 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisualizing Critic Match Loss Landscapes for Interpretation of Online Reinforcement Learning Control Algorithms
Mar 15, 2026Reinforcement learning has proven its power on various occasions. However, its performance is not always guaranteed when system dynamics change. Instead, it largely relies on users' empirical experience. For reinforcement learning algorithms with an actor-critic structure, the critic neural network reflects the approximation and optimization process in the RL algorithm. Analyzing the performance of the critic neural network helps to understand the mechanism of the algorithm. To support systematic interpretation of such algorithms in dynamic control problems, this work proposes a critic match loss landscape visualization method for online reinforcement learning. The method constructs a loss landscape by projecting recorded critic parameter trajectories onto a low-dimensional linear subspace. The critic match loss is evaluated over the projected parameter grid using fixed reference state samples and temporal-difference targets. This yields a three-dimensional loss surface together with a two-dimensional optimization path that characterizes critic learning behavior. To extend analysis beyond visual inspection, quantitative landscape indices and a normalized system performance index are introduced, enabling structured comparison across different training outcomes. The approach is demonstrated using the Action-Dependent Heuristic Dynamic Programming algorithm on cart-pole and spacecraft attitude control tasks. Comparative analyses across projection methods and training stages reveal distinct landscape characteristics associated with stable convergence and unstable learning. The proposed framework enables both qualitative and quantitative interpretation of critic optimization behavior in online reinforcement learning.
Adapting Critic Match Loss Landscape Visualization to Off-policy Reinforcement Learning
Mar 15, 2026This work extends an established critic match loss landscape visualization method from online to off-policy reinforcement learning (RL), aiming to reveal the optimization geometry behind critic learning. Off-policy RL differs from stepwise online actor-critic learning in its replay-based data flow and target computation. Based on these two structural differences, the critic match loss landscape visualization method is adapted to the Soft Actor-Critic (SAC) algorithm by aligning the loss evaluation with its batch-based data flow and target computation, using a fixed replay batch and precomputed critic targets from the selected policy. Critic parameters recorded during training are projected onto a principal component plane, where the critic match loss is evaluated to form a 3-D landscape with an overlaid 2-D optimization path. Applied to a spacecraft attitude control problem, the resulting landscapes are analyzed both qualitatively and quantitatively using sharpness, basin area, and local anisotropy metrics, together with temporal landscape snapshots. Comparisons between convergent SAC, divergent SAC, and divergent Action-Dependent Heuristic Dynamic Programming (ADHDP) cases reveal distinct geometric patterns and optimization behaviors under different algorithmic structures. The results demonstrate that the adapted critic match loss visualization framework serves as a geometric diagnostic tool for analyzing critic optimization dynamics in replay-based off-policy RL-based control problems.
A Loss Landscape Visualization Framework for Interpreting Reinforcement Learning: An ADHDP Case Study
Mar 15, 2026Reinforcement learning algorithms have been widely used in dynamic and control systems. However, interpreting their internal learning behavior remains a challenge. In the authors' previous work, a critic match loss landscape visualization method was proposed to study critic training. This study extends that method into a framework which provides a multi-perspective view of the learning dynamics, clarifying how value estimation, policy optimization, and temporal-difference (TD) signals interact during training. The proposed framework includes four complementary components; a three-dimensional reconstruction of the critic match loss surface that shows how TD targets shape the optimization geometry; an actor loss landscape under a frozen critic that reveals how the policy exploits that geometry; a trajectory combining time, Bellman error, and policy weights that indicates how updates move across the surface; and a state-TD map that identifies the state regions that drive those updates. The Action-Dependent Heuristic Dynamic Programming (ADHDP) algorithm for spacecraft attitude control is used as a case study. The framework is applied to compare several ADHDP variants and shows how training stabilizers and target updates change the optimization landscape and affect learning stability. Therefore, the proposed framework provides a systematic and interpretable tool for analyzing reinforcement learning behavior across algorithmic designs.
Onboard-Targeted Segmentation of Straylight in Space Camera Sensors
Feb 24, 2026This study details an artificial intelligence (AI)-based methodology for the semantic segmentation of space camera faults. Specifically, we address the segmentation of straylight effects induced by solar presence around the camera's Field of View (FoV). Anomalous images are sourced from our published dataset. Our approach emphasizes generalization across diverse flare textures, leveraging pre-training on a public dataset (Flare7k++) including flares in various non-space contexts to mitigate the scarcity of realistic space-specific data. A DeepLabV3 model with MobileNetV3 backbone performs the segmentation task. The model design targets deployment in spacecraft resource-constrained hardware. Finally, based on a proposed interface between our model and the onboard navigation pipeline, we develop custom metrics to assess the model's performance in the system-level context.
Addressing Camera Sensors Faults in Vision-Based Navigation: Simulation and Dataset Development
Jul 03, 2025The increasing importance of Vision-Based Navigation (VBN) algorithms in space missions raises numerous challenges in ensuring their reliability and operational robustness. Sensor faults can lead to inaccurate outputs from navigation algorithms or even complete data processing faults, potentially compromising mission objectives. Artificial Intelligence (AI) offers a powerful solution for detecting such faults, overcoming many of the limitations associated with traditional fault detection methods. However, the primary obstacle to the adoption of AI in this context is the lack of sufficient and representative datasets containing faulty image data. This study addresses these challenges by focusing on an interplanetary exploration mission scenario. A comprehensive analysis of potential fault cases in camera sensors used within the VBN pipeline is presented. The causes and effects of these faults are systematically characterized, including their impact on image quality and navigation algorithm performance, as well as commonly employed mitigation strategies. To support this analysis, a simulation framework is introduced to recreate faulty conditions in synthetically generated images, enabling a systematic and controlled reproduction of faulty data. The resulting dataset of fault-injected images provides a valuable tool for training and testing AI-based fault detection algorithms. The final link to the dataset will be added after an embargo period. For peer-reviewers, this private link is available.
Convolutional Neural Network Design and Evaluation for Real-Time Multivariate Time Series Fault Detection in Spacecraft Attitude Sensors
Oct 11, 2024



Traditional anomaly detection techniques onboard satellites are based on reliable, yet limited, thresholding mechanisms which are designed to monitor univariate signals and trigger recovery actions according to specific European Cooperation for Space Standardization (ECSS) standards. However, Artificial Intelligence-based Fault Detection, Isolation and Recovery (FDIR) solutions have recently raised with the prospect to overcome the limitations of these standard methods, expanding the range of detectable failures and improving response times. This paper presents a novel approach to detecting stuck values within the Accelerometer and Inertial Measurement Unit of a drone-like spacecraft for the exploration of Small Solar System Bodies (SSSB), leveraging a multi-channel Convolutional Neural Network (CNN) to perform multi-target classification and independently detect faults in the sensors. Significant attention has been dedicated to ensuring the compatibility of the algorithm within the onboard FDIR system, representing a step forward to the in-orbit validation of a technology that remains experimental until its robustness is thoroughly proven. An integration methodology is proposed to enable the network to effectively detect anomalies and trigger recovery actions at the system level. The detection performances and the capability of the algorithm in reaction triggering are evaluated employing a set of custom-defined detection and system metrics, showing the outstanding performances of the algorithm in performing its FDIR task.
A model-based framework for learning transparent swarm behaviors
Mar 09, 2021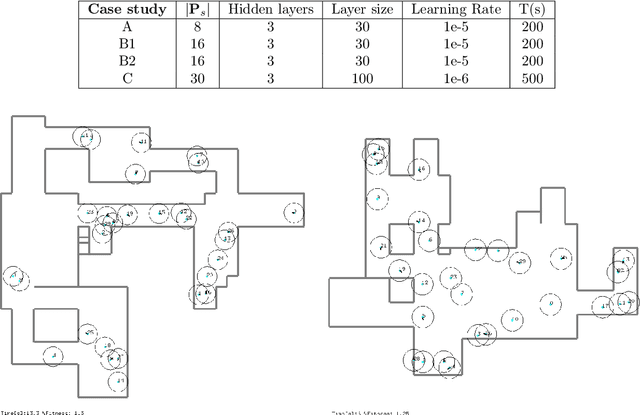
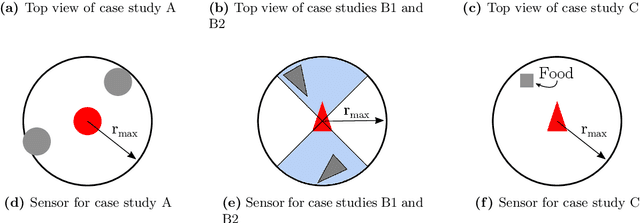
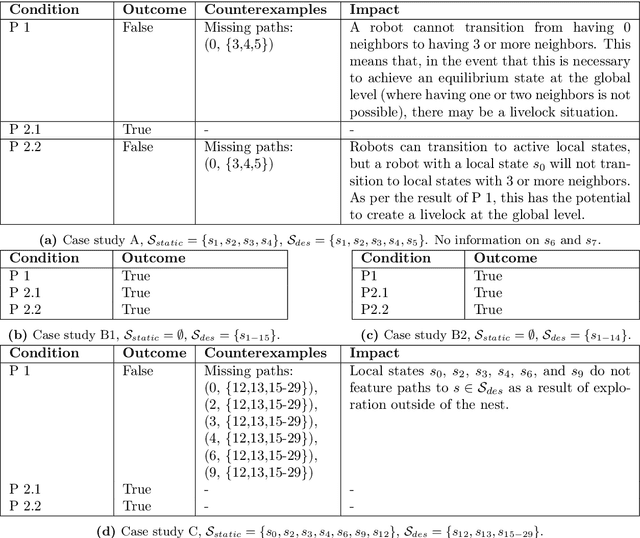
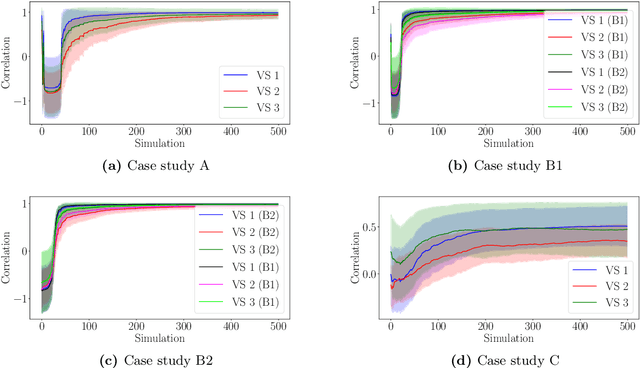
This paper proposes a model-based framework to automatically and efficiently design understandable and verifiable behaviors for swarms of robots. The framework is based on the automatic extraction of two distinct models: 1) a neural network model trained to estimate the relationship between the robots' sensor readings and the global performance of the swarm, and 2) a probabilistic state transition model that explicitly models the local state transitions (i.e., transitions in observations from the perspective of a single robot in the swarm) given a policy. The models can be trained from a data set of simulated runs featuring random policies. The first model is used to automatically extract a set of local states that are expected to maximize the global performance. These local states are referred to as desired local states. The second model is used to optimize a stochastic policy so as to increase the probability that the robots in the swarm observe one of the desired local states. Following these steps, the framework proposed in this paper can efficiently lead to effective controllers. This is tested on four case studies, featuring aggregation and foraging tasks. Importantly, thanks to the models, the framework allows us to understand and inspect a swarm's behavior. To this end, we propose verification checks to identify some potential issues that may prevent the swarm from achieving the desired global objective. In addition, we explore how the framework can be used in combination with a "standard" evolutionary robotics strategy (i.e., where performance is measured via simulation), or with online learning.