 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Systematic Review of Reproducibility Research in Natural Language Processing
Mar 21, 2021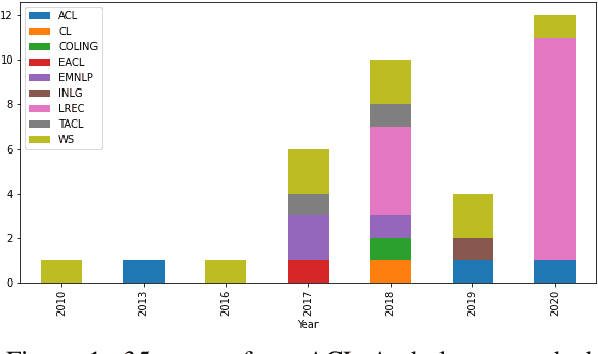
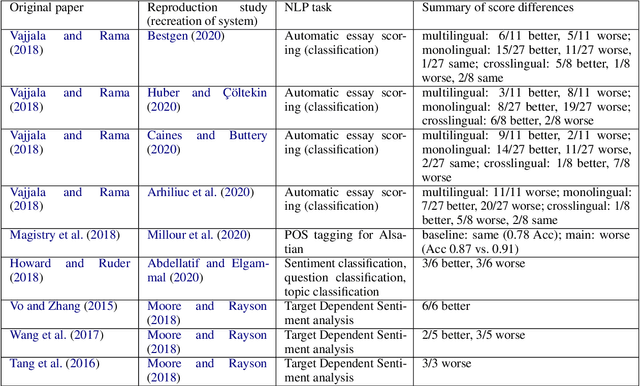
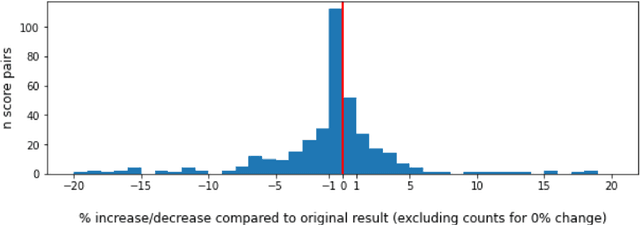
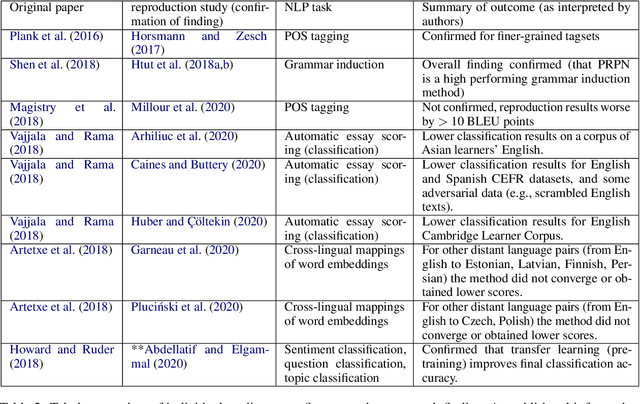
Against the background of what has been termed a reproducibility crisis in science, the NLP field is becoming increasingly interested in, and conscientious about, the reproducibility of its results. The past few years have seen an impressive range of new initiatives, events and active research in the area. However, the field is far from reaching a consensus about how reproducibility should be defined, measured and addressed, with diversity of views currently increasing rather than converging. With this focused contribution, we aim to provide a wide-angle, and as near as possible complete, snapshot of current work on reproducibility in NLP, delineating differences and similarities, and providing pointers to common denominators.
A Gold Standard Methodology for Evaluating Accuracy in Data-To-Text Systems
Nov 08, 2020
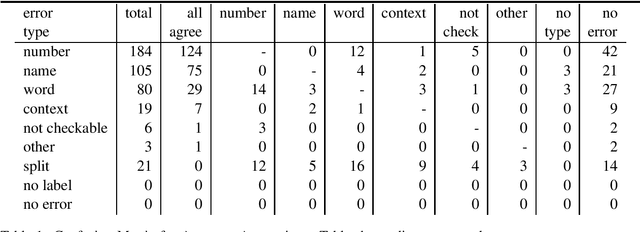


Most Natural Language Generation systems need to produce accurate texts. We propose a methodology for high-quality human evaluation of the accuracy of generated texts, which is intended to serve as a gold-standard for accuracy evaluations of data-to-text systems. We use our methodology to evaluate the accuracy of computer generated basketball summaries. We then show how our gold standard evaluation can be used to validate automated metrics
How are you? Introducing stress-based text tailoring
Jul 20, 2020
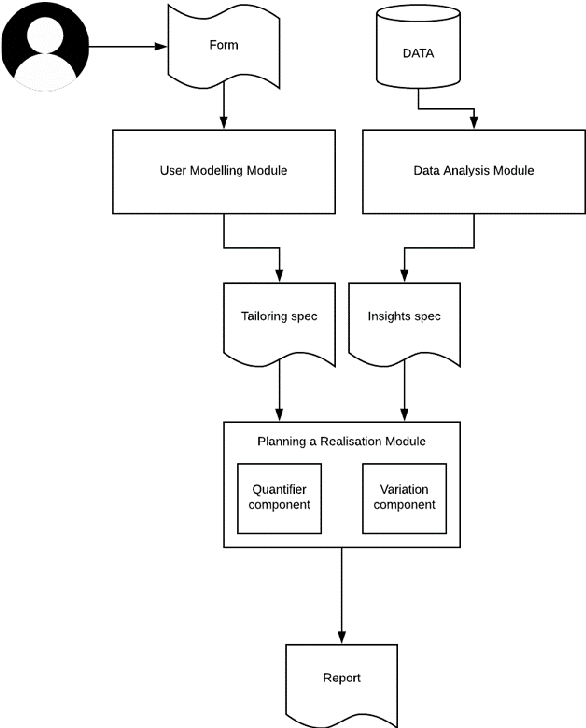
Can stress affect not only your life but also how you read and interpret a text? Healthcare has shown evidence of such dynamics and in this short paper we discuss customising texts based on user stress level, as it could represent a critical factor when it comes to user engagement and behavioural change. We first show a real-world example in which user behaviour is influenced by stress, then, after discussing which tools can be employed to assess and measure it, we propose an initial method for tailoring the document by exploiting complexity reduction and affect enforcement. The result is a short and encouraging text which requires less commitment to be read and understood. We believe this work in progress can raise some interesting questions on a topic that is often overlooked in NLG.
Shared Task on Evaluating Accuracy in Natural Language Generation
Jun 22, 2020We propose a shared task on methodologies and algorithms for evaluating the accuracy of generated texts. Participants will measure the accuracy of basketball game summaries produced by NLG systems from basketball box score data.
FitChat: Conversational Artificial Intelligence Interventions for Encouraging Physical Activity in Older Adults
Apr 29, 2020


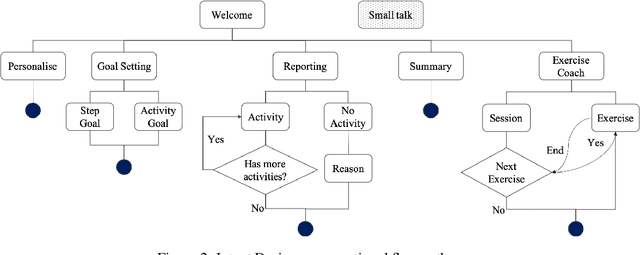
Delivery of digital behaviour change interventions which encourage physical activity has been tried in many forms. Most often interventions are delivered as text notifications, but these do not promote interaction. Advances in conversational AI have improved natural language understanding and generation, allowing AI chatbots to provide an engaging experience with the user. For this reason, chatbots have recently been seen in healthcare delivering digital interventions through free text or choice selection. In this work, we explore the use of voice-based AI chatbots as a novel mode of intervention delivery, specifically targeting older adults to encourage physical activity. We co-created "FitChat", an AI chatbot, with older adults and we evaluate the first prototype using Think Aloud Sessions. Our thematic evaluation suggests that older adults prefer voice-based chat over text notifications or free text entry and that voice is a powerful mode for encouraging motivation.
Natural Language Generation Challenges for Explainable AI
Nov 20, 2019Good quality explanations of artificial intelligence (XAI) reasoning must be written (and evaluated) for an explanatory purpose, targeted towards their readers, have a good narrative and causal structure, and highlight where uncertainty and data quality affect the AI output. I discuss these challenges from a Natural Language Generation (NLG) perspective, and highlight four specific NLG for XAI research challenges.
Meteorologists and Students: A resource for language grounding of geographical descriptors
Sep 07, 2018
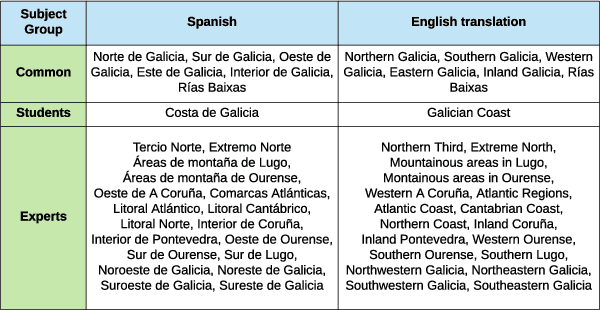
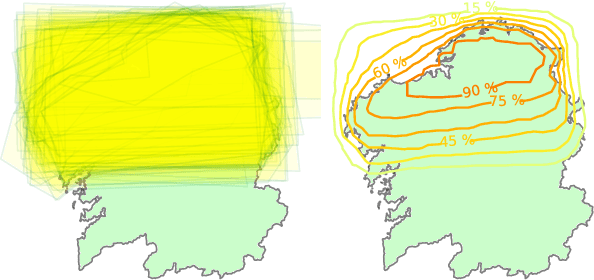
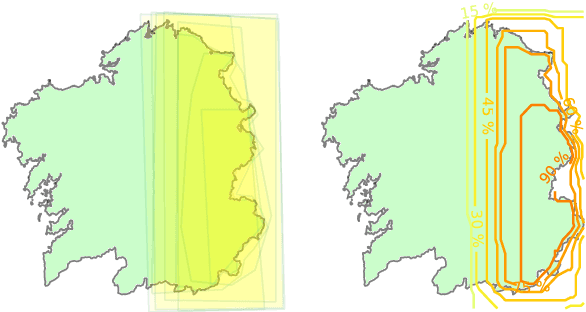
We present a data resource which can be useful for research purposes on language grounding tasks in the context of geographical referring expression generation. The resource is composed of two data sets that encompass 25 different geographical descriptors and a set of associated graphical representations, drawn as polygons on a map by two groups of human subjects: teenage students and expert meteorologists.
Making effective use of healthcare data using data-to-text technology
Aug 10, 2018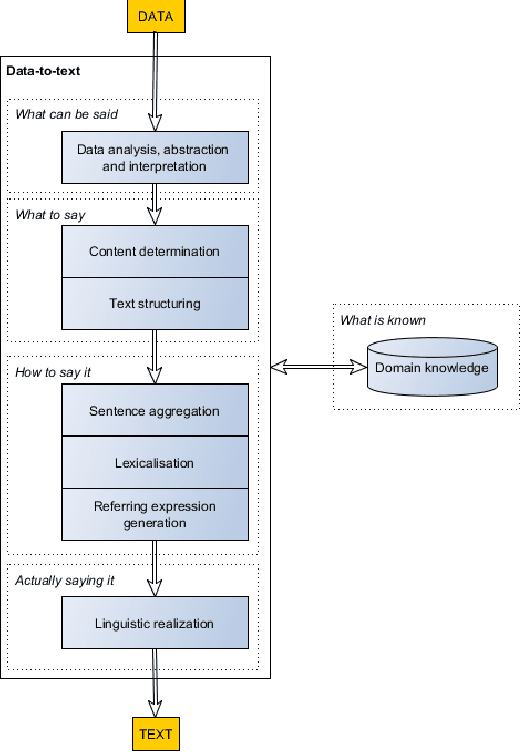
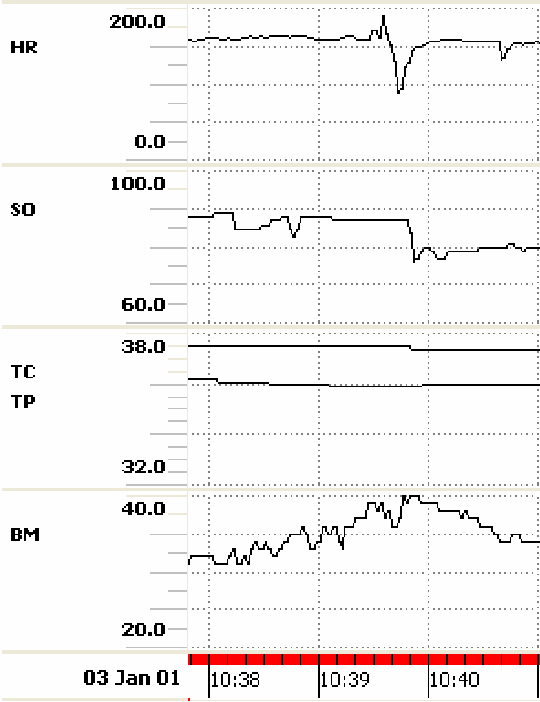
Healthcare organizations are in a continuous effort to improve health outcomes, reduce costs and enhance patient experience of care. Data is essential to measure and help achieving these improvements in healthcare delivery. Consequently, a data influx from various clinical, financial and operational sources is now overtaking healthcare organizations and their patients. The effective use of this data, however, is a major challenge. Clearly, text is an important medium to make data accessible. Financial reports are produced to assess healthcare organizations on some key performance indicators to steer their healthcare delivery. Similarly, at a clinical level, data on patient status is conveyed by means of textual descriptions to facilitate patient review, shift handover and care transitions. Likewise, patients are informed about data on their health status and treatments via text, in the form of reports or via ehealth platforms by their doctors. Unfortunately, such text is the outcome of a highly labour-intensive process if it is done by healthcare professionals. It is also prone to incompleteness, subjectivity and hard to scale up to different domains, wider audiences and varying communication purposes. Data-to-text is a recent breakthrough technology in artificial intelligence which automatically generates natural language in the form of text or speech from data. This chapter provides a survey of data-to-text technology, with a focus on how it can be deployed in a healthcare setting. It will (1) give an up-to-date synthesis of data-to-text approaches, (2) give a categorized overview of use cases in healthcare, (3) seek to make a strong case for evaluating and implementing data-to-text in a healthcare setting, and (4) highlight recent research challenges.
An Empirical Approach for Modeling Fuzzy Geographical Descriptors
Mar 30, 2017
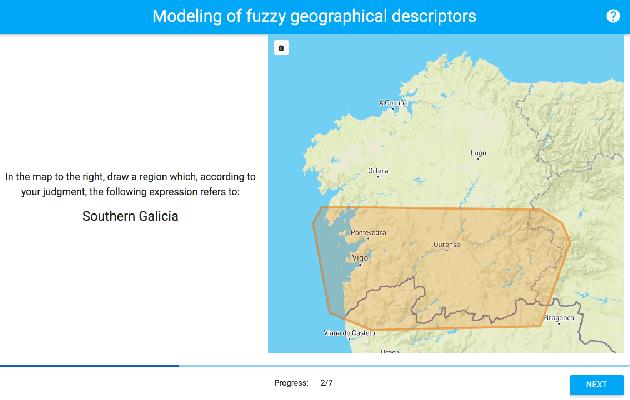
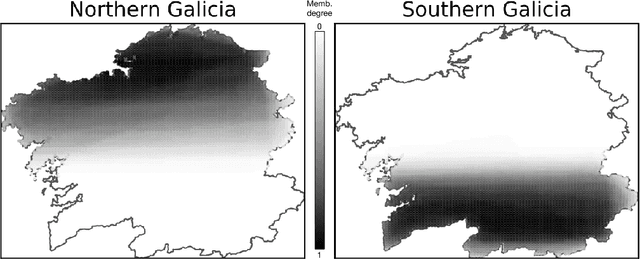
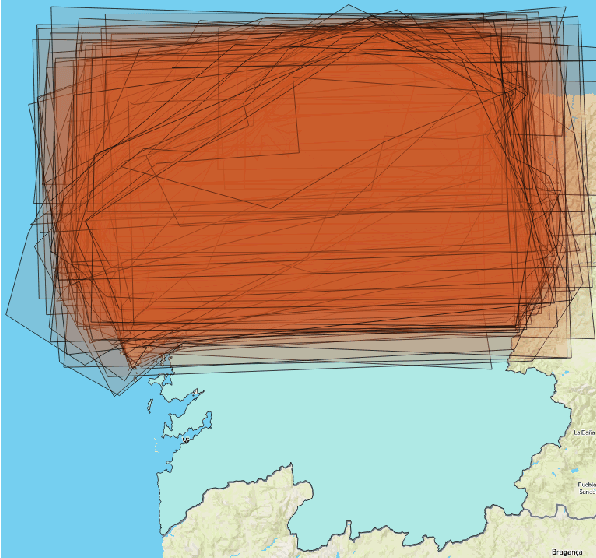
We present a novel heuristic approach that defines fuzzy geographical descriptors using data gathered from a survey with human subjects. The participants were asked to provide graphical interpretations of the descriptors `north' and `south' for the Galician region (Spain). Based on these interpretations, our approach builds fuzzy descriptors that are able to compute membership degrees for geographical locations. We evaluated our approach in terms of efficiency and precision. The fuzzy descriptors are meant to be used as the cornerstones of a geographical referring expression generation algorithm that is able to linguistically characterize geographical locations and regions. This work is also part of a general research effort that intends to establish a methodology which reunites the empirical studies traditionally practiced in data-to-text and the use of fuzzy sets to model imprecision and vagueness in words and expressions for text generation purposes.
Tailored Patient Information: Some Issues and Questions
Jul 18, 1997Tailored patient information (TPI) systems are computer programs which produce personalised heath-information material for patients. TPI systems are of growing interest to the natural-language generation (NLG) community; many TPI systems have also been developed in the medical community, usually with mail-merge technology. No matter what technology is used, experience shows that it is not easy to field a TPI system, even if it is shown to be effective in clinical trials. In this paper we discuss some of the difficulties in fielding TPI systems. This is based on our experiences with 2 TPI systems, one for generating asthma-information booklets and one for generating smoking-cessation letters.
* This is a paper about technology-transfer. It does not have much technical content