 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSound Event Detection with Adaptive Frequency Selection
May 17, 2021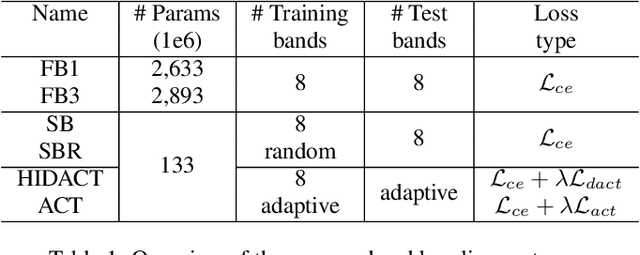
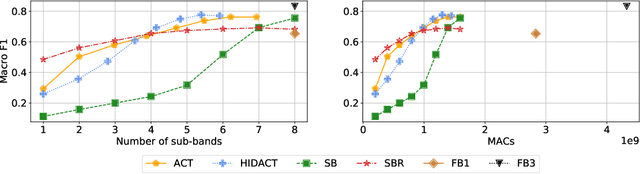
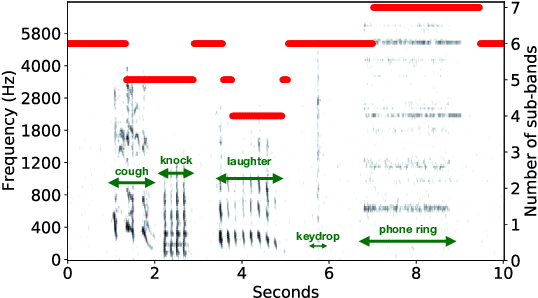
In this work, we present HIDACT, a novel network architecture for adaptive computation for efficiently recognizing acoustic events. We evaluate the model on a sound event detection task where we train it to adaptively process frequency bands. The model learns to adapt to the input without requesting all frequency sub-bands provided. It can make confident predictions within fewer processing steps, hence reducing the amount of computation. Experimental results show that HIDACT has comparable performance to baseline models with more parameters and higher computational complexity. Furthermore, the model can adjust the amount of computation based on the data and computational budget.
Separate but Together: Unsupervised Federated Learning for Speech Enhancement from Non-IID Data
May 11, 2021
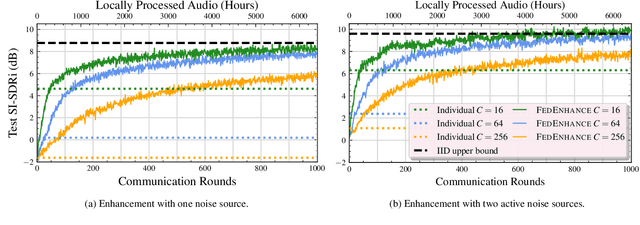
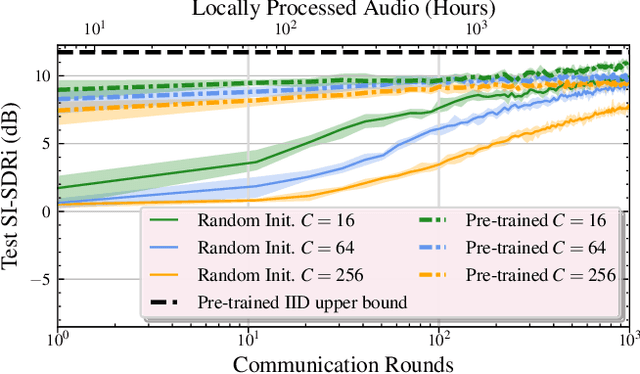
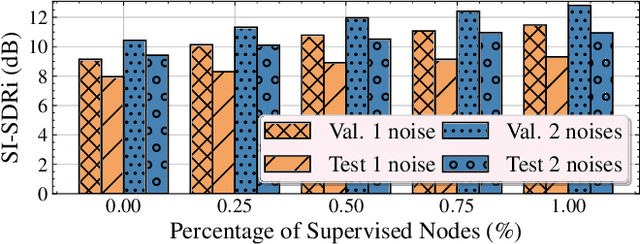
We propose FEDENHANCE, an unsupervised federated learning (FL) approach for speech enhancement and separation with non-IID distributed data across multiple clients. We simulate a real-world scenario where each client only has access to a few noisy recordings from a limited and disjoint number of speakers (hence non-IID). Each client trains their model in isolation using mixture invariant training while periodically providing updates to a central server. Our experiments show that our approach achieves competitive enhancement performance compared to IID training on a single device and that we can further facilitate the convergence speed and the overall performance using transfer learning on the server-side. Moreover, we show that we can effectively combine updates from clients trained locally with supervised and unsupervised losses. We also release a new dataset LibriFSD50K and its creation recipe in order to facilitate FL research for source separation problems.
Unsupervised low-rank representations for speech emotion recognition
Apr 14, 2021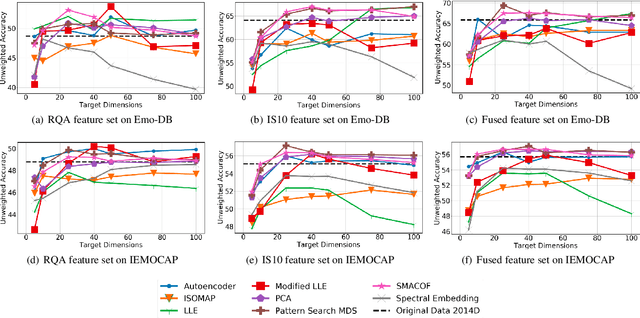
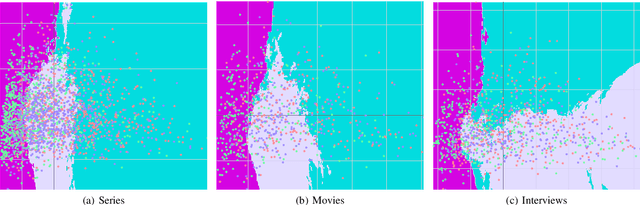
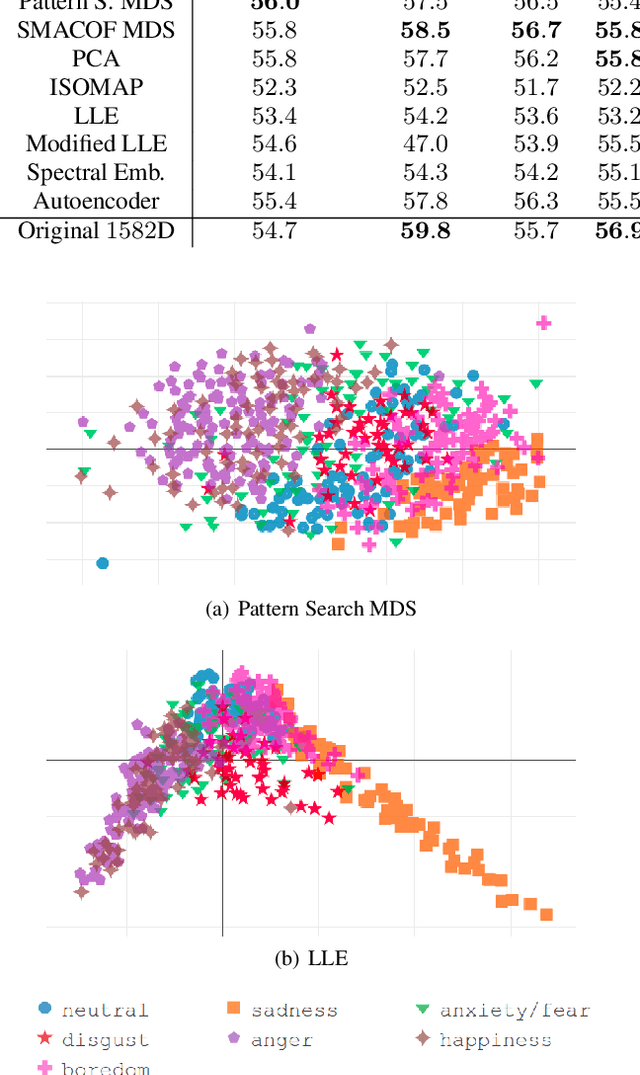
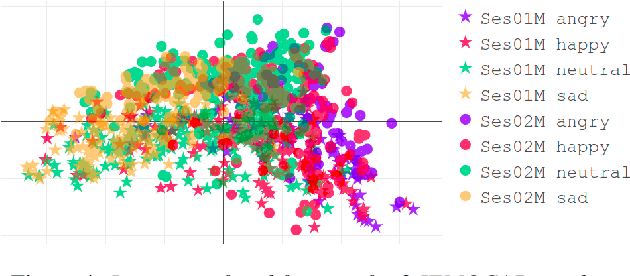
We examine the use of linear and non-linear dimensionality reduction algorithms for extracting low-rank feature representations for speech emotion recognition. Two feature sets are used, one based on low-level descriptors and their aggregations (IS10) and one modeling recurrence dynamics of speech (RQA), as well as their fusion. We report speech emotion recognition (SER) results for learned representations on two databases using different classification methods. Classification with low-dimensional representations yields performance improvement in a variety of settings. This indicates that dimensionality reduction is an effective way to combat the curse of dimensionality for SER. Visualization of features in two dimensions provides insight into discriminatory abilities of reduced feature sets.
Compute and memory efficient universal sound source separation
Mar 03, 2021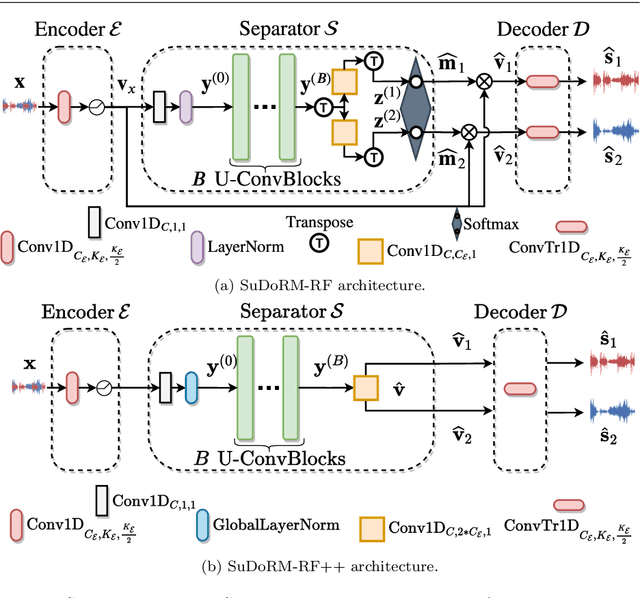
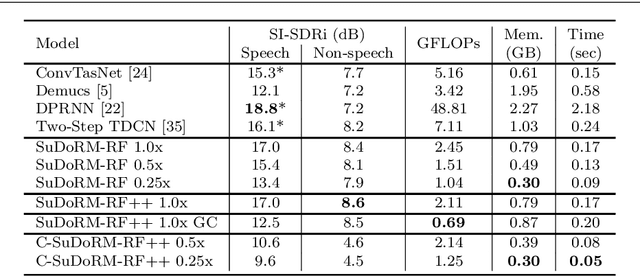
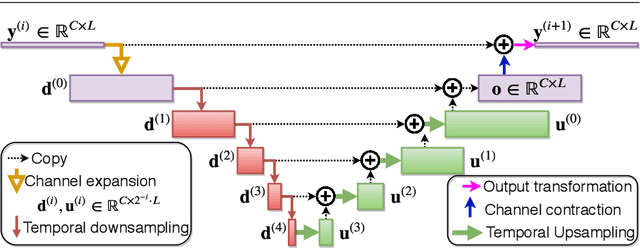
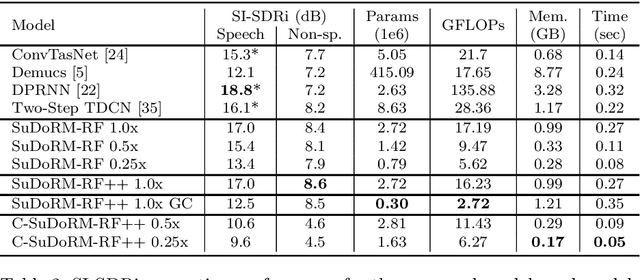
Recent progress in audio source separation lead by deep learning has enabled many neural network models to provide robust solutions to this fundamental estimation problem. In this study, we provide a family of efficient neural network architectures for general purpose audio source separation while focusing on multiple computational aspects that hinder the application of neural networks in real-world scenarios. The backbone structure of this convolutional network is the SUccessive DOwnsampling and Resampling of Multi-Resolution Features (SuDoRM-RF) as well as their aggregation which is performed through simple one-dimensional convolutions. This mechanism enables our models to obtain high fidelity signal separation in a wide variety of settings where variable number of sources are present and with limited computational resources (e.g. floating point operations, memory footprint, number of parameters and latency). Our experiments show that SuDoRM-RF models perform comparably and even surpass several state-of-the-art benchmarks with significantly higher computational resource requirements. The causal variation of SuDoRM-RF is able to obtain competitive performance in real-time speech separation of around 10dB scale-invariant signal-to-distortion ratio improvement (SI-SDRi) while remaining up to 20 times faster than real-time on a laptop device.
Into the Wild with AudioScope: Unsupervised Audio-Visual Separation of On-Screen Sounds
Nov 02, 2020
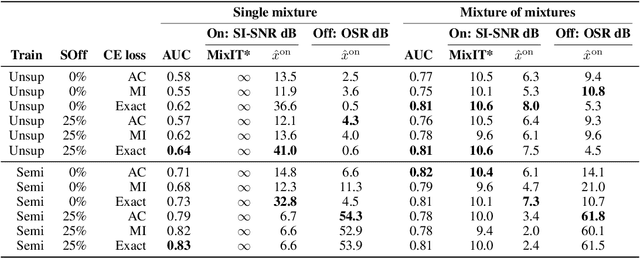
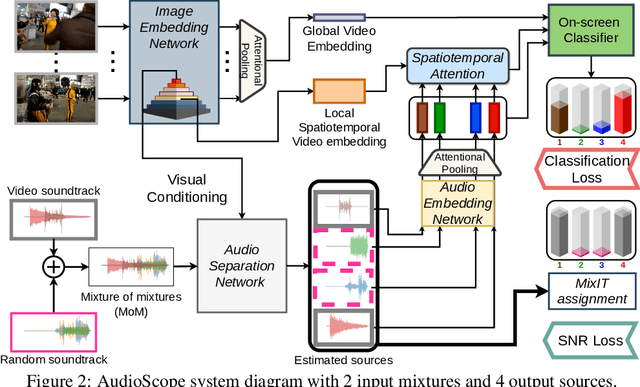
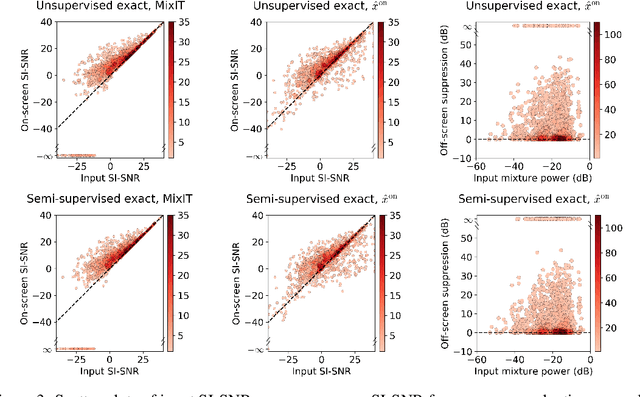
Recent progress in deep learning has enabled many advances in sound separation and visual scene understanding. However, extracting sound sources which are apparent in natural videos remains an open problem. In this work, we present AudioScope, a novel audio-visual sound separation framework that can be trained without supervision to isolate on-screen sound sources from real in-the-wild videos. Prior audio-visual separation work assumed artificial limitations on the domain of sound classes (e.g., to speech or music), constrained the number of sources, and required strong sound separation or visual segmentation labels. AudioScope overcomes these limitations, operating on an open domain of sounds, with variable numbers of sources, and without labels or prior visual segmentation. The training procedure for AudioScope uses mixture invariant training (MixIT) to separate synthetic mixtures of mixtures (MoMs) into individual sources, where noisy labels for mixtures are provided by an unsupervised audio-visual coincidence model. Using the noisy labels, along with attention between video and audio features, AudioScope learns to identify audio-visual similarity and to suppress off-screen sounds. We demonstrate the effectiveness of our approach using a dataset of video clips extracted from open-domain YFCC100m video data. This dataset contains a wide diversity of sound classes recorded in unconstrained conditions, making the application of previous methods unsuitable. For evaluation and semi-supervised experiments, we collected human labels for presence of on-screen and off-screen sounds on a small subset of clips.
Unified Gradient Reweighting for Model Biasing with Applications to Source Separation
Oct 25, 2020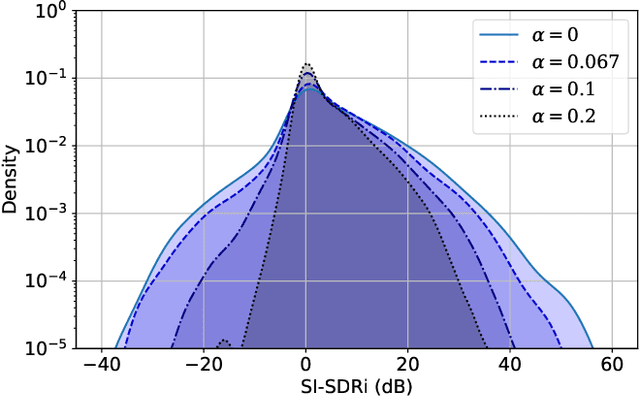
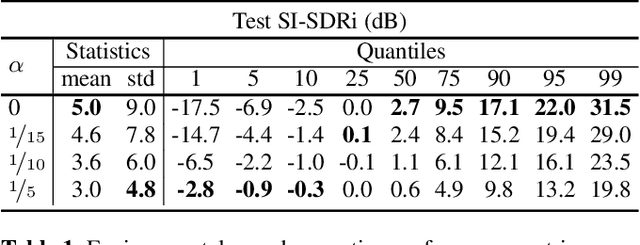
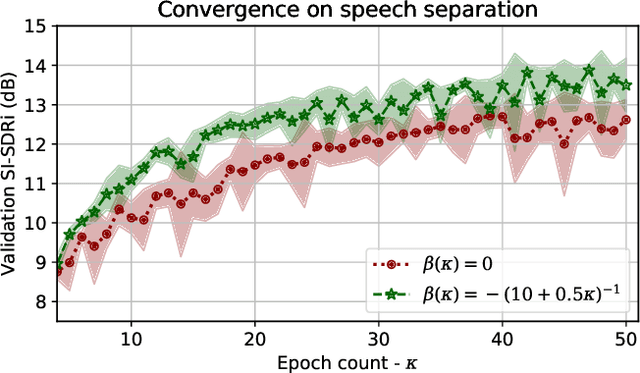
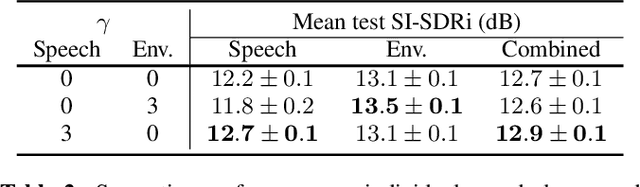
Recent deep learning approaches have shown great improvement in audio source separation tasks. However, the vast majority of such work is focused on improving average separation performance, often neglecting to examine or control the distribution of the results. In this paper, we propose a simple, unified gradient reweighting scheme, with a lightweight modification to bias the learning process of a model and steer it towards a certain distribution of results. More specifically, we reweight the gradient updates of each batch, using a user-specified probability distribution. We apply this method to various source separation tasks, in order to shift the operating point of the models towards different objectives. We demonstrate different parameterizations of our unified reweighting scheme can be used towards addressing several real-world problems, such as unreliable separation estimates. Our framework enables the user to control a robustness trade-off between worst and average performance. Moreover, we experimentally show that our unified reweighting scheme can also be used in order to shift the focus of the model towards being more accurate for user-specified sound classes or even towards easier examples in order to enable faster convergence.
Sudo rm -rf: Efficient Networks for Universal Audio Source Separation
Jul 14, 2020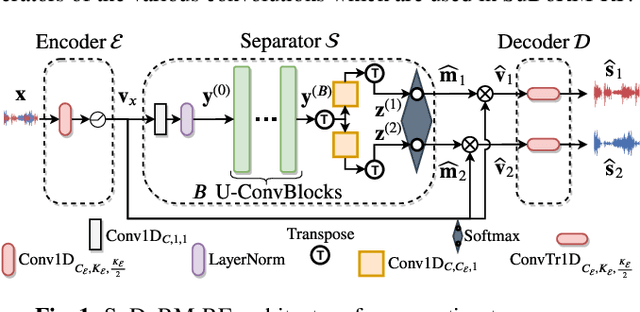
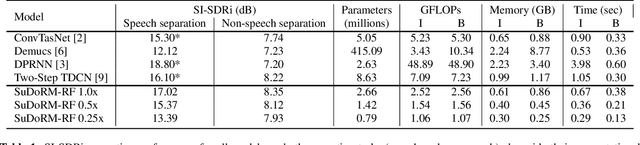
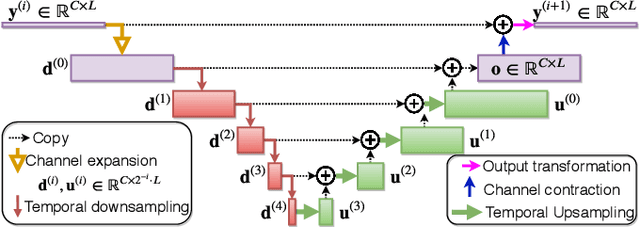
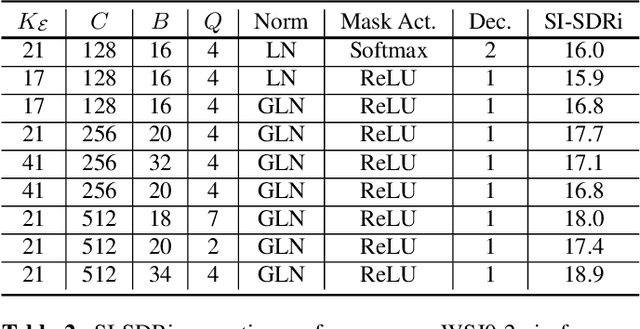
In this paper, we present an efficient neural network for end-to-end general purpose audio source separation. Specifically, the backbone structure of this convolutional network is the SUccessive DOwnsampling and Resampling of Multi-Resolution Features (SuDoRMRF) as well as their aggregation which is performed through simple one-dimensional convolutions. In this way, we are able to obtain high quality audio source separation with limited number of floating point operations, memory requirements, number of parameters and latency. Our experiments on both speech and environmental sound separation datasets show that SuDoRMRF performs comparably and even surpasses various state-of-the-art approaches with significantly higher computational resource requirements.
Unsupervised Sound Separation Using Mixtures of Mixtures
Jun 23, 2020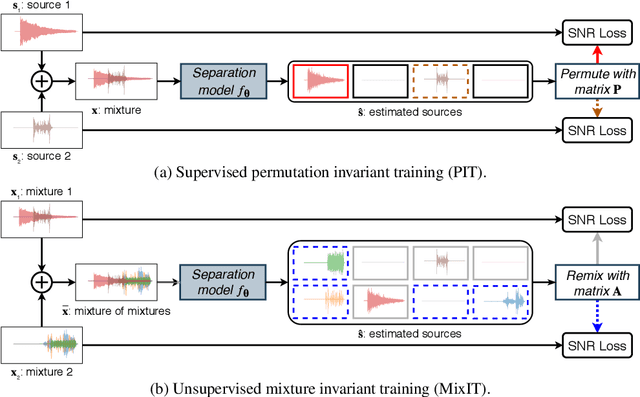
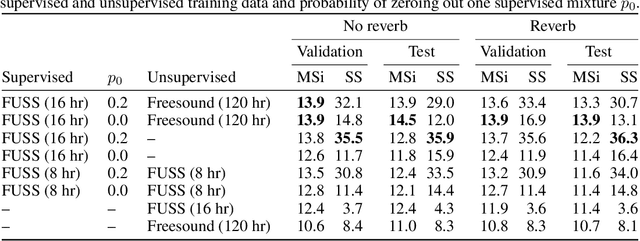
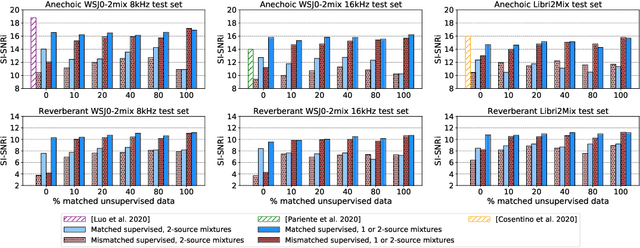
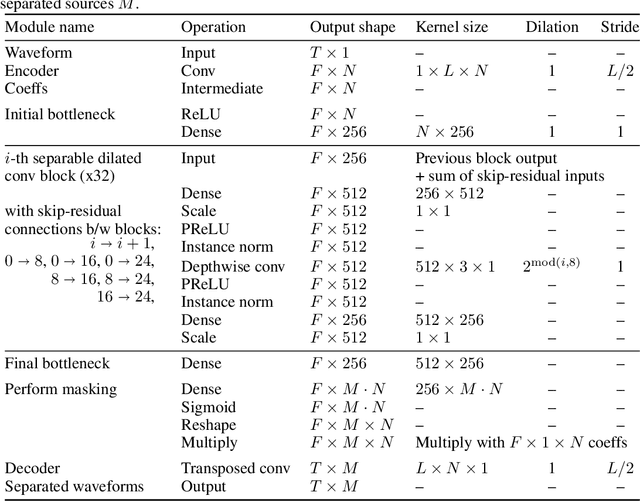
In recent years, rapid progress has been made on the problem of single-channel sound separation using supervised training of deep neural networks. In such supervised approaches, the model is trained to predict the component sources from synthetic mixtures created by adding up isolated ground-truth sources. The reliance on this synthetic training data is problematic because good performance depends upon the degree of match between the training data and real-world audio, especially in terms of the acoustic conditions and distribution of sources. The acoustic properties can be challenging to accurately simulate, and the distribution of sound types may be hard to replicate. In this paper, we propose a completely unsupervised method, mixture invariant training (MixIT), that requires only single-channel acoustic mixtures. In MixIT, training examples are constructed by mixing together existing mixtures, and the model separates them into a variable number of latent sources, such that the separated sources can be remixed to approximate the original mixtures. We show that MixIT can achieve competitive performance compared to supervised methods on speech separation. Using MixIT in a semi-supervised learning setting enables unsupervised domain adaptation and learning from large amounts of real-world data without ground-truth source waveforms. In particular, we significantly improve reverberant speech separation performance by incorporating reverberant mixtures, train a speech enhancement system from noisy mixtures, and improve universal sound separation by incorporating a large amount of in-the-wild data.
Improving Universal Sound Separation Using Sound Classification
Nov 18, 2019
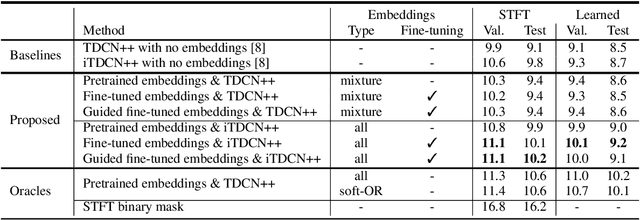
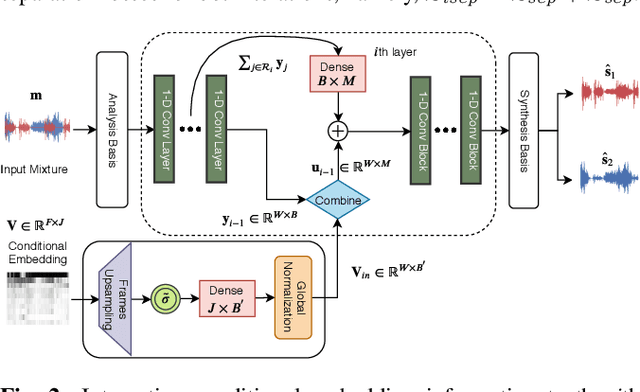
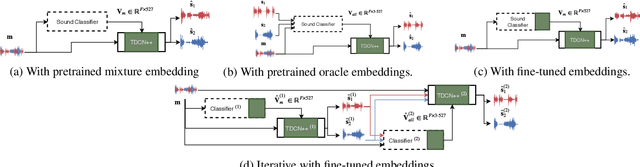
Deep learning approaches have recently achieved impressive performance on both audio source separation and sound classification. Most audio source separation approaches focus only on separating sources belonging to a restricted domain of source classes, such as speech and music. However, recent work has demonstrated the possibility of "universal sound separation", which aims to separate acoustic sources from an open domain, regardless of their class. In this paper, we utilize the semantic information learned by sound classifier networks trained on a vast amount of diverse sounds to improve universal sound separation. In particular, we show that semantic embeddings extracted from a sound classifier can be used to condition a separation network, providing it with useful additional information. This approach is especially useful in an iterative setup, where source estimates from an initial separation stage and their corresponding classifier-derived embeddings are fed to a second separation network. By performing a thorough hyperparameter search consisting of over a thousand experiments, we find that classifier embeddings from clean sources provide nearly one dB of SNR gain, and our best iterative models achieve a significant fraction of this oracle performance, establishing a new state-of-the-art for universal sound separation.
Two-Step Sound Source Separation: Training on Learned Latent Targets
Oct 23, 2019


In this paper, we propose a two-step training procedure for source separation via a deep neural network. In the first step we learn a transform (and it's inverse) to a latent space where masking-based separation performance using oracles is optimal. For the second step, we train a separation module that operates on the previously learned space. In order to do so, we also make use of a scale-invariant signal to distortion ratio (SI-SDR) loss function that works in the latent space, and we prove that it lower-bounds the SI-SDR in the time domain. We run various sound separation experiments that show how this approach can obtain better performance as compared to systems that learn the transform and the separation module jointly. The proposed methodology is general enough to be applicable to a large class of neural network end-to-end separation systems.