 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-Order Optimization for LLM Fine-Tuning via Learnable Direction Sampling
Feb 14, 2026Fine-tuning large pretrained language models (LLMs) is a cornerstone of modern NLP, yet its growing memory demands (driven by backpropagation and large optimizer States) limit deployment in resource-constrained settings. Zero-order (ZO) methods bypass backpropagation by estimating directional derivatives from forward evaluations, offering substantial memory savings. However, classical ZO estimators suffer from high variance and an adverse dependence on the parameter dimensionality $d$, which has constrained their use to low-dimensional problems. In this work, we propose a policy-driven ZO framework that treats the sampling distribution over perturbation directions as a learnable policy and updates it to reduce the variance of directional estimates. We develop a practical algorithm implementing this idea and provide a theoretical analysis, showing that learned sampling distributions improve the quality of gradient information and relax the explicit dependence on $d$ in convergence bounds. Empirically, we validate the approach on challenging LLM fine-tuning benchmarks, demonstrating substantially improved performance compared to standard ZO baselines. Our results suggest that adaptive direction sampling is a promising route to make ZO fine-tuning viable at scale. The source code is available at https://github.com/brain-lab-research/zo_ldsd
TAM-Eval: Evaluating LLMs for Automated Unit Test Maintenance
Jan 26, 2026While Large Language Models (LLMs) have shown promise in software engineering, their application to unit testing remains largely confined to isolated test generation or oracle prediction, neglecting the broader challenge of test suite maintenance. We introduce TAM-Eval (Test Automated Maintenance Evaluation), a framework and benchmark designed to evaluate model performance across three core test maintenance scenarios: creation, repair, and updating of test suites. Unlike prior work limited to function-level tasks, TAM-Eval operates at the test file level, while maintaining access to full repository context during isolated evaluation, better reflecting real-world maintenance workflows. Our benchmark comprises 1,539 automatically extracted and validated scenarios from Python, Java, and Go projects. TAM-Eval supports system-agnostic evaluation of both raw LLMs and agentic workflows, using a reference-free protocol based on test suite pass rate, code coverage, and mutation testing. Empirical results indicate that state-of-the-art LLMs have limited capabilities in realistic test maintenance processes and yield only marginal improvements in test effectiveness. We release TAM-Eval as an open-source framework to support future research in automated software testing. Our data and code are publicly available at https://github.com/trndcenter/TAM-Eval.
RM -RF: Reward Model for Run-Free Unit Test Evaluation
Jan 19, 2026We present RM-RF, a lightweight reward model for run-free evaluation of automatically generated unit tests. Instead of repeatedly compiling and executing candidate tests, RM-RF predicts - from source and test code alone - three execution-derived signals: (1) whether the augmented test suite compiles and runs successfully, (2) whether the generated test cases increase code coverage, and (3) whether the generated test cases improve the mutation kill rate. To train and evaluate RM-RF we assemble a multilingual dataset (Java, Python, Go) of focal files, test files, and candidate test additions labeled by an execution-based pipeline, and we release an associated dataset and methodology for comparative evaluation. We tested multiple model families and tuning regimes (zero-shot, full fine-tuning, and PEFT via LoRA), achieving an average F1 of 0.69 across the three targets. Compared to conventional compile-and-run instruments, RM-RF provides substantially lower latency and infrastructure cost while delivering competitive predictive fidelity, enabling fast, scalable feedback for large-scale test generation and RL-based code optimization.
Leveraging Coordinate Momentum in SignSGD and Muon: Memory-Optimized Zero-Order
Jun 04, 2025Fine-tuning Large Language Models (LLMs) is essential for adapting pre-trained models to downstream tasks. Yet traditional first-order optimizers such as Stochastic Gradient Descent (SGD) and Adam incur prohibitive memory and computational costs that scale poorly with model size. In this paper, we investigate zero-order (ZO) optimization methods as a memory- and compute-efficient alternative, particularly in the context of parameter-efficient fine-tuning techniques like LoRA. We propose $\texttt{JAGUAR SignSGD}$, a ZO momentum-based algorithm that extends ZO SignSGD, requiring the same number of parameters as the standard ZO SGD and only $\mathcal{O}(1)$ function evaluations per iteration. To the best of our knowledge, this is the first study to establish rigorous convergence guarantees for SignSGD in the stochastic ZO case. We further propose $\texttt{JAGUAR Muon}$, a novel ZO extension of the Muon optimizer that leverages the matrix structure of model parameters, and we provide its convergence rate under arbitrary stochastic noise. Through extensive experiments on challenging LLM fine-tuning benchmarks, we demonstrate that the proposed algorithms meet or exceed the convergence quality of standard first-order methods, achieving significant memory reduction. Our theoretical and empirical results establish new ZO optimization methods as a practical and theoretically grounded approach for resource-constrained LLM adaptation. Our code is available at https://github.com/brain-mmo-lab/ZO_LLM
Quality and Cost Trade-offs in Passage Re-ranking Task
Nov 18, 2021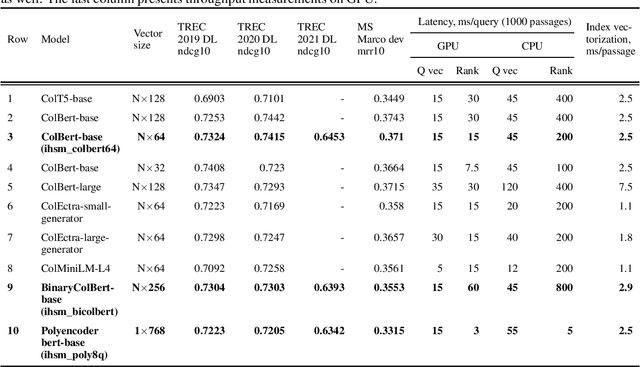
Deep learning models named transformers achieved state-of-the-art results in a vast majority of NLP tasks at the cost of increased computational complexity and high memory consumption. Using the transformer model in real-time inference becomes a major challenge when implemented in production, because it requires expensive computational resources. The more executions of a transformer are needed the lower the overall throughput is, and switching to the smaller encoders leads to the decrease of accuracy. Our paper is devoted to the problem of how to choose the right architecture for the ranking step of the information retrieval pipeline, so that the number of required calls of transformer encoder is minimal with the maximum achievable quality of ranking. We investigated several late-interaction models such as Colbert and Poly-encoder architectures along with their modifications. Also, we took care of the memory footprint of the search index and tried to apply the learning-to-hash method to binarize the output vectors from the transformer encoders. The results of the evaluation are provided using TREC 2019-2021 and MS Marco dev datasets.