 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTerraBind: Fast and Accurate Binding Affinity Prediction through Coarse Structural Representations
Feb 08, 2026We present TerraBind, a foundation model for protein-ligand structure and binding affinity prediction that achieves 26-fold faster inference than state-of-the-art methods while improving affinity prediction accuracy by $\sim$20\%. Current deep learning approaches to structure-based drug design rely on expensive all-atom diffusion to generate 3D coordinates, creating inference bottlenecks that render large-scale compound screening computationally intractable. We challenge this paradigm with a critical hypothesis: full all-atom resolution is unnecessary for accurate small molecule pose and binding affinity prediction. TerraBind tests this hypothesis through a coarse pocket-level representation (protein C$_β$ atoms and ligand heavy atoms only) within a multimodal architecture combining COATI-3 molecular encodings and ESM-2 protein embeddings that learns rich structural representations, which are used in a diffusion-free optimization module for pose generation and a binding affinity likelihood prediction module. On structure prediction benchmarks (FoldBench, PoseBusters, Runs N' Poses), TerraBind matches diffusion-based baselines in ligand pose accuracy. Crucially, TerraBind outperforms Boltz-2 by $\sim$20\% in Pearson correlation for binding affinity prediction on both a public benchmark (CASP16) and a diverse proprietary dataset (18 biochemical/cell assays). We show that the affinity prediction module also provides well-calibrated affinity uncertainty estimates, addressing a critical gap in reliable compound prioritization for drug discovery. Furthermore, this module enables a continual learning framework and a hedged batch selection strategy that, in simulated drug discovery cycles, achieves 6$\times$ greater affinity improvement of selected molecules over greedy-based approaches.
DeepScribe: Localization and Classification of Elamite Cuneiform Signs Via Deep Learning
Jun 02, 2023



Twenty-five hundred years ago, the paperwork of the Achaemenid Empire was recorded on clay tablets. In 1933, archaeologists from the University of Chicago's Oriental Institute (OI) found tens of thousands of these tablets and fragments during the excavation of Persepolis. Many of these tablets have been painstakingly photographed and annotated by expert cuneiformists, and now provide a rich dataset consisting of over 5,000 annotated tablet images and 100,000 cuneiform sign bounding boxes. We leverage this dataset to develop DeepScribe, a modular computer vision pipeline capable of localizing cuneiform signs and providing suggestions for the identity of each sign. We investigate the difficulty of learning subtasks relevant to cuneiform tablet transcription on ground-truth data, finding that a RetinaNet object detector can achieve a localization mAP of 0.78 and a ResNet classifier can achieve a top-5 sign classification accuracy of 0.89. The end-to-end pipeline achieves a top-5 classification accuracy of 0.80. As part of the classification module, DeepScribe groups cuneiform signs into morphological clusters. We consider how this automatic clustering approach differs from the organization of standard, printed sign lists and what we may learn from it. These components, trained individually, are sufficient to produce a system that can analyze photos of cuneiform tablets from the Achaemenid period and provide useful transliteration suggestions to researchers. We evaluate the model's end-to-end performance on locating and classifying signs, providing a roadmap to a linguistically-aware transliteration system, then consider the model's potential utility when applied to other periods of cuneiform writing.
A Tale of Two DRAGGNs: A Hybrid Approach for Interpreting Action-Oriented and Goal-Oriented Instructions
Jul 26, 2017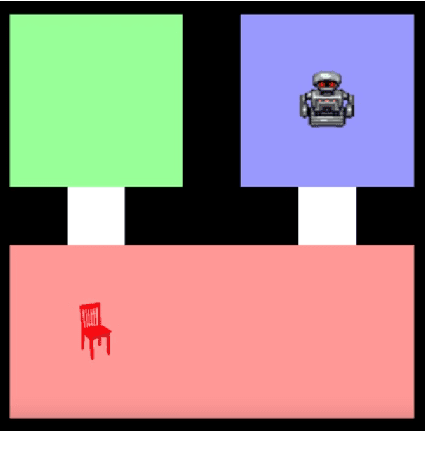
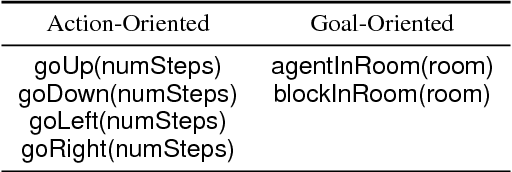
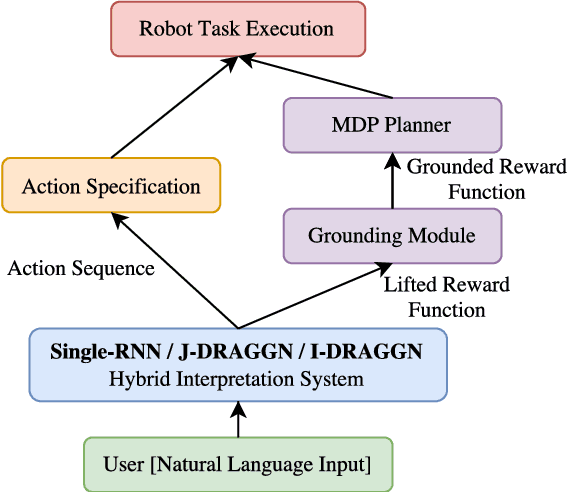

Robots operating alongside humans in diverse, stochastic environments must be able to accurately interpret natural language commands. These instructions often fall into one of two categories: those that specify a goal condition or target state, and those that specify explicit actions, or how to perform a given task. Recent approaches have used reward functions as a semantic representation of goal-based commands, which allows for the use of a state-of-the-art planner to find a policy for the given task. However, these reward functions cannot be directly used to represent action-oriented commands. We introduce a new hybrid approach, the Deep Recurrent Action-Goal Grounding Network (DRAGGN), for task grounding and execution that handles natural language from either category as input, and generalizes to unseen environments. Our robot-simulation results demonstrate that a system successfully interpreting both goal-oriented and action-oriented task specifications brings us closer to robust natural language understanding for human-robot interaction.