 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecaf: Improving Neural Decompilation with Automatic Feedback and Search
May 12, 2026Decompilers are useful tools used in reverse engineering to understand compiled source code. Reconstructing source code from compiled binaries is a challenging task, because high-level syntax, identifiers, and custom data types are generally lost as the compiler translates human-readable code to low-level machine code. Deterministic decompilers are useful tools for binary analysis, but can struggle to infer idiomatic syntax and identifier names. Generative AI models are a natural fit for reconstructing high-level syntax, identifiers, and types, but they can still suffer by hallucinating improper programming constructs and semantics. Instead of attempting to improve neural decompilers with more data and more training, we argue that compiler feedback can be used to dramatically improve the semantic correctness of neural decompiler outputs via search. Our system, Decaf (DECompilation with Automated Feedback), raises the neural decompilation rate from 26.0% on ExeBench to 83.9% on the Real -O2 split without sacrificing similarity to the original source code. We also find our automatic feedback methodology is highly effective for improving weaker neural decompilation models.
Learning to Superoptimize Real-world Programs
Sep 28, 2021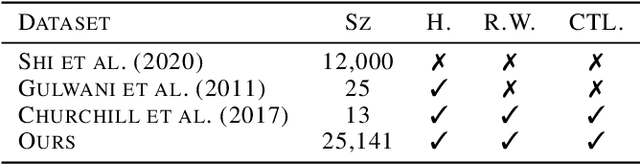
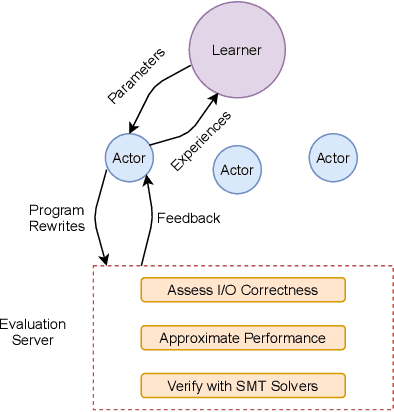

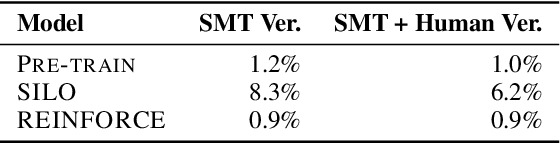
Program optimization is the process of modifying software to execute more efficiently. Because finding the optimal program is generally undecidable, modern compilers usually resort to expert-written heuristic optimizations. In contrast, superoptimizers attempt to find the optimal program by employing significantly more expensive search and constraint solving techniques. Generally, these methods do not scale well to programs in real development scenarios, and as a result superoptimization has largely been confined to small-scale, domain-specific, and/or synthetic program benchmarks. In this paper, we propose a framework to learn to superoptimize real-world programs by using neural sequence-to-sequence models. We introduce the Big Assembly benchmark, a dataset consisting of over 25K real-world functions mined from open-source projects in x86-64 assembly, which enables experimentation on large-scale optimization of real-world programs. We propose an approach, Self Imitation Learning for Optimization (SILO) that is easy to implement and outperforms a standard policy gradient learning approach on our Big Assembly benchmark. Our method, SILO, superoptimizes programs an expected 6.2% of our test set when compared with the gcc version 10.3 compiler's aggressive optimization level -O3. We also report that SILO's rate of superoptimization on our test set is over five times that of a standard policy gradient approach and a model pre-trained on compiler optimization demonstration.