 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMMCOMET: A Large-Scale Multimodal Commonsense Knowledge Graph for Contextual Reasoning
Mar 01, 2026We present MMCOMET, the first multimodal commonsense knowledge graph (MMKG) that integrates physical, social, and eventive knowledge. MMCOMET extends the ATOMIC2020 knowledge graph to include a visual dimension, through an efficient image retrieval process, resulting in over 900K multimodal triples. This new resource addresses a major limitation of existing MMKGs in supporting complex reasoning tasks like image captioning and storytelling. Through a standard visual storytelling experiment, we show that our holistic approach enables the generation of richer, coherent, and contextually grounded stories than those produced using text-only knowledge. This resource establishes a new foundation for multimodal commonsense reasoning and narrative generation.
GEM-VPC: A dual Graph-Enhanced Multimodal integration for Video Paragraph Captioning
Oct 12, 2024



Video Paragraph Captioning (VPC) aims to generate paragraph captions that summarises key events within a video. Despite recent advancements, challenges persist, notably in effectively utilising multimodal signals inherent in videos and addressing the long-tail distribution of words. The paper introduces a novel multimodal integrated caption generation framework for VPC that leverages information from various modalities and external knowledge bases. Our framework constructs two graphs: a 'video-specific' temporal graph capturing major events and interactions between multimodal information and commonsense knowledge, and a 'theme graph' representing correlations between words of a specific theme. These graphs serve as input for a transformer network with a shared encoder-decoder architecture. We also introduce a node selection module to enhance decoding efficiency by selecting the most relevant nodes from the graphs. Our results demonstrate superior performance across benchmark datasets.
SCO-VIST: Social Interaction Commonsense Knowledge-based Visual Storytelling
Feb 01, 2024



Visual storytelling aims to automatically generate a coherent story based on a given image sequence. Unlike tasks like image captioning, visual stories should contain factual descriptions, worldviews, and human social commonsense to put disjointed elements together to form a coherent and engaging human-writeable story. However, most models mainly focus on applying factual information and using taxonomic/lexical external knowledge when attempting to create stories. This paper introduces SCO-VIST, a framework representing the image sequence as a graph with objects and relations that includes human action motivation and its social interaction commonsense knowledge. SCO-VIST then takes this graph representing plot points and creates bridges between plot points with semantic and occurrence-based edge weights. This weighted story graph produces the storyline in a sequence of events using Floyd-Warshall's algorithm. Our proposed framework produces stories superior across multiple metrics in terms of visual grounding, coherence, diversity, and humanness, per both automatic and human evaluations.
RoViST:Learning Robust Metrics for Visual Storytelling
May 08, 2022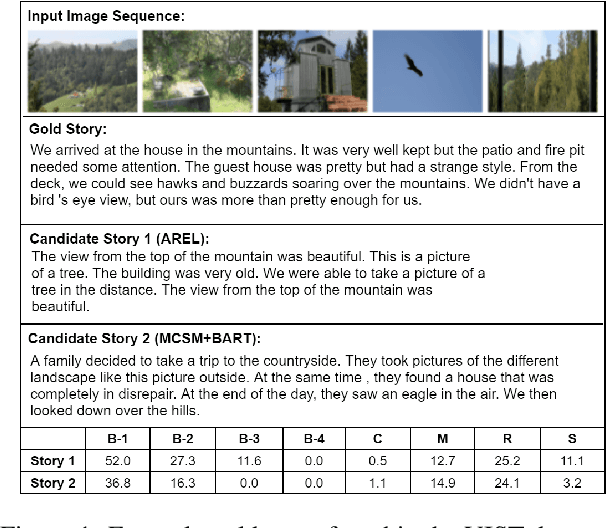
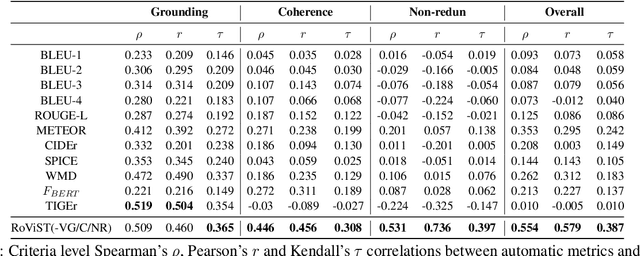

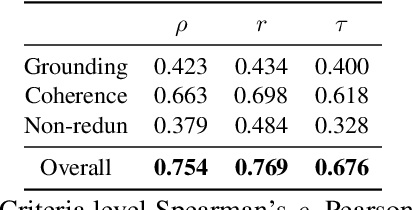
Visual storytelling (VST) is the task of generating a story paragraph that describes a given image sequence. Most existing storytelling approaches have evaluated their models using traditional natural language generation metrics like BLEU or CIDEr. However, such metrics based on n-gram matching tend to have poor correlation with human evaluation scores and do not explicitly consider other criteria necessary for storytelling such as sentence structure or topic coherence. Moreover, a single score is not enough to assess a story as it does not inform us about what specific errors were made by the model. In this paper, we propose 3 evaluation metrics sets that analyses which aspects we would look for in a good story: 1) visual grounding, 2) coherence, and 3) non-redundancy. We measure the reliability of our metric sets by analysing its correlation with human judgement scores on a sample of machine stories obtained from 4 state-of-the-arts models trained on the Visual Storytelling Dataset (VIST). Our metric sets outperforms other metrics on human correlation, and could be served as a learning based evaluation metric set that is complementary to existing rule-based metrics.