 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProceedings of the Artificial Intelligence for Cyber Security (AICS) Workshop at AAAI 2022
Mar 01, 2022The workshop will focus on the application of AI to problems in cyber security. Cyber systems generate large volumes of data, utilizing this effectively is beyond human capabilities. Additionally, adversaries continue to develop new attacks. Hence, AI methods are required to understand and protect the cyber domain. These challenges are widely studied in enterprise networks, but there are many gaps in research and practice as well as novel problems in other domains. In general, AI techniques are still not widely adopted in the real world. Reasons include: (1) a lack of certification of AI for security, (2) a lack of formal study of the implications of practical constraints (e.g., power, memory, storage) for AI systems in the cyber domain, (3) known vulnerabilities such as evasion, poisoning attacks, (4) lack of meaningful explanations for security analysts, and (5) lack of analyst trust in AI solutions. There is a need for the research community to develop novel solutions for these practical issues.
Out of Distribution Data Detection Using Dropout Bayesian Neural Networks
Feb 18, 2022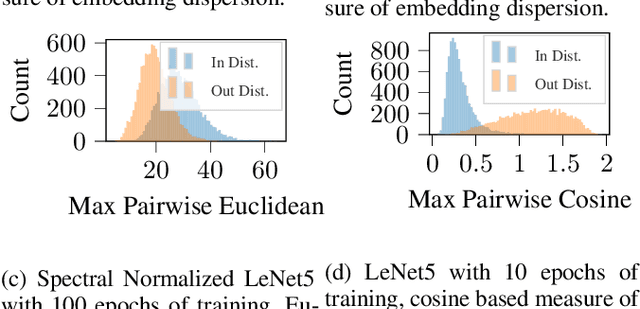
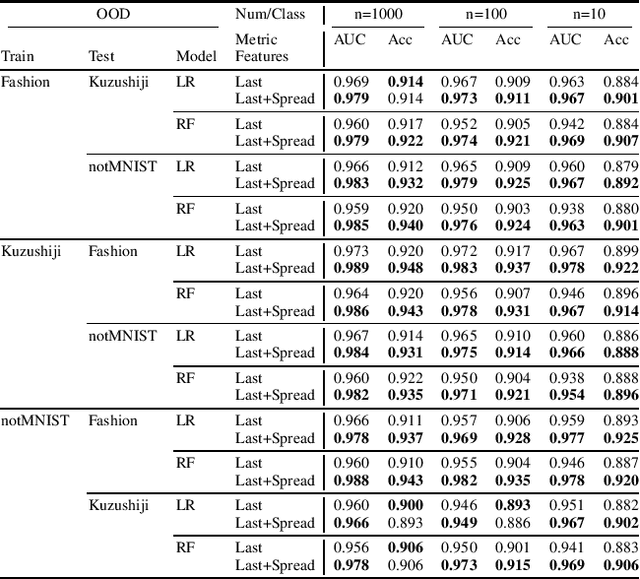
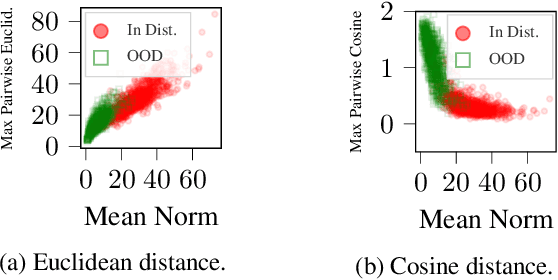
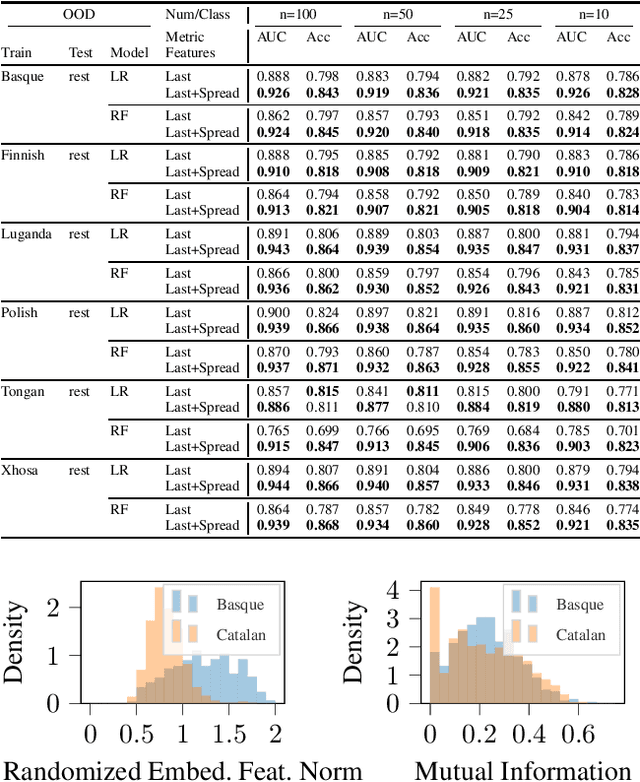
We explore the utility of information contained within a dropout based Bayesian neural network (BNN) for the task of detecting out of distribution (OOD) data. We first show how previous attempts to leverage the randomized embeddings induced by the intermediate layers of a dropout BNN can fail due to the distance metric used. We introduce an alternative approach to measuring embedding uncertainty, justify its use theoretically, and demonstrate how incorporating embedding uncertainty improves OOD data identification across three tasks: image classification, language classification, and malware detection.
Continuously Generalized Ordinal Regression for Linear and Deep Models
Feb 14, 2022

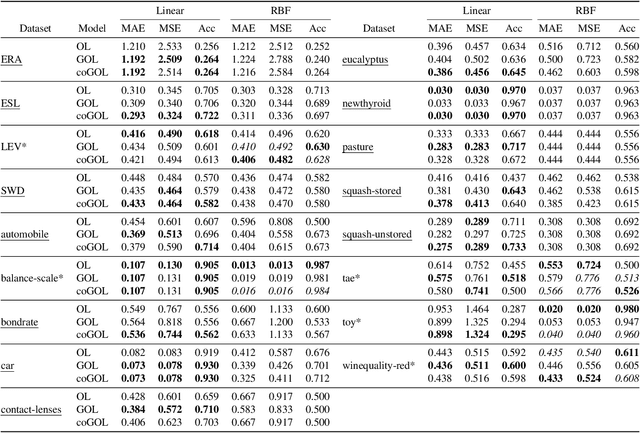
Ordinal regression is a classification task where classes have an order and prediction error increases the further the predicted class is from the true class. The standard approach for modeling ordinal data involves fitting parallel separating hyperplanes that optimize a certain loss function. This assumption offers sample efficient learning via inductive bias, but is often too restrictive in real-world datasets where features may have varying effects across different categories. Allowing class-specific hyperplane slopes creates generalized logistic ordinal regression, increasing the flexibility of the model at a cost to sample efficiency. We explore an extension of the generalized model to the all-thresholds logistic loss and propose a regularization approach that interpolates between these two extremes. Our method, which we term continuously generalized ordinal logistic, significantly outperforms the standard ordinal logistic model over a thorough set of ordinal regression benchmark datasets. We further extend this method to deep learning and show that it achieves competitive or lower prediction error compared to previous models over a range of datasets and modalities. Furthermore, two primary alternative models for deep learning ordinal regression are shown to be special cases of our framework.
Neural Language Models are Effective Plagiarists
Jan 19, 2022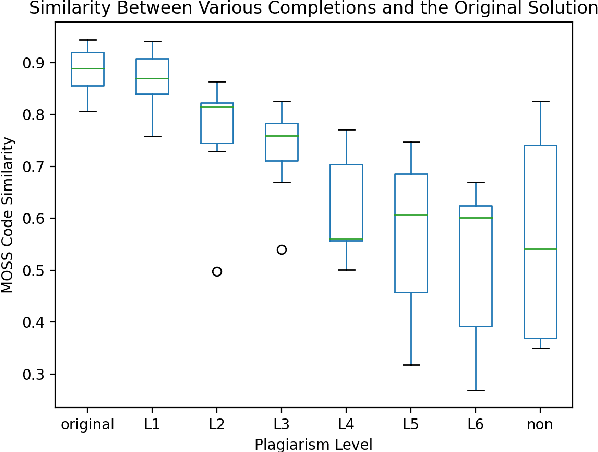


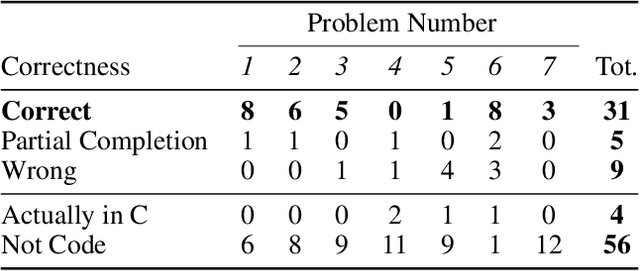
As artificial intelligence (AI) technologies become increasingly powerful and prominent in society, their misuse is a growing concern. In educational settings, AI technologies could be used by students to cheat on assignments and exams. In this paper we explore whether transformers can be used to solve introductory level programming assignments while bypassing commonly used AI tools to detect plagiarism. We find that a student using GPT-J [Wang and Komatsuzaki, 2021] can complete introductory level programming assignments without triggering suspicion from MOSS [Aiken, 2000], a widely used plagiarism detection tool. This holds despite the fact that GPT-J was not trained on the problems in question and is not provided with any examples to work from. We further find that the code written by GPT-J is diverse in structure, lacking any particular tells that future plagiarism detection techniques may use to try to identify algorithmically generated code. We conclude with a discussion of the ethical and educational implications of large language models and directions for future research.
Rank-1 Similarity Matrix Decomposition For Modeling Changes in Antivirus Consensus Through Time
Dec 28, 2021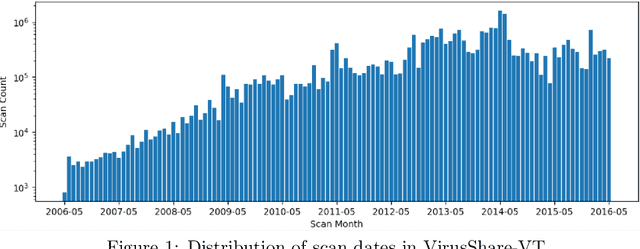
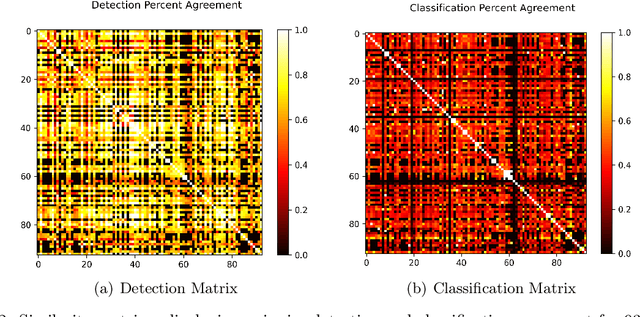
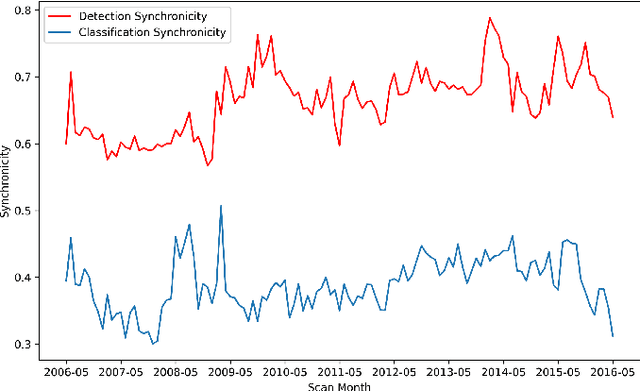
Although groups of strongly correlated antivirus engines are known to exist, at present there is limited understanding of how or why these correlations came to be. Using a corpus of 25 million VirusTotal reports representing over a decade of antivirus scan data, we challenge prevailing wisdom that these correlations primarily originate from "first-order" interactions such as antivirus vendors copying the labels of leading vendors. We introduce the Temporal Rank-1 Similarity Matrix decomposition (R1SM-T) in order to investigate the origins of these correlations and to model how consensus amongst antivirus engines changes over time. We reveal that first-order interactions do not explain as much behavior in antivirus correlation as previously thought, and that the relationships between antivirus engines are highly volatile. We make recommendations on items in need of future study and consideration based on our findings.
Bridging the Gap: Using Deep Acoustic Representations to Learn Grounded Language from Percepts and Raw Speech
Dec 27, 2021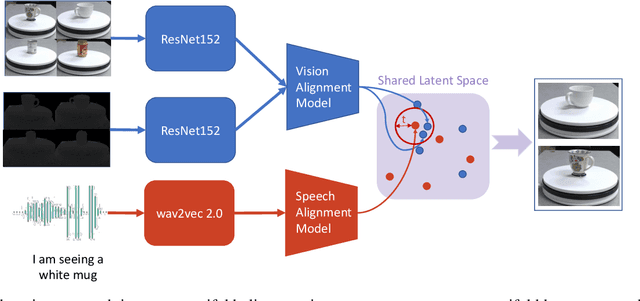
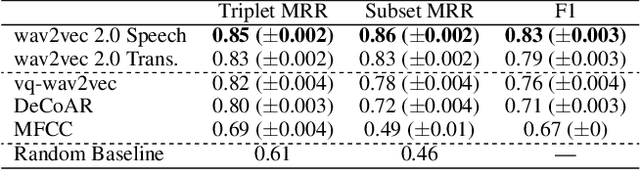
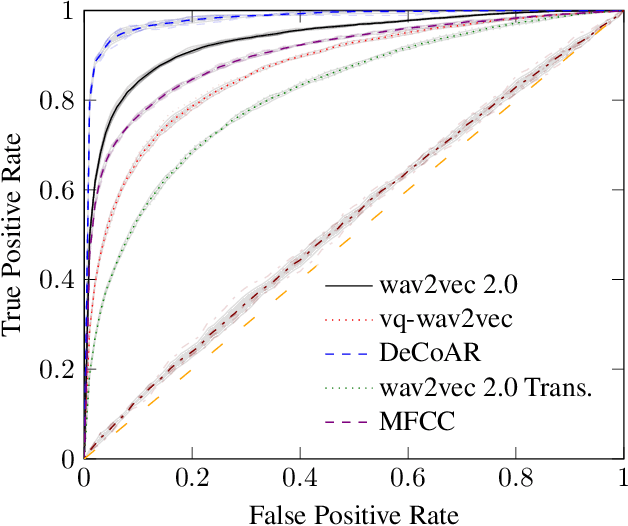
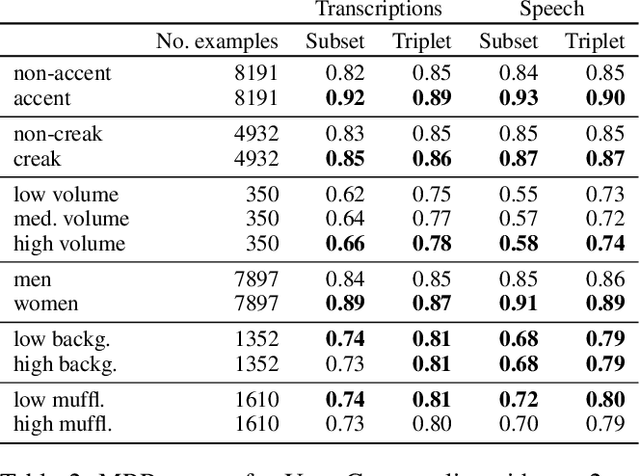
Learning to understand grounded language, which connects natural language to percepts, is a critical research area. Prior work in grounded language acquisition has focused primarily on textual inputs. In this work we demonstrate the feasibility of performing grounded language acquisition on paired visual percepts and raw speech inputs. This will allow interactions in which language about novel tasks and environments is learned from end users, reducing dependence on textual inputs and potentially mitigating the effects of demographic bias found in widely available speech recognition systems. We leverage recent work in self-supervised speech representation models and show that learned representations of speech can make language grounding systems more inclusive towards specific groups while maintaining or even increasing general performance.
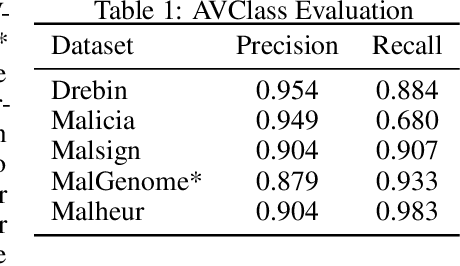
MOTIF: A Large Malware Reference Dataset with Ground Truth Family Labels
Nov 29, 2021
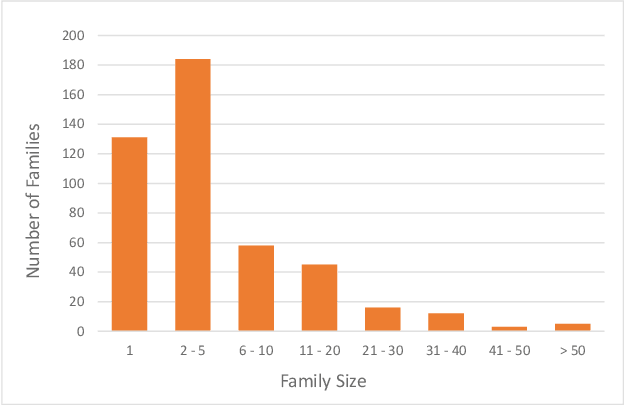

Malware family classification is a significant issue with public safety and research implications that has been hindered by the high cost of expert labels. The vast majority of corpora use noisy labeling approaches that obstruct definitive quantification of results and study of deeper interactions. In order to provide the data needed to advance further, we have created the Malware Open-source Threat Intelligence Family (MOTIF) dataset. MOTIF contains 3,095 malware samples from 454 families, making it the largest and most diverse public malware dataset with ground truth family labels to date, nearly 3x larger than any prior expert-labeled corpus and 36x larger than the prior Windows malware corpus. MOTIF also comes with a mapping from malware samples to threat reports published by reputable industry sources, which both validates the labels and opens new research opportunities in connecting opaque malware samples to human-readable descriptions. This enables important evaluations that are normally infeasible due to non-standardized reporting in industry. For example, we provide aliases of the different names used to describe the same malware family, allowing us to benchmark for the first time accuracy of existing tools when names are obtained from differing sources. Evaluation results obtained using the MOTIF dataset indicate that existing tasks have significant room for improvement, with accuracy of antivirus majority voting measured at only 62.10% and the well-known AVClass tool having just 46.78% accuracy. Our findings indicate that malware family classification suffers a type of labeling noise unlike that studied in most ML literature, due to the large open set of classes that may not be known from the sample under consideration
Adversarial Transfer Attacks With Unknown Data and Class Overlap
Sep 24, 2021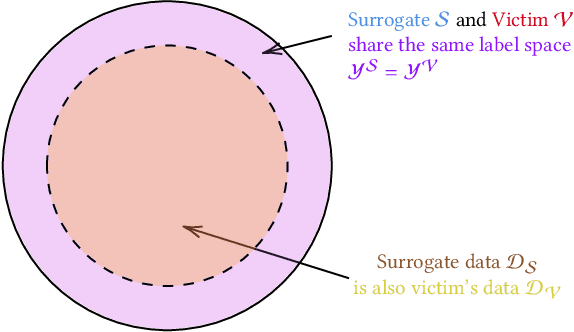
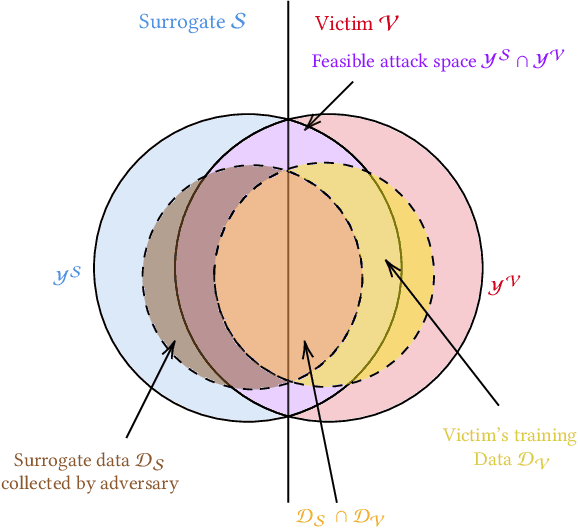
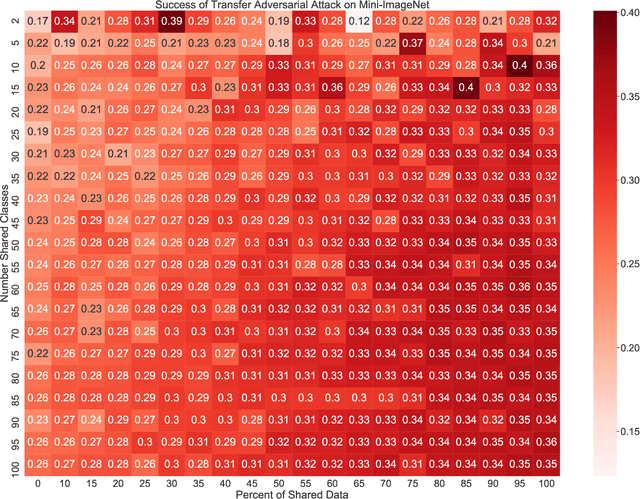
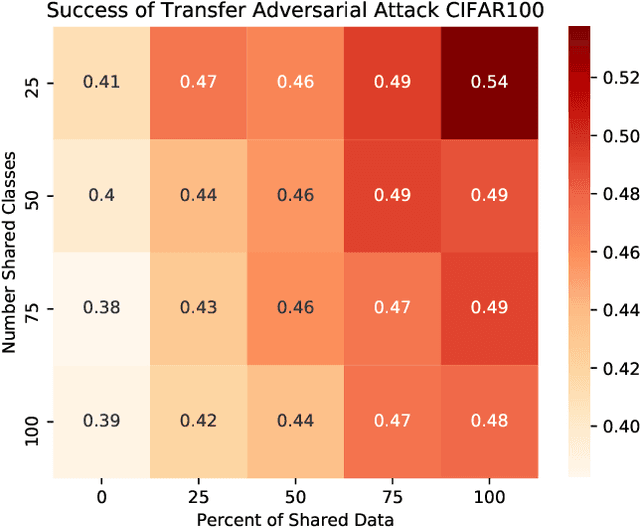
The ability to transfer adversarial attacks from one model (the surrogate) to another model (the victim) has been an issue of concern within the machine learning (ML) community. The ability to successfully evade unseen models represents an uncomfortable level of ease toward implementing attacks. In this work we note that as studied, current transfer attack research has an unrealistic advantage for the attacker: the attacker has the exact same training data as the victim. We present the first study of transferring adversarial attacks focusing on the data available to attacker and victim under imperfect settings without querying the victim, where there is some variable level of overlap in the exact data used or in the classes learned by each model. This threat model is relevant to applications in medicine, malware, and others. Under this new threat model attack success rate is not correlated with data or class overlap in the way one would expect, and varies with dataset. This makes it difficult for attacker and defender to reason about each other and contributes to the broader study of model robustness and security. We remedy this by developing a masked version of Projected Gradient Descent that simulates class disparity, which enables the attacker to reliably estimate a lower-bound on their attack's success.
A Framework for Cluster and Classifier Evaluation in the Absence of Reference Labels
Sep 23, 2021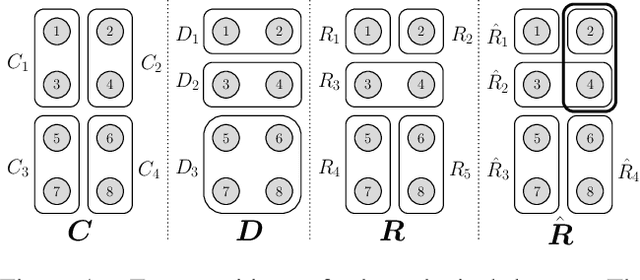
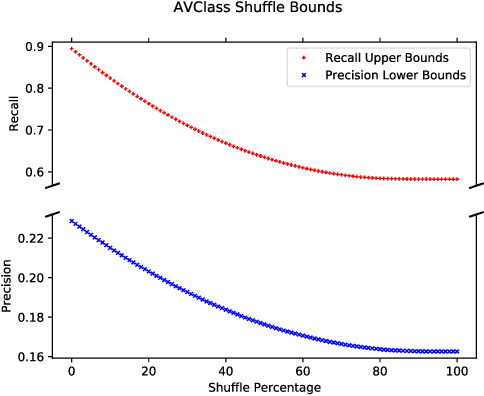
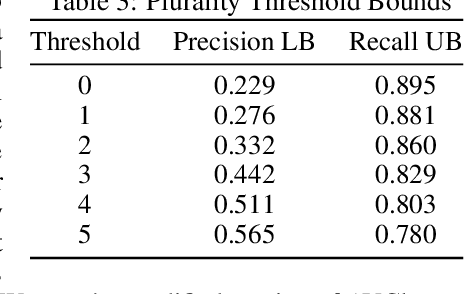
In some problem spaces, the high cost of obtaining ground truth labels necessitates use of lower quality reference datasets. It is difficult to benchmark model performance using these datasets, as evaluation results may be biased. We propose a supplement to using reference labels, which we call an approximate ground truth refinement (AGTR). Using an AGTR, we prove that bounds on specific metrics used to evaluate clustering algorithms and multi-class classifiers can be computed without reference labels. We also introduce a procedure that uses an AGTR to identify inaccurate evaluation results produced from datasets of dubious quality. Creating an AGTR requires domain knowledge, and malware family classification is a task with robust domain knowledge approaches that support the construction of an AGTR. We demonstrate our AGTR evaluation framework by applying it to a popular malware labeling tool to diagnose over-fitting in prior testing and evaluate changes whose impact could not be meaningfully quantified under previous data.
Learning with Holographic Reduced Representations
Sep 05, 2021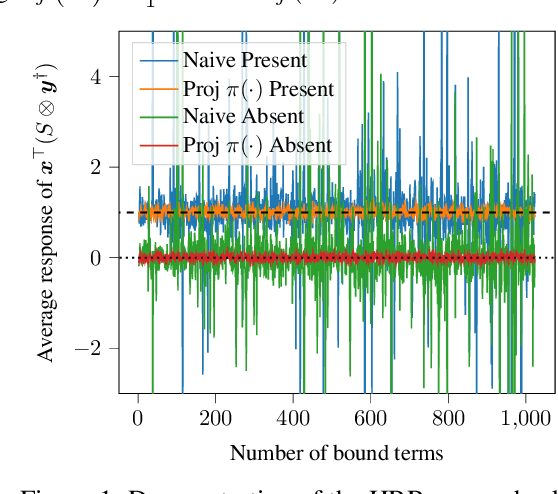
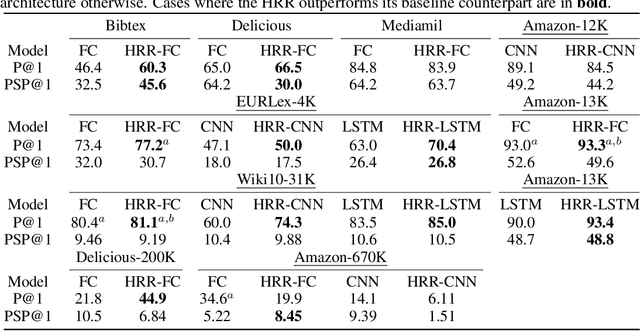
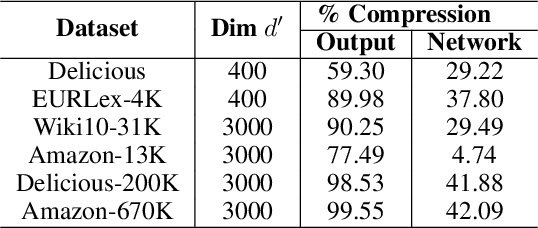
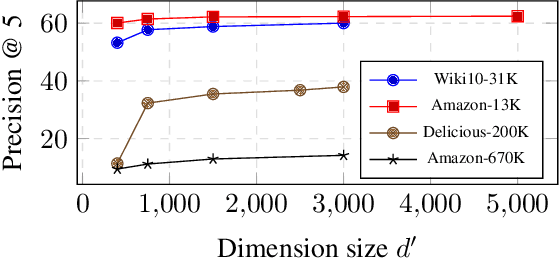
Holographic Reduced Representations (HRR) are a method for performing symbolic AI on top of real-valued vectors \cite{Plate1995} by associating each vector with an abstract concept, and providing mathematical operations to manipulate vectors as if they were classic symbolic objects. This method has seen little use outside of older symbolic AI work and cognitive science. Our goal is to revisit this approach to understand if it is viable for enabling a hybrid neural-symbolic approach to learning as a differentiable component of a deep learning architecture. HRRs today are not effective in a differentiable solution due to numerical instability, a problem we solve by introducing a projection step that forces the vectors to exist in a well behaved point in space. In doing so we improve the concept retrieval efficacy of HRRs by over $100\times$. Using multi-label classification we demonstrate how to leverage the symbolic HRR properties to develop an output layer and loss function that is able to learn effectively, and allows us to investigate some of the pros and cons of an HRR neuro-symbolic learning approach.