 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficiency Boost in Decentralized Optimization: Reimagining Neighborhood Aggregation with Minimal Overhead
Sep 26, 2025



In today's data-sensitive landscape, distributed learning emerges as a vital tool, not only fortifying privacy measures but also streamlining computational operations. This becomes especially crucial within fully decentralized infrastructures where local processing is imperative due to the absence of centralized aggregation. Here, we introduce DYNAWEIGHT, a novel framework to information aggregation in multi-agent networks. DYNAWEIGHT offers substantial acceleration in decentralized learning with minimal additional communication and memory overhead. Unlike traditional static weight assignments, such as Metropolis weights, DYNAWEIGHT dynamically allocates weights to neighboring servers based on their relative losses on local datasets. Consequently, it favors servers possessing diverse information, particularly in scenarios of substantial data heterogeneity. Our experiments on various datasets MNIST, CIFAR10, and CIFAR100 incorporating various server counts and graph topologies, demonstrate notable enhancements in training speeds. Notably, DYNAWEIGHT functions as an aggregation scheme compatible with any underlying server-level optimization algorithm, underscoring its versatility and potential for widespread integration.
RL in Name Only? Analyzing the Structural Assumptions in RL post-training for LLMs
May 19, 2025


Reinforcement learning-based post-training of large language models (LLMs) has recently gained attention, particularly following the release of DeepSeek R1, which applied GRPO for fine-tuning. Amid the growing hype around improved reasoning abilities attributed to RL post-training, we critically examine the formulation and assumptions underlying these methods. We start by highlighting the popular structural assumptions made in modeling LLM training as a Markov Decision Process (MDP), and show how they lead to a degenerate MDP that doesn't quite need the RL/GRPO apparatus. The two critical structural assumptions include (1) making the MDP states be just a concatenation of the actions-with states becoming the context window and the actions becoming the tokens in LLMs and (2) splitting the reward of a state-action trajectory uniformly across the trajectory. Through a comprehensive analysis, we demonstrate that these simplifying assumptions make the approach effectively equivalent to an outcome-driven supervised learning. Our experiments on benchmarks including GSM8K and Countdown using Qwen-2.5 base models show that iterative supervised fine-tuning, incorporating both positive and negative samples, achieves performance comparable to GRPO-based training. We will also argue that the structural assumptions indirectly incentivize the RL to generate longer sequences of intermediate tokens-which in turn feeds into the narrative of "RL generating longer thinking traces." While RL may well be a very useful technique for improving the reasoning abilities of LLMs, our analysis shows that the simplistic structural assumptions made in modeling the underlying MDP render the popular LLM RL frameworks and their interpretations questionable.
Using General Value Functions to Learn Domain-Backed Inventory Management Policies
Nov 03, 2023



We consider the inventory management problem, where the goal is to balance conflicting objectives such as availability and wastage of a large range of products in a store. We propose a reinforcement learning (RL) approach that utilises General Value Functions (GVFs) to derive domain-backed inventory replenishment policies. The inventory replenishment decisions are modelled as a sequential decision making problem, which is challenging due to uncertain demand and the existence of aggregate (cross-product) constraints. In existing literature, GVFs have primarily been used for auxiliary task learning. We use this capability to train GVFs on domain-critical characteristics such as prediction of stock-out probability and wastage quantity. Using this domain expertise for more effective exploration, we train an RL agent to compute the inventory replenishment quantities for a large range of products (up to 6000 in the reported experiments), which share aggregate constraints such as the total weight/volume per delivery. Additionally, we show that the GVF predictions can be used to provide additional domain-backed insights into the decisions proposed by the RL agent. Finally, since the environment dynamics are fully transferred, the trained GVFs can be used for faster adaptation to vastly different business objectives (for example, due to the start of a promotional period or due to deployment in a new customer environment).
Safe Sequential Optimization for Switching Environments
Nov 03, 2023We consider the problem of designing a sequential decision making agent to maximize an unknown time-varying function which switches with time. At each step, the agent receives an observation of the function's value at a point decided by the agent. The observation could be corrupted by noise. The agent is also constrained to take safe decisions with high probability, i.e., the chosen points should have a function value greater than a threshold. For this switching environment, we propose a policy called Adaptive-SafeOpt and evaluate its performance via simulations. The policy incorporates Bayesian optimization and change point detection for the safe sequential optimization problem. We observe that a major challenge in adapting to the switching change is to identify safe decisions when the change point is detected and prevent attraction to local optima.
Follow your Nose: Using General Value Functions for Directed Exploration in Reinforcement Learning
Mar 02, 2022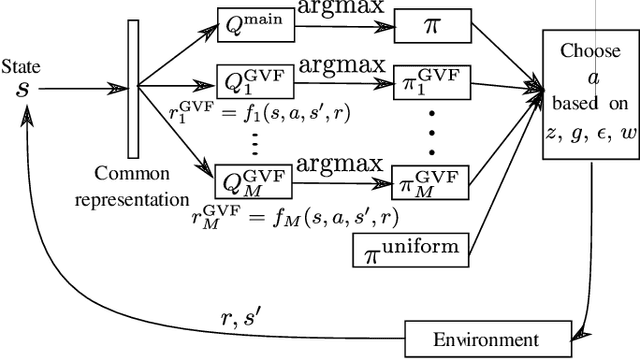
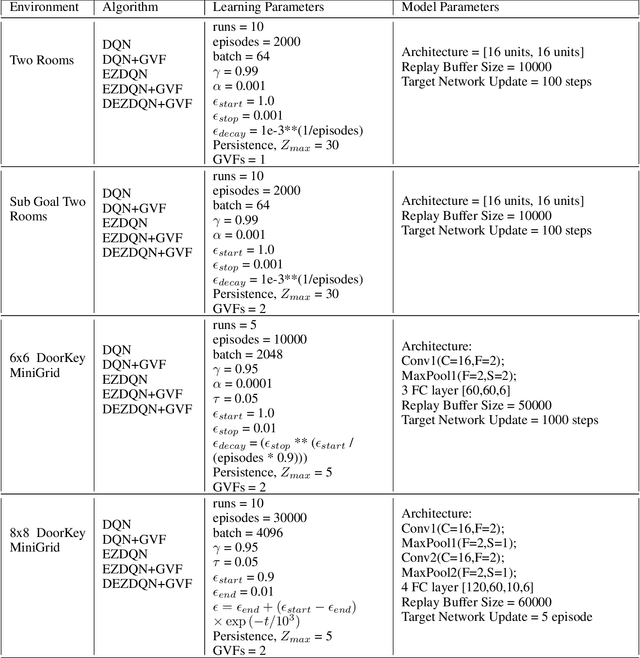
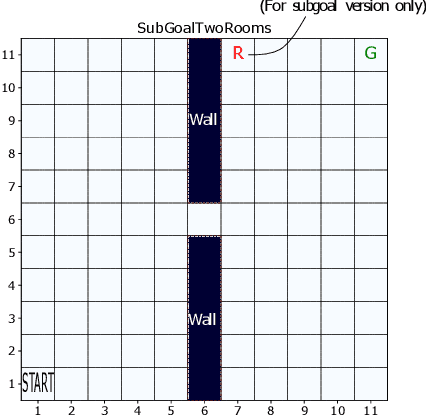
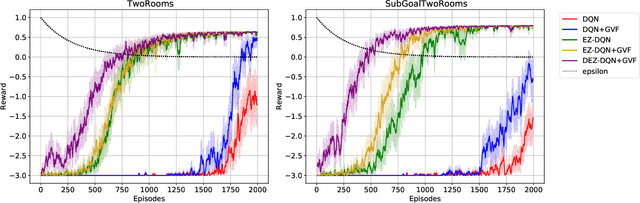
Exploration versus exploitation dilemma is a significant problem in reinforcement learning (RL), particularly in complex environments with large state space and sparse rewards. When optimizing for a particular goal, running simple smaller tasks can often be a good way to learn additional information about the environment. Exploration methods have been used to sample better trajectories from the environment for improved performance while auxiliary tasks have been incorporated generally where the reward is sparse. If there is little reward signal available, the agent requires clever exploration strategies to reach parts of the state space that contain relevant sub-goals. However, that exploration needs to be balanced with the need for exploiting the learned policy. This paper explores the idea of combining exploration with auxiliary task learning using General Value Functions (GVFs) and a directed exploration strategy. We provide a simple way to learn options (sequences of actions) instead of having to handcraft them, and demonstrate the performance advantage in three navigation tasks.