 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Latent Morphology Model for Open-Vocabulary Neural Machine Translation
Oct 30, 2019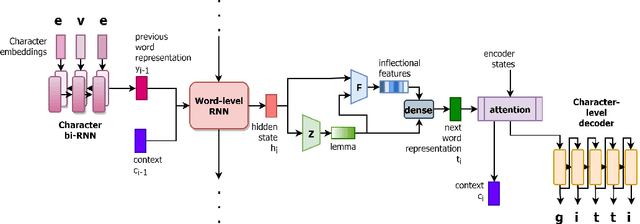

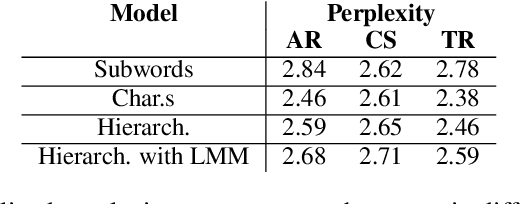
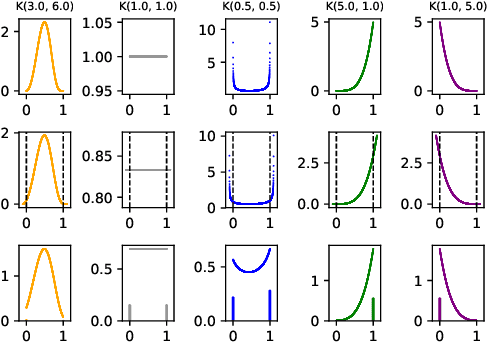
Translation into morphologically-rich languages challenges neural machine translation (NMT) models with extremely sparse vocabularies where atomic treatment of surface forms is unrealistic. This problem is typically addressed by either pre-processing words into subword units or performing translation directly at the level of characters. The former is based on word segmentation algorithms optimized using corpus-level statistics with no regard to the translation task. The latter learns directly from translation data but requires rather deep architectures. In this paper, we propose to translate words by modeling word formation through a hierarchical latent variable model which mimics the process of morphological inflection. Our model generates words one character at a time by composing two latent representations: a continuous one, aimed at capturing the lexical semantics, and a set of (approximately) discrete features, aimed at capturing the morphosyntactic function, which are shared among different surface forms. Our model achieves better accuracy in translation into three morphologically-rich languages than conventional open-vocabulary NMT methods, while also demonstrating a better generalization capacity under low to mid-resource settings.
On the Importance of Word Boundaries in Character-level Neural Machine Translation
Oct 21, 2019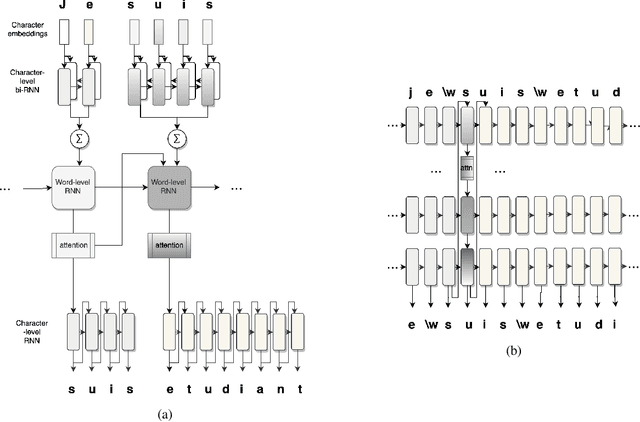
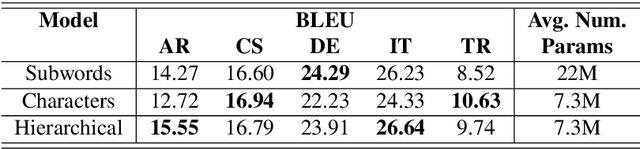
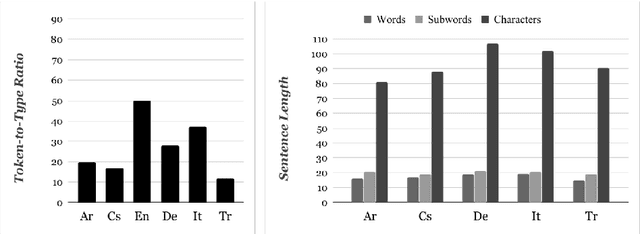
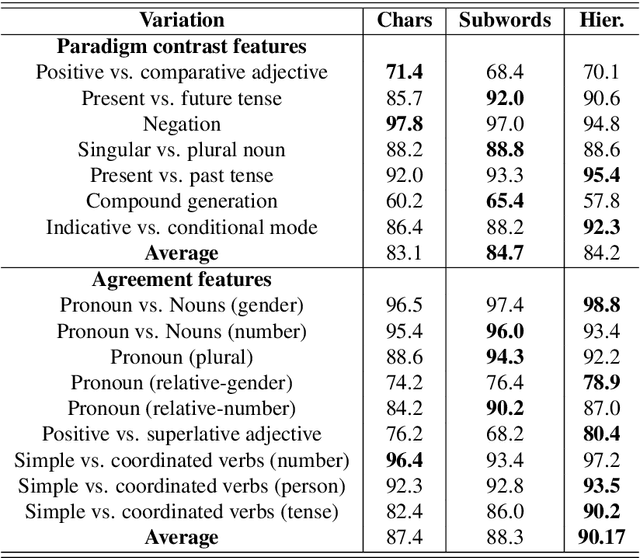
Neural Machine Translation (NMT) models generally perform translation using a fixed-size lexical vocabulary, which is an important bottleneck on their generalization capability and overall translation quality. The standard approach to overcome this limitation is to segment words into subword units, typically using some external tools with arbitrary heuristics, resulting in vocabulary units not optimized for the translation task. Recent studies have shown that the same approach can be extended to perform NMT directly at the level of characters, which can deliver translation accuracy on-par with subword-based models, on the other hand, this requires relatively deeper networks. In this paper, we propose a more computationally-efficient solution for character-level NMT which implements a hierarchical decoding architecture where translations are subsequently generated at the level of words and characters. We evaluate different methods for open-vocabulary NMT in the machine translation task from English into five languages with distinct morphological typology, and show that the hierarchical decoding model can reach higher translation accuracy than the subword-level NMT model using significantly fewer parameters, while demonstrating better capacity in learning longer-distance contextual and grammatical dependencies than the standard character-level NMT model.
Bianet: A Parallel News Corpus in Turkish, Kurdish and English
May 14, 2018

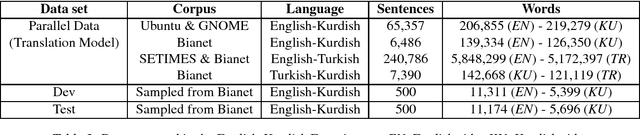
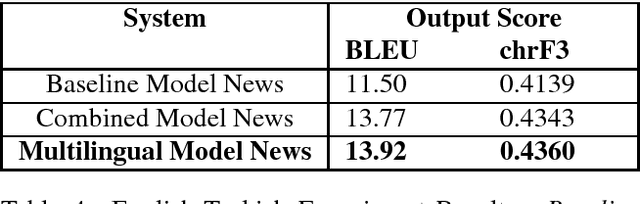
We present a new open-source parallel corpus consisting of news articles collected from the Bianet magazine, an online newspaper that publishes Turkish news, often along with their translations in English and Kurdish. In this paper, we describe the collection process of the corpus and its statistical properties. We validate the benefit of using the Bianet corpus by evaluating bilingual and multilingual neural machine translation models in English-Turkish and English-Kurdish directions.
Compositional Representation of Morphologically-Rich Input for Neural Machine Translation
May 05, 2018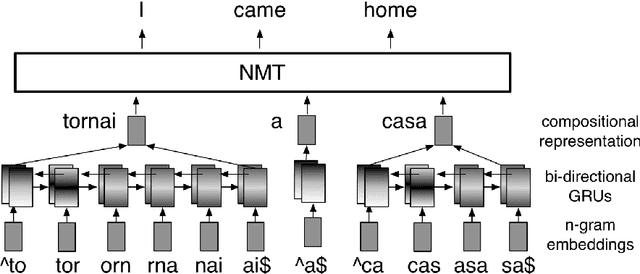
Neural machine translation (NMT) models are typically trained with fixed-size input and output vocabularies, which creates an important bottleneck on their accuracy and generalization capability. As a solution, various studies proposed segmenting words into sub-word units and performing translation at the sub-lexical level. However, statistical word segmentation methods have recently shown to be prone to morphological errors, which can lead to inaccurate translations. In this paper, we propose to overcome this problem by replacing the source-language embedding layer of NMT with a bi-directional recurrent neural network that generates compositional representations of the input at any desired level of granularity. We test our approach in a low-resource setting with five languages from different morphological typologies, and under different composition assumptions. By training NMT to compose word representations from character n-grams, our approach consistently outperforms (from 1.71 to 2.48 BLEU points) NMT learning embeddings of statistically generated sub-word units.
Linguistically Motivated Vocabulary Reduction for Neural Machine Translation from Turkish to English
Jul 31, 2017
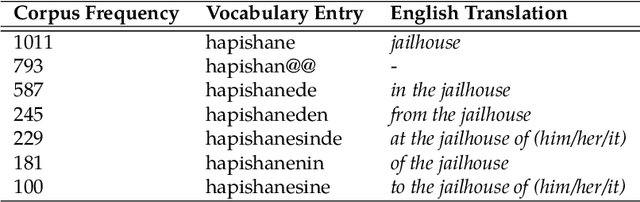


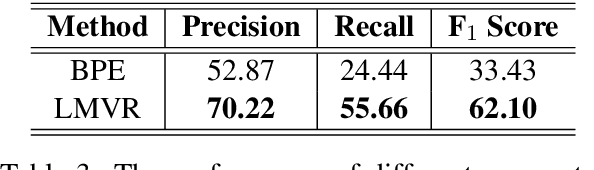
The necessity of using a fixed-size word vocabulary in order to control the model complexity in state-of-the-art neural machine translation (NMT) systems is an important bottleneck on performance, especially for morphologically rich languages. Conventional methods that aim to overcome this problem by using sub-word or character-level representations solely rely on statistics and disregard the linguistic properties of words, which leads to interruptions in the word structure and causes semantic and syntactic losses. In this paper, we propose a new vocabulary reduction method for NMT, which can reduce the vocabulary of a given input corpus at any rate while also considering the morphological properties of the language. Our method is based on unsupervised morphology learning and can be, in principle, used for pre-processing any language pair. We also present an alternative word segmentation method based on supervised morphological analysis, which aids us in measuring the accuracy of our model. We evaluate our method in Turkish-to-English NMT task where the input language is morphologically rich and agglutinative. We analyze different representation methods in terms of translation accuracy as well as the semantic and syntactic properties of the generated output. Our method obtains a significant improvement of 2.3 BLEU points over the conventional vocabulary reduction technique, showing that it can provide better accuracy in open vocabulary translation of morphologically rich languages.
* The 20th Annual Conference of the European Association for Machine Translation (EAMT), Research Paper, 12 pages