 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConfounder Detection via Treatment Intent: A New Observational Study Design
May 26, 2026Understanding the effects of interventions is central to scientific progress, with randomized controlled trials (RCTs) regarded as the gold standard for causal inference in many applied fields. However, RCTs are costly, time-consuming, and often constrained by ethical or practical limitations, motivating the need for causal methods able to draw conclusions from observational data. While such data is collected at ever larger scale, making its use for causal inference is often hindered by the fact that not all variables affecting treatment allocation and the outcome are observed: an issue known as unobserved confounding. In this paper, we introduce a new study design called confounder detection via treatment intent. The idea is to query a human expert who makes treatment decisions, and ask them to compare pairs of units proposed by a principled matching strategy, with the goal of eliciting unobserved variables that explain why treatment decisions differ. We provide a theoretical basis for such a procedure, ascertaining conditions under which such a study design may elicit unobserved confounders. Building on this newly established foundations, we study treatment effects of interventions in the intensive care unit (ICU). First, we show empirical evidence strongly indicating that electronic health records (EHRs) collected in ICUs are subject to unobserved confounding. By using clinical text notes as a proxy for physicians' knowledge and leveraging natural language processing, we provide a proof of concept for our methodology in a semi-synthetic environment with a known ground truth.
An Algorithmic Approach for Causal Health Equity: A Look at Race Differentials in Intensive Care Unit (ICU) Outcomes
Jan 09, 2025



The new era of large-scale data collection and analysis presents an opportunity for diagnosing and understanding the causes of health inequities. In this study, we describe a framework for systematically analyzing health disparities using causal inference. The framework is illustrated by investigating racial and ethnic disparities in intensive care unit (ICU) outcome between majority and minority groups in Australia (Indigenous vs. Non-Indigenous) and the United States (African-American vs. White). We demonstrate that commonly used statistical measures for quantifying inequity are insufficient, and focus on attributing the observed disparity to the causal mechanisms that generate it. We find that minority patients are younger at admission, have worse chronic health, are more likely to be admitted for urgent and non-elective reasons, and have higher illness severity. At the same time, however, we find a protective direct effect of belonging to a minority group, with minority patients showing improved survival compared to their majority counterparts, with all other variables kept equal. We demonstrate that this protective effect is related to the increased probability of being admitted to ICU, with minority patients having an increased risk of ICU admission. We also find that minority patients, while showing improved survival, are more likely to be readmitted to ICU. Thus, due to worse access to primary health care, minority patients are more likely to end up in ICU for preventable conditions, causing a reduction in the mortality rates and creating an effect that appears to be protective. Since the baseline risk of ICU admission may serve as proxy for lack of access to primary care, we developed the Indigenous Intensive Care Equity (IICE) Radar, a monitoring system for tracking the over-utilization of ICU resources by the Indigenous population of Australia across geographical areas.
Interaction Testing in Variation Analysis
Nov 13, 2024Relationships of cause and effect are of prime importance for explaining scientific phenomena. Often, rather than just understanding the effects of causes, researchers also wish to understand how a cause $X$ affects an outcome $Y$ mechanistically -- i.e., what are the causal pathways that are activated between $X$ and $Y$. For analyzing such questions, a range of methods has been developed over decades under the rubric of causal mediation analysis. Traditional mediation analysis focuses on decomposing the average treatment effect (ATE) into direct and indirect effects, and therefore focuses on the ATE as the central quantity. This corresponds to providing explanations for associations in the interventional regime, such as when the treatment $X$ is randomized. Commonly, however, it is of interest to explain associations in the observational regime, and not just in the interventional regime. In this paper, we introduce \text{variation analysis}, an extension of mediation analysis that focuses on the total variation (TV) measure between $X$ and $Y$, written as $\mathrm{E}[Y \mid X=x_1] - \mathrm{E}[Y \mid X=x_0]$. The TV measure encompasses both causal and confounded effects, as opposed to the ATE which only encompasses causal (direct and mediated) variations. In this way, the TV measure is suitable for providing explanations in the natural regime and answering questions such as ``why is $X$ associated with $Y$?''. Our focus is on decomposing the TV measure, in a way that explicitly includes direct, indirect, and confounded variations. Furthermore, we also decompose the TV measure to include interaction terms between these different pathways. Subsequently, interaction testing is introduced, involving hypothesis tests to determine if interaction terms are significantly different from zero. If interactions are not significant, more parsimonious decompositions of the TV measure can be used.
Mind the Gap: A Causal Perspective on Bias Amplification in Prediction & Decision-Making
May 24, 2024Investigating fairness and equity of automated systems has become a critical field of inquiry. Most of the literature in fair machine learning focuses on defining and achieving fairness criteria in the context of prediction, while not explicitly focusing on how these predictions may be used later on in the pipeline. For instance, if commonly used criteria, such as independence or sufficiency, are satisfied for a prediction score $S$ used for binary classification, they need not be satisfied after an application of a simple thresholding operation on $S$ (as commonly used in practice). In this paper, we take an important step to address this issue in numerous statistical and causal notions of fairness. We introduce the notion of a margin complement, which measures how much a prediction score $S$ changes due to a thresholding operation. We then demonstrate that the marginal difference in the optimal 0/1 predictor $\widehat Y$ between groups, written $P(\hat y \mid x_1) - P(\hat y \mid x_0)$, can be causally decomposed into the influences of $X$ on the $L_2$-optimal prediction score $S$ and the influences of $X$ on the margin complement $M$, along different causal pathways (direct, indirect, spurious). We then show that under suitable causal assumptions, the influences of $X$ on the prediction score $S$ are equal to the influences of $X$ on the true outcome $Y$. This yields a new decomposition of the disparity in the predictor $\widehat Y$ that allows us to disentangle causal differences inherited from the true outcome $Y$ that exists in the real world vs. those coming from the optimization procedure itself. This observation highlights the need for more regulatory oversight due to the potential for bias amplification, and to address this issue we introduce new notions of weak and strong business necessity, together with an algorithm for assessing whether these notions are satisfied.
Fairness-Accuracy Trade-Offs: A Causal Perspective
May 24, 2024Systems based on machine learning may exhibit discriminatory behavior based on sensitive characteristics such as gender, sex, religion, or race. In light of this, various notions of fairness and methods to quantify discrimination were proposed, leading to the development of numerous approaches for constructing fair predictors. At the same time, imposing fairness constraints may decrease the utility of the decision-maker, highlighting a tension between fairness and utility. This tension is also recognized in legal frameworks, for instance in the disparate impact doctrine of Title VII of the Civil Rights Act of 1964 -- in which specific attention is given to considerations of business necessity -- possibly allowing the usage of proxy variables associated with the sensitive attribute in case a high-enough utility cannot be achieved without them. In this work, we analyze the tension between fairness and accuracy from a causal lens for the first time. We introduce the notion of a path-specific excess loss (PSEL) that captures how much the predictor's loss increases when a causal fairness constraint is enforced. We then show that the total excess loss (TEL), defined as the difference between the loss of predictor fair along all causal pathways vs. an unconstrained predictor, can be decomposed into a sum of more local PSELs. At the same time, enforcing a causal constraint often reduces the disparity between demographic groups. Thus, we introduce a quantity that summarizes the fairness-utility trade-off, called the causal fairness/utility ratio, defined as the ratio of the reduction in discrimination vs. the excess loss from constraining a causal pathway. This quantity is suitable for comparing the fairness-utility trade-off across causal pathways. Finally, as our approach requires causally-constrained fair predictors, we introduce a new neural approach for causally-constrained fair learning.
Fair Clustering: A Causal Perspective
Dec 14, 2023Clustering algorithms may unintentionally propagate or intensify existing disparities, leading to unfair representations or biased decision-making. Current fair clustering methods rely on notions of fairness that do not capture any information on the underlying causal mechanisms. We show that optimising for non-causal fairness notions can paradoxically induce direct discriminatory effects from a causal standpoint. We present a clustering approach that incorporates causal fairness metrics to provide a more nuanced approach to fairness in unsupervised learning. Our approach enables the specification of the causal fairness metrics that should be minimised. We demonstrate the efficacy of our methodology using datasets known to harbour unfair biases.
A Causal Framework for Decomposing Spurious Variations
Jun 08, 2023



One of the fundamental challenges found throughout the data sciences is to explain why things happen in specific ways, or through which mechanisms a certain variable $X$ exerts influences over another variable $Y$. In statistics and machine learning, significant efforts have been put into developing machinery to estimate correlations across variables efficiently. In causal inference, a large body of literature is concerned with the decomposition of causal effects under the rubric of mediation analysis. However, many variations are spurious in nature, including different phenomena throughout the applied sciences. Despite the statistical power to estimate correlations and the identification power to decompose causal effects, there is still little understanding of the properties of spurious associations and how they can be decomposed in terms of the underlying causal mechanisms. In this manuscript, we develop formal tools for decomposing spurious variations in both Markovian and Semi-Markovian models. We prove the first results that allow a non-parametric decomposition of spurious effects and provide sufficient conditions for the identification of such decompositions. The described approach has several applications, ranging from explainable and fair AI to questions in epidemiology and medicine, and we empirically demonstrate its use on a real-world dataset.
Causal Fairness for Outcome Control
Jun 08, 2023



As society transitions towards an AI-based decision-making infrastructure, an ever-increasing number of decisions once under control of humans are now delegated to automated systems. Even though such developments make various parts of society more efficient, a large body of evidence suggests that a great deal of care needs to be taken to make such automated decision-making systems fair and equitable, namely, taking into account sensitive attributes such as gender, race, and religion. In this paper, we study a specific decision-making task called outcome control in which an automated system aims to optimize an outcome variable $Y$ while being fair and equitable. The interest in such a setting ranges from interventions related to criminal justice and welfare, all the way to clinical decision-making and public health. In this paper, we first analyze through causal lenses the notion of benefit, which captures how much a specific individual would benefit from a positive decision, counterfactually speaking, when contrasted with an alternative, negative one. We introduce the notion of benefit fairness, which can be seen as the minimal fairness requirement in decision-making, and develop an algorithm for satisfying it. We then note that the benefit itself may be influenced by the protected attribute, and propose causal tools which can be used to analyze this. Finally, if some of the variations of the protected attribute in the benefit are considered as discriminatory, the notion of benefit fairness may need to be strengthened, which leads us to articulating a notion of causal benefit fairness. Using this notion, we develop a new optimization procedure capable of maximizing $Y$ while ascertaining causal fairness in the decision process.
Reconciling Predictive and Statistical Parity: A Causal Approach
Jun 08, 2023Since the rise of fair machine learning as a critical field of inquiry, many different notions on how to quantify and measure discrimination have been proposed in the literature. Some of these notions, however, were shown to be mutually incompatible. Such findings make it appear that numerous different kinds of fairness exist, thereby making a consensus on the appropriate measure of fairness harder to reach, hindering the applications of these tools in practice. In this paper, we investigate one of these key impossibility results that relates the notions of statistical and predictive parity. Specifically, we derive a new causal decomposition formula for the fairness measures associated with predictive parity, and obtain a novel insight into how this criterion is related to statistical parity through the legal doctrines of disparate treatment, disparate impact, and the notion of business necessity. Our results show that through a more careful causal analysis, the notions of statistical and predictive parity are not really mutually exclusive, but complementary and spanning a spectrum of fairness notions through the concept of business necessity. Finally, we demonstrate the importance of our findings on a real-world example.
Causal Fairness Analysis
Jul 23, 2022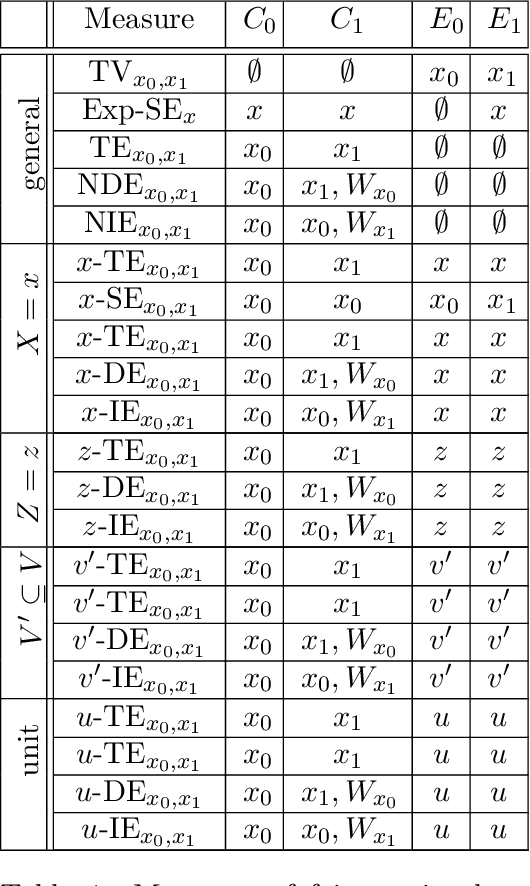
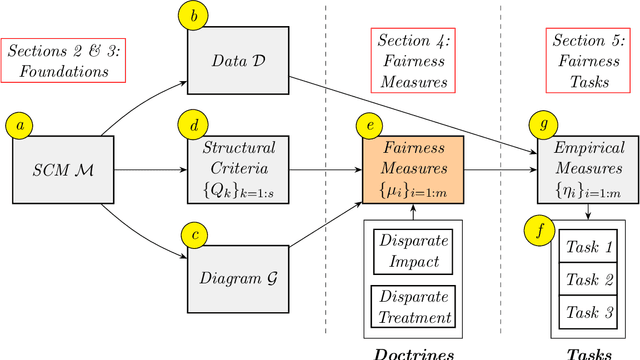

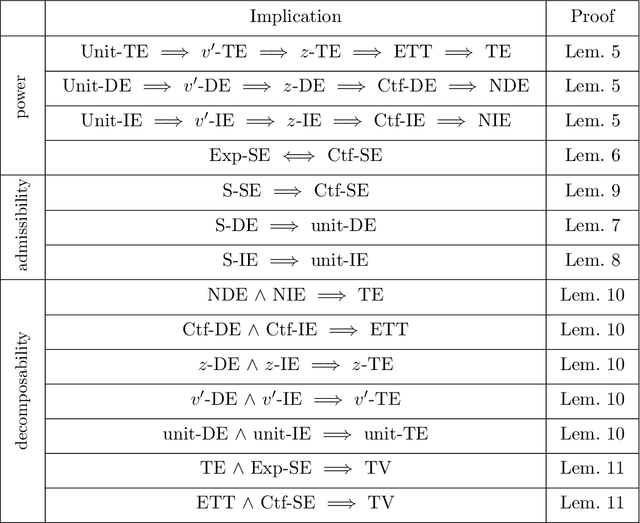
Decision-making systems based on AI and machine learning have been used throughout a wide range of real-world scenarios, including healthcare, law enforcement, education, and finance. It is no longer far-fetched to envision a future where autonomous systems will be driving entire business decisions and, more broadly, supporting large-scale decision-making infrastructure to solve society's most challenging problems. Issues of unfairness and discrimination are pervasive when decisions are being made by humans, and remain (or are potentially amplified) when decisions are made using machines with little transparency, accountability, and fairness. In this paper, we introduce a framework for \textit{causal fairness analysis} with the intent of filling in this gap, i.e., understanding, modeling, and possibly solving issues of fairness in decision-making settings. The main insight of our approach will be to link the quantification of the disparities present on the observed data with the underlying, and often unobserved, collection of causal mechanisms that generate the disparity in the first place, challenge we call the Fundamental Problem of Causal Fairness Analysis (FPCFA). In order to solve the FPCFA, we study the problem of decomposing variations and empirical measures of fairness that attribute such variations to structural mechanisms and different units of the population. Our effort culminates in the Fairness Map, which is the first systematic attempt to organize and explain the relationship between different criteria found in the literature. Finally, we study which causal assumptions are minimally needed for performing causal fairness analysis and propose a Fairness Cookbook, which allows data scientists to assess the existence of disparate impact and disparate treatment.