 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTarget-Aware Contextual Political Bias Detection in News
Oct 02, 2023



Media bias detection requires comprehensive integration of information derived from multiple news sources. Sentence-level political bias detection in news is no exception, and has proven to be a challenging task that requires an understanding of bias in consideration of the context. Inspired by the fact that humans exhibit varying degrees of writing styles, resulting in a diverse range of statements with different local and global contexts, previous work in media bias detection has proposed augmentation techniques to exploit this fact. Despite their success, we observe that these techniques introduce noise by over-generalizing bias context boundaries, which hinders performance. To alleviate this issue, we propose techniques to more carefully search for context using a bias-sensitive, target-aware approach for data augmentation. Comprehensive experiments on the well-known BASIL dataset show that when combined with pre-trained models such as BERT, our augmentation techniques lead to state-of-the-art results. Our approach outperforms previous methods significantly, obtaining an F1-score of 58.15 over state-of-the-art bias detection task.
Towards Parameter-Efficient Integration of Pre-Trained Language Models In Temporal Video Grounding
Sep 26, 2022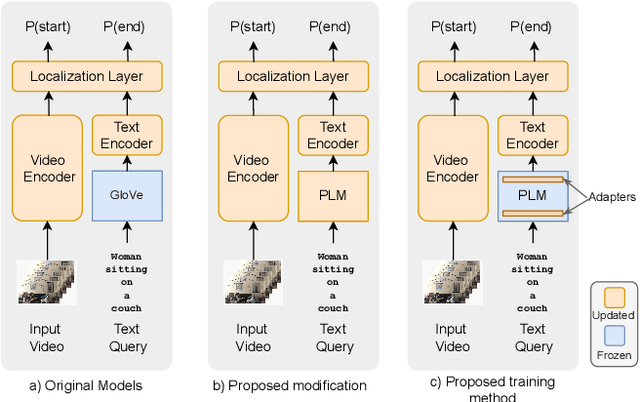
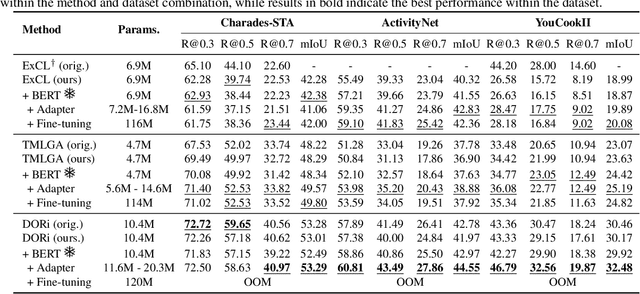
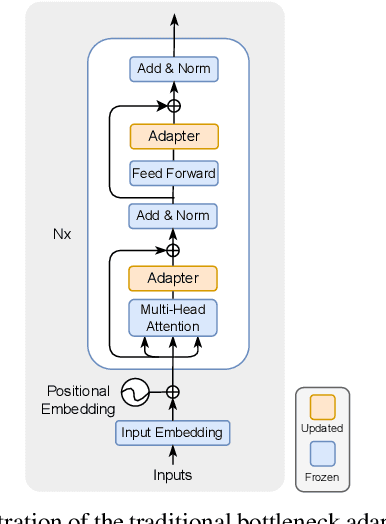
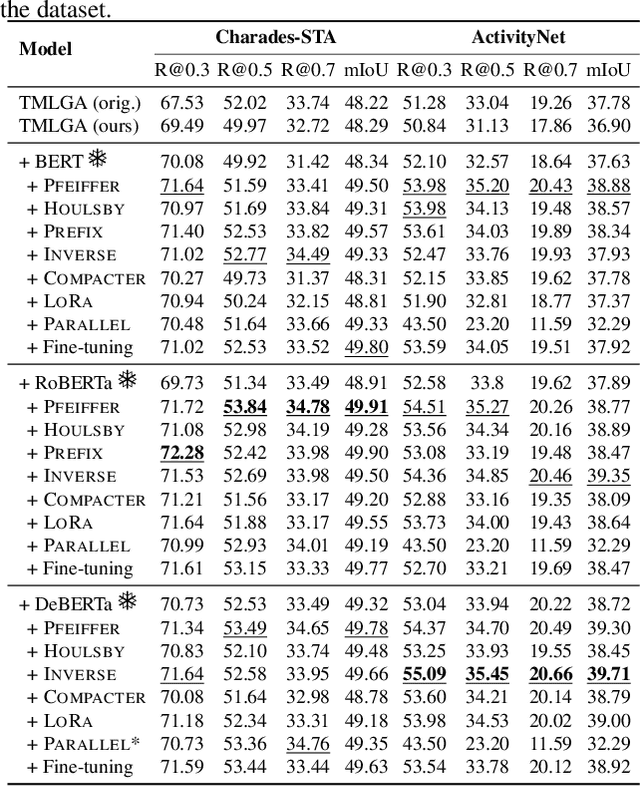
This paper explores the task of Temporal Video Grounding (TVG) where, given an untrimmed video and a query sentence, the goal is to recognize and determine temporal boundaries of action instances in the video described by the provided natural language queries. Recent works solve this task by directly encoding the query using large pre-trained language models (PLM). However, isolating the effects of the improved language representations is difficult, as these works also propose improvements in the visual inputs. Furthermore, these PLMs significantly increase the computational cost of training TVG models. Therefore, this paper studies the effects of PLMs in the TVG task and assesses the applicability of NLP parameter-efficient training alternatives based on adapters. We couple popular PLMs with a selection of existing approaches and test different adapters to reduce the impact of the additional parameters. Our results on three challenging datasets show that TVG models could greatly benefit from PLMs when these are fine-tuned for the task and that adapters are an effective alternative to full fine-tuning, even though they are not tailored for our task. Concretely, adapters helped save on computational cost, allowing PLM integration in larger TVG models and delivering results comparable to the state-of-the-art models. Finally, through benchmarking different types of adapters in TVG, our results shed light on what kind of adapters work best for each studied case.
LocFormer: Enabling Transformers to Perform Temporal Moment Localization on Long Untrimmed Videos With a Feature Sampling Approach
Dec 19, 2021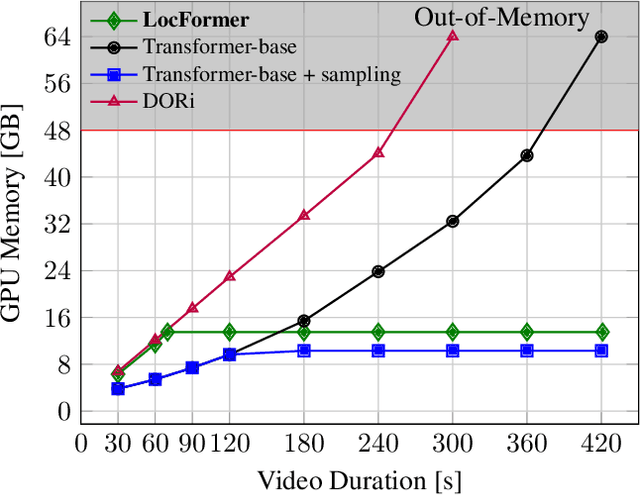
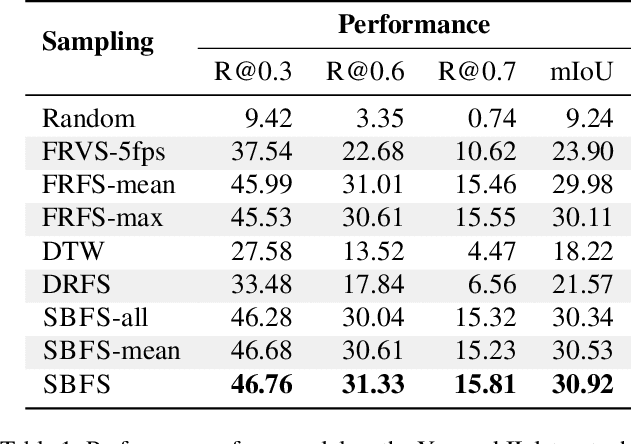
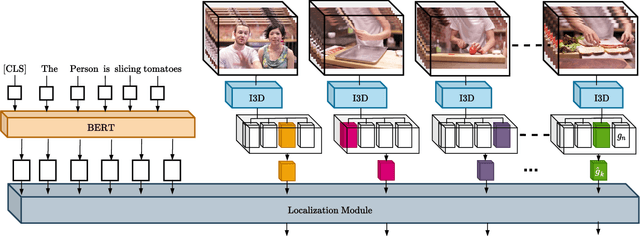
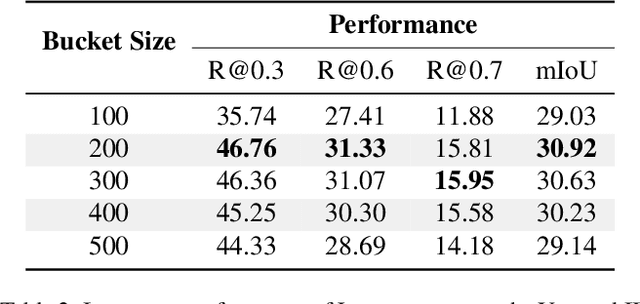
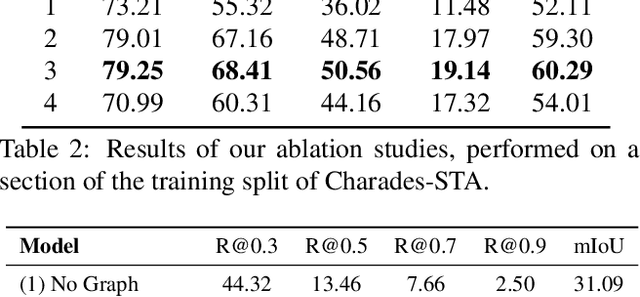
We propose LocFormer, a Transformer-based model for video grounding which operates at a constant memory footprint regardless of the video length, i.e. number of frames. LocFormer is designed for tasks where it is necessary to process the entire long video and at its core lie two main contributions. First, our model incorporates a new sampling technique that splits the input feature sequence into a fixed number of sections and selects a single feature per section using a stochastic approach, which allows us to obtain a feature sample set that is representative of the video content for the task at hand while keeping the memory footprint constant. Second, we propose a modular design that separates functionality, enabling us to learn an inductive bias via supervising the self-attention heads, while also effectively leveraging pre-trained text and video encoders. We test our proposals on relevant benchmark datasets for video grounding, showing that not only LocFormer can achieve excellent results including state-of-the-art performance on YouCookII, but also that our sampling technique is more effective than competing counterparts and that it consistently improves the performance of prior work, by up to 3.13\% in the mean temporal IoU, ultimately leading to a new state-of-the-art performance on Charades-STA.
Subformer: Exploring Weight Sharing for Parameter Efficiency in Generative Transformers
Jan 01, 2021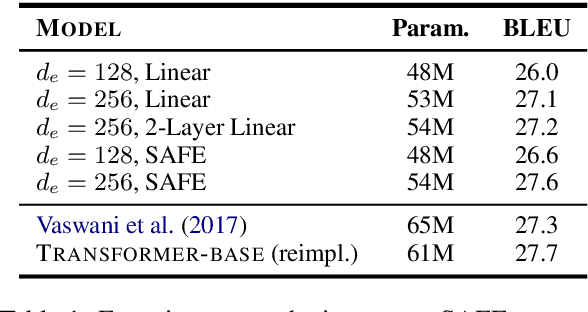
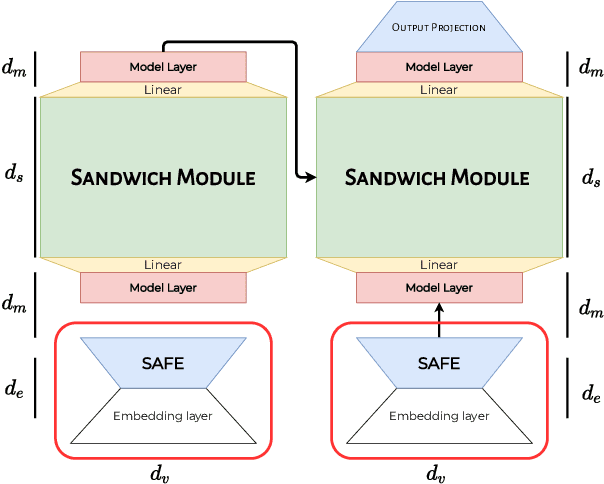
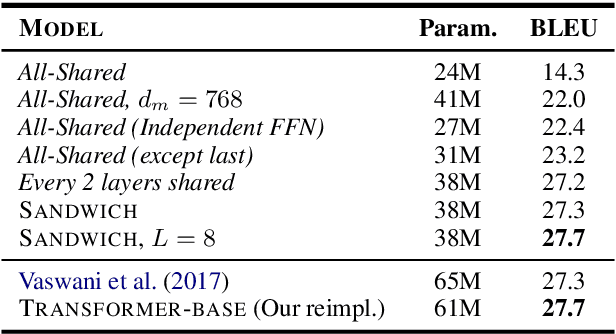

The advent of the Transformer can arguably be described as a driving force behind many of the recent advances in natural language processing. However, despite their sizeable performance improvements, as recently shown, the model is severely over-parameterized, being parameter inefficient and computationally expensive to train. Inspired by the success of parameter-sharing in pretrained deep contextualized word representation encoders, we explore parameter-sharing methods in Transformers, with a specific focus on encoder-decoder models for sequence-to-sequence tasks such as neural machine translation. We perform an analysis of different parameter sharing/reduction methods and develop the Subformer, a parameter efficient Transformer-based model which combines the newly proposed Sandwich-style parameter sharing technique - designed to overcome the deficiencies in naive cross-layer parameter sharing for generative models - and self-attentive embedding factorization (SAFE). Experiments on machine translation, abstractive summarization, and language modeling show that the Subformer can outperform the Transformer even when using significantly fewer parameters.
DORi: Discovering Object Relationship for Moment Localization of a Natural-Language Query in Video
Oct 13, 2020
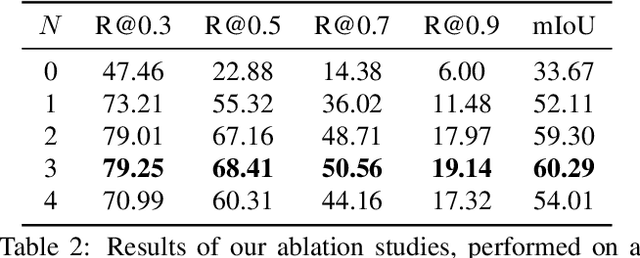
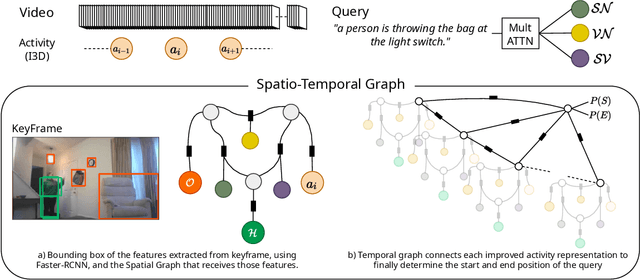
This paper studies the task of temporal moment localization in a long untrimmed video using natural language query. Given a query sentence, the goal is to determine the start and end of the relevant segment within the video. Our key innovation is to learn a video feature embedding through a language-conditioned message-passing algorithm suitable for temporal moment localization which captures the relationships between humans, objects and activities in the video. These relationships are obtained by a spatial sub-graph that contextualizes the scene representation using detected objects and human features conditioned in the language query. Moreover, a temporal sub-graph captures the activities within the video through time. Our method is evaluated on three standard benchmark datasets, and we also introduce YouCookII as a new benchmark for this task. Experiments show our method outperforms state-of-the-art methods on these datasets, confirming the effectiveness of our approach.
VCDM: Leveraging Variational Bi-encoding and Deep Contextualized Word Representations for Improved Definition Modeling
Oct 07, 2020
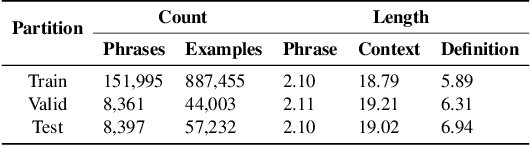

In this paper, we tackle the task of definition modeling, where the goal is to learn to generate definitions of words and phrases. Existing approaches for this task are discriminative, combining distributional and lexical semantics in an implicit rather than direct way. To tackle this issue we propose a generative model for the task, introducing a continuous latent variable to explicitly model the underlying relationship between a phrase used within a context and its definition. We rely on variational inference for estimation and leverage contextualized word embeddings for improved performance. Our approach is evaluated on four existing challenging benchmarks with the addition of two new datasets, "Cambridge" and the first non-English corpus "Robert", which we release to complement our empirical study. Our Variational Contextual Definition Modeler (VCDM) achieves state-of-the-art performance in terms of automatic and human evaluation metrics, demonstrating the effectiveness of our approach.
A Multi-modal Approach to Fine-grained Opinion Mining on Video Reviews
May 28, 2020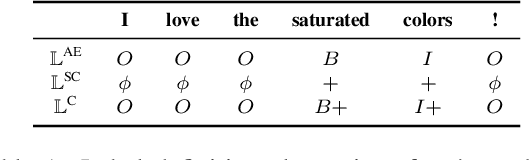
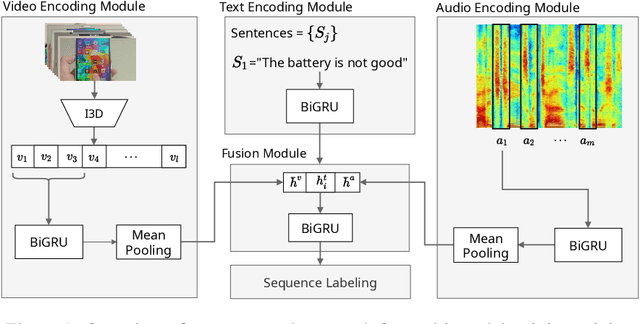
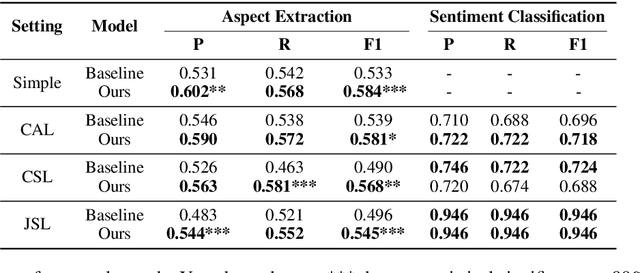
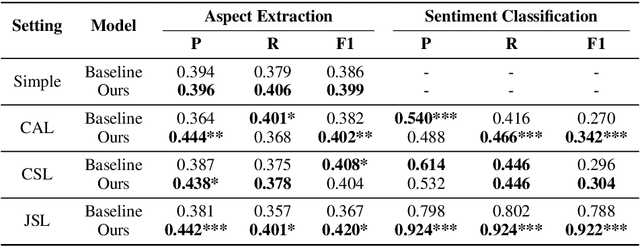
Despite the recent advances in opinion mining for written reviews, few works have tackled the problem on other sources of reviews. In light of this issue, we propose a multi-modal approach for mining fine-grained opinions from video reviews that is able to determine the aspects of the item under review that are being discussed and the sentiment orientation towards them. Our approach works at the sentence level without the need for time annotations and uses features derived from the audio, video and language transcriptions of its contents. We evaluate our approach on two datasets and show that leveraging the video and audio modalities consistently provides increased performance over text-only baselines, providing evidence these extra modalities are key in better understanding video reviews.
Variational Inference for Learning Representations of Natural Language Edits
May 18, 2020
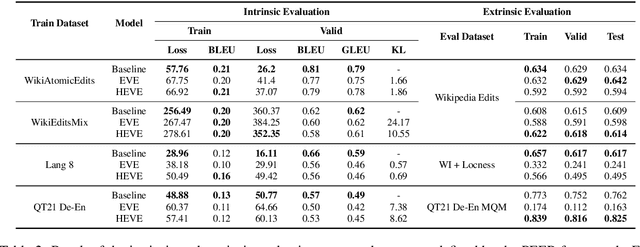
Document editing has become a pervasive component of production of information, with version control systems enabling edits to be efficiently stored and applied. In light of this, the task of learning distributed representations of edits has been recently proposed. With this in mind, we propose a novel approach that employs variational inference to learn a continuous latent space of vector representations to capture the underlying semantic information with regard to the document editing process. We achieve this by introducing a latent variable to explicitly model the aforementioned features. This latent variable is then combined with a document representation to guide the generation of an edited-version of this document. Additionally, to facilitate standardized automatic evaluation of edit representations, which has heavily relied on direct human input thus far, we also propose a suite of downstream tasks, PEER, specifically designed to measure the quality of edit representations in the context of Natural Language Processing.
Combining Pretrained High-Resource Embeddings and Subword Representations for Low-Resource Languages
Mar 11, 2020
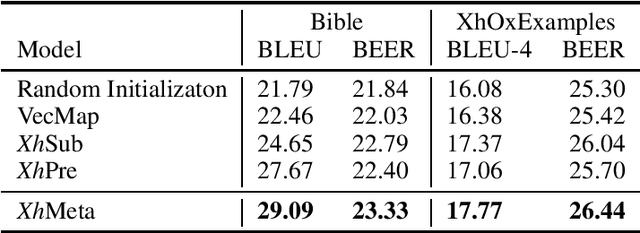
The contrast between the need for large amounts of data for current Natural Language Processing (NLP) techniques, and the lack thereof, is accentuated in the case of African languages, most of which are considered low-resource. To help circumvent this issue, we explore techniques exploiting the qualities of morphologically rich languages (MRLs), while leveraging pretrained word vectors in well-resourced languages. In our exploration, we show that a meta-embedding approach combining both pretrained and morphologically-informed word embeddings performs best in the downstream task of Xhosa-English translation.
An Edit-centric Approach for Wikipedia Article Quality Assessment
Sep 19, 2019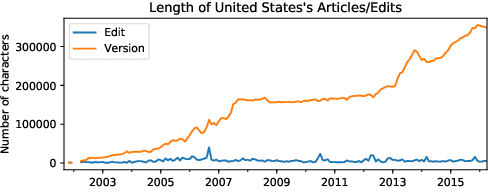
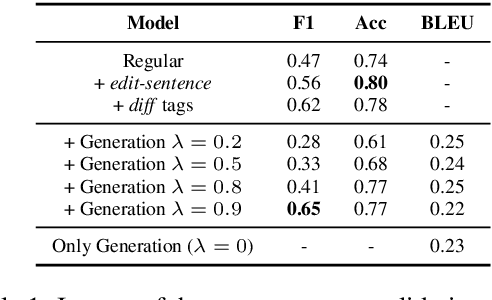
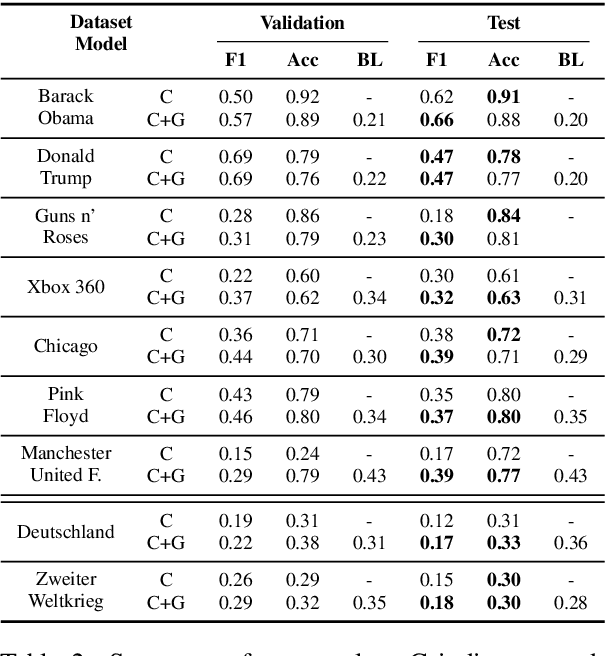
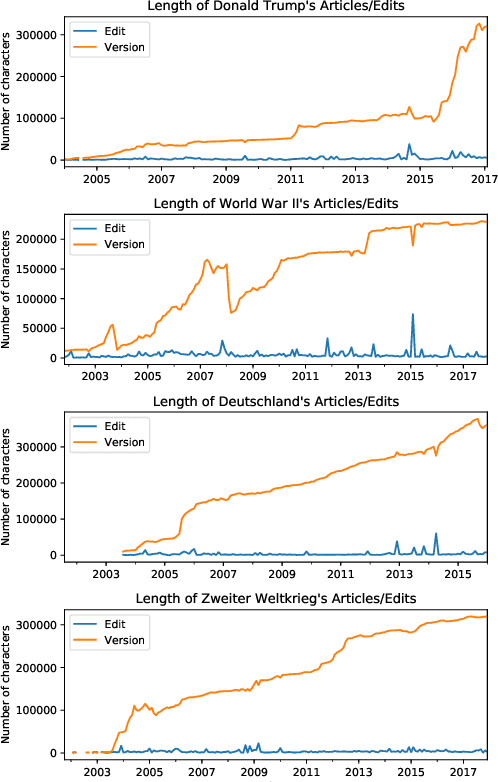
We propose an edit-centric approach to assess Wikipedia article quality as a complementary alternative to current full document-based techniques. Our model consists of a main classifier equipped with an auxiliary generative module which, for a given edit, jointly provides an estimation of its quality and generates a description in natural language. We performed an empirical study to assess the feasibility of the proposed model and its cost-effectiveness in terms of data and quality requirements.