset for annotation. Active learning algorithms are typically uncertainty-based or diversity-based. Both have seen success in image classification, but fall short when it comes to object detection. We hypothesise that this is because: (1) it is difficult to quantify uncertainty for object detection as it consists of both localisation and classification, where some classes are harder to localise, and others are harder to classify; (2) it is difficult to measure similarities for diversity-based AL when images contain different numbers of objects. We propose a two-stage active learning algorithm Plug and Play Active Learning (PPAL) that overcomes these difficulties. It consists of (1) Difficulty Calibrated Uncertainty Sampling, in which we used a category-wise difficulty coefficient that takes both classification and localisation into account to re-weight object uncertainties for uncertainty-based sampling; (2) Category Conditioned Matching Similarity to compute the similarities of multi-instance images as ensembles of their instance similarities. PPAL is highly generalisable because it makes no change to model architectures or detector training pipelines. We benchmark PPAL on the MS-COCO and Pascal VOC datasets using different detector architectures and show that our method outperforms the prior state-of-the-art. Code is available at https://github.com/ChenhongyiYang/PPAL
Prediction-Guided Distillation for Dense Object Detection
Mar 10, 2022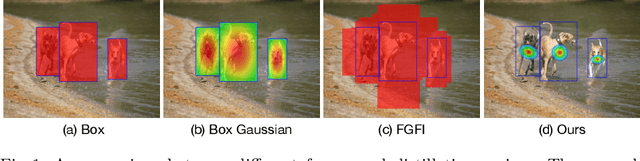
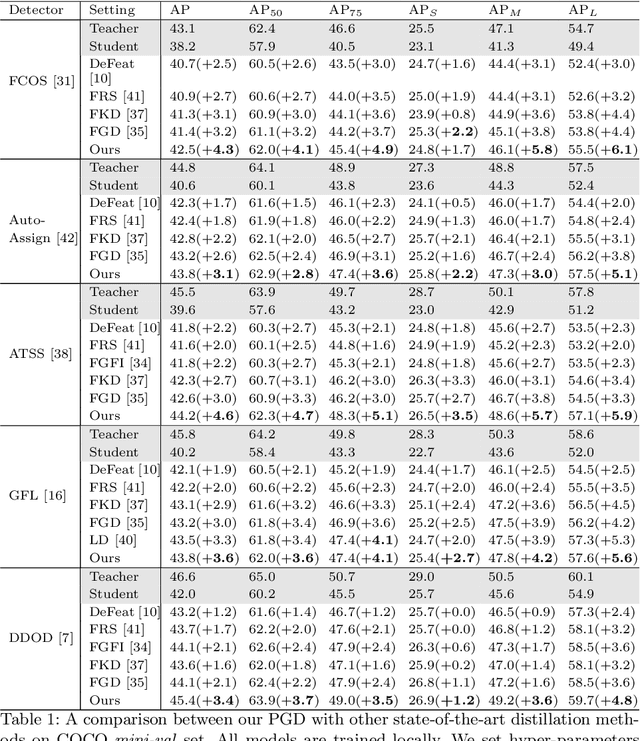

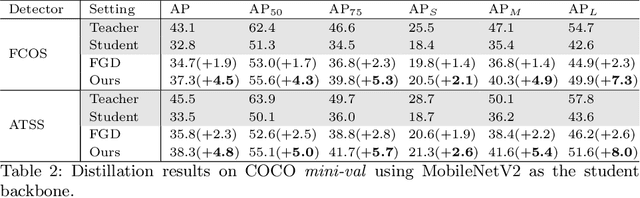
Real-world object detection models should be cheap and accurate. Knowledge distillation (KD) can boost the accuracy of a small, cheap detection model by leveraging useful information from a larger teacher model. However, a key challenge is identifying the most informative features produced by the teacher for distillation. In this work, we show that only a very small fraction of features within a ground-truth bounding box are responsible for a teacher's high detection performance. Based on this, we propose Prediction-Guided Distillation (PGD), which focuses distillation on these key predictive regions of the teacher and yields considerable gains in performance over many existing KD baselines. In addition, we propose an adaptive weighting scheme over the key regions to smooth out their influence and achieve even better performance. Our proposed approach outperforms current state-of-the-art KD baselines on a variety of advanced one-stage detection architectures. Specifically, on the COCO dataset, our method achieves between +3.1% and +4.6% AP improvement using ResNet-101 and ResNet-50 as the teacher and student backbones, respectively. On the CrowdHuman dataset, we achieve +3.2% and +2.0% improvements in MR and AP, also using these backbones. Our code is available at https://github.com/ChenhongyiYang/PGD.
Contrastive Object-level Pre-training with Spatial Noise Curriculum Learning
Nov 29, 2021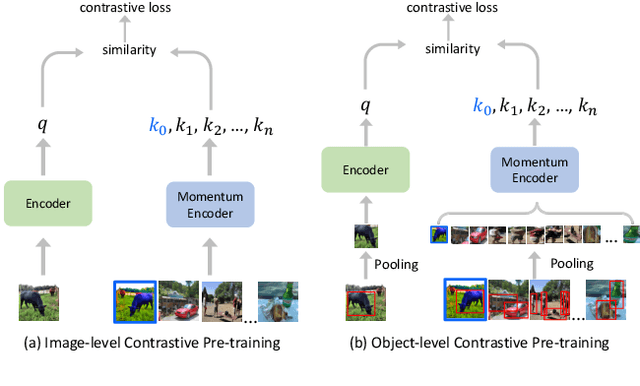
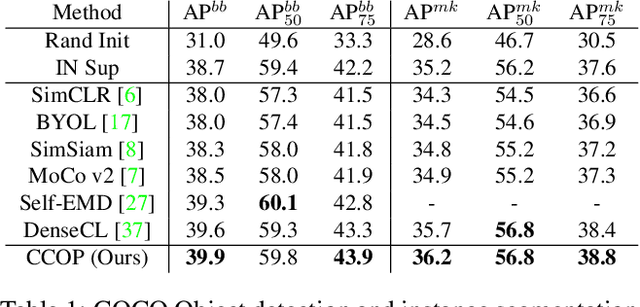
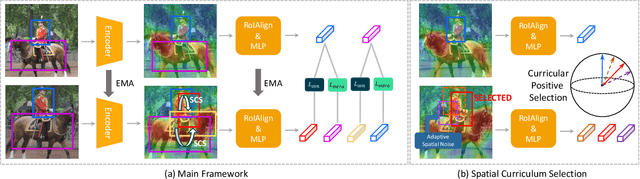
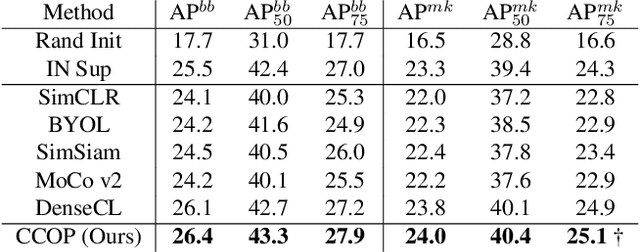
The goal of contrastive learning based pre-training is to leverage large quantities of unlabeled data to produce a model that can be readily adapted downstream. Current approaches revolve around solving an image discrimination task: given an anchor image, an augmented counterpart of that image, and some other images, the model must produce representations such that the distance between the anchor and its counterpart is small, and the distances between the anchor and the other images are large. There are two significant problems with this approach: (i) by contrasting representations at the image-level, it is hard to generate detailed object-sensitive features that are beneficial to downstream object-level tasks such as instance segmentation; (ii) the augmentation strategy of producing an augmented counterpart is fixed, making learning less effective at the later stages of pre-training. In this work, we introduce Curricular Contrastive Object-level Pre-training (CCOP) to tackle these problems: (i) we use selective search to find rough object regions and use them to build an inter-image object-level contrastive loss and an intra-image object-level discrimination loss into our pre-training objective; (ii) we present a curriculum learning mechanism that adaptively augments the generated regions, which allows the model to consistently acquire a useful learning signal, even in the later stages of pre-training. Our experiments show that our approach improves on the MoCo v2 baseline by a large margin on multiple object-level tasks when pre-training on multi-object scene image datasets. Code is available at https://github.com/ChenhongyiYang/CCOP.
Neural Architecture Search as Program Transformation Exploration
Feb 12, 2021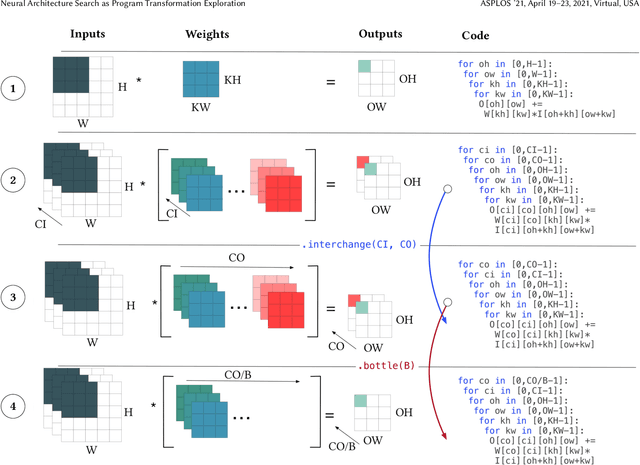
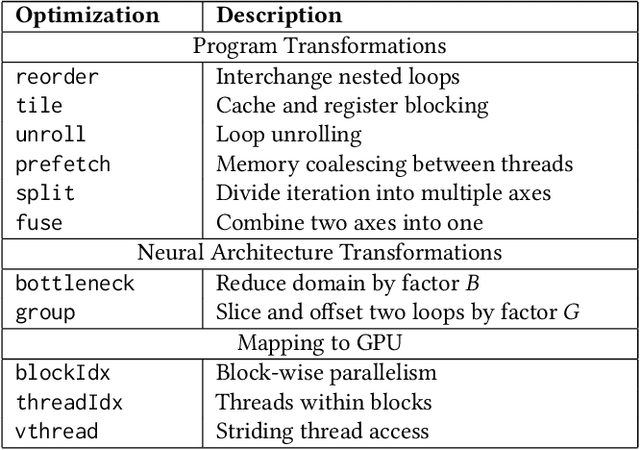
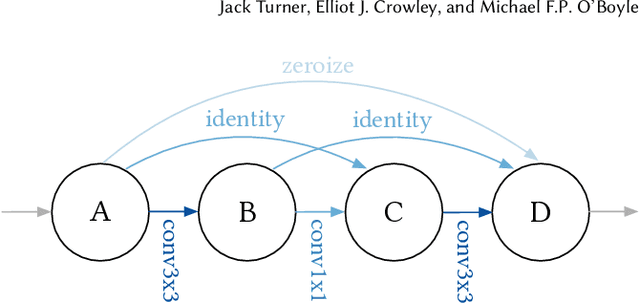
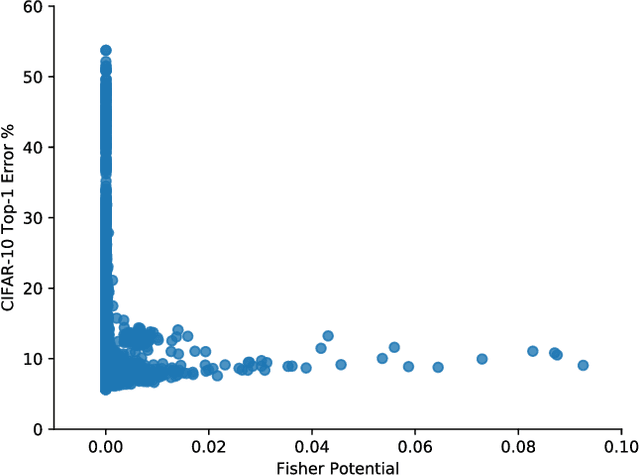
Improving the performance of deep neural networks (DNNs) is important to both the compiler and neural architecture search (NAS) communities. Compilers apply program transformations in order to exploit hardware parallelism and memory hierarchy. However, legality concerns mean they fail to exploit the natural robustness of neural networks. In contrast, NAS techniques mutate networks by operations such as the grouping or bottlenecking of convolutions, exploiting the resilience of DNNs. In this work, we express such neural architecture operations as program transformations whose legality depends on a notion of representational capacity. This allows them to be combined with existing transformations into a unified optimization framework. This unification allows us to express existing NAS operations as combinations of simpler transformations. Crucially, it allows us to generate and explore new tensor convolutions. We prototyped the combined framework in TVM and were able to find optimizations across different DNNs, that significantly reduce inference time - over 3$\times$ in the majority of cases. Furthermore, our scheme dramatically reduces NAS search time. Code is available at~\href{https://github.com/jack-willturner/nas-as-program-transformation-exploration}{this https url}.
Optimizing Grouped Convolutions on Edge Devices
Jun 17, 2020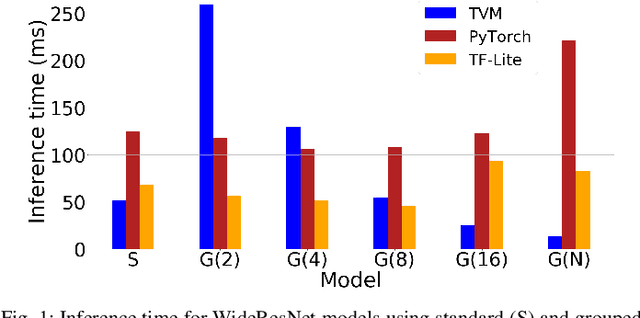
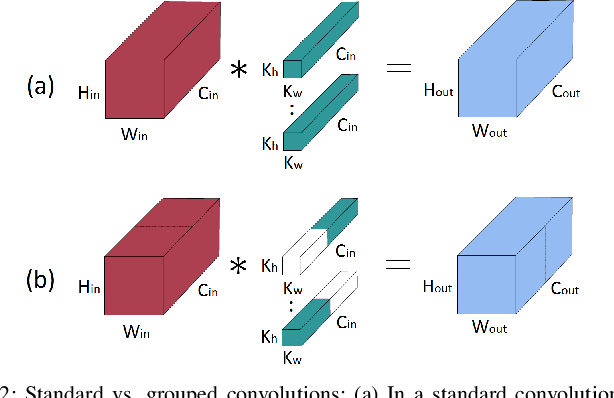
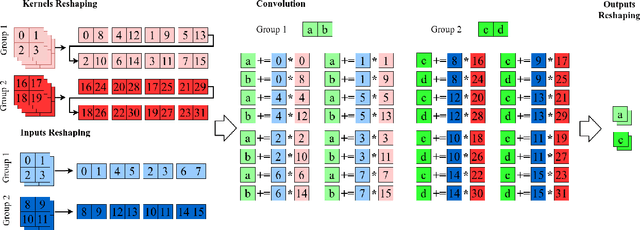
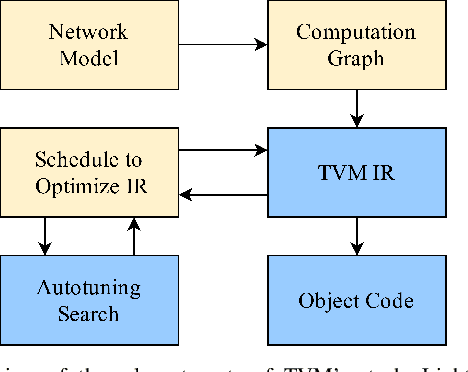
When deploying a deep neural network on constrained hardware, it is possible to replace the network's standard convolutions with grouped convolutions. This allows for substantial memory savings with minimal loss of accuracy. However, current implementations of grouped convolutions in modern deep learning frameworks are far from performing optimally in terms of speed. In this paper we propose Grouped Spatial Pack Convolutions (GSPC), a new implementation of grouped convolutions that outperforms existing solutions. We implement GSPC in TVM, which provides state-of-the-art performance on edge devices. We analyze a set of networks utilizing different types of grouped convolutions and evaluate their performance in terms of inference time on several edge devices. We observe that our new implementation scales well with the number of groups and provides the best inference times in all settings, improving the existing implementations of grouped convolutions in TVM, PyTorch and TensorFlow Lite by 3.4x, 8x and 4x on average respectively. Code is available at https://github.com/gecLAB/tvm-GSPC/