 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVariational Autoencoder with Embedded Student-$t$ Mixture Model for Authorship Attribution
May 28, 2020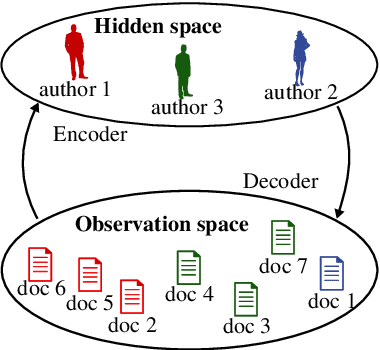
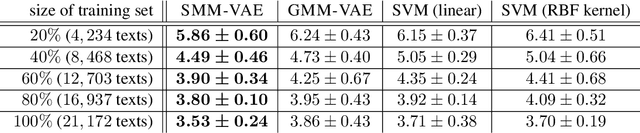
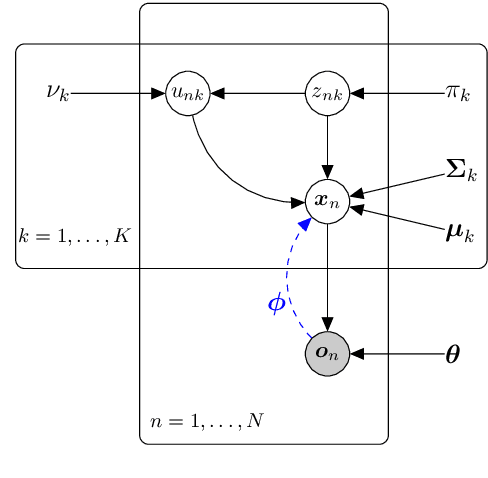
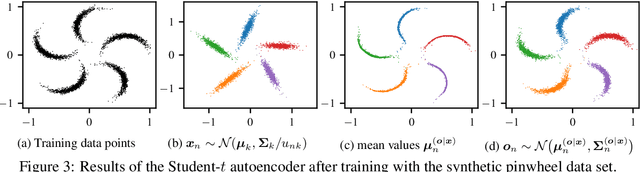
Traditional computational authorship attribution describes a classification task in a closed-set scenario. Given a finite set of candidate authors and corresponding labeled texts, the objective is to determine which of the authors has written another set of anonymous or disputed texts. In this work, we propose a probabilistic autoencoding framework to deal with this supervised classification task. More precisely, we are extending a variational autoencoder (VAE) with embedded Gaussian mixture model to a Student-$t$ mixture model. Autoencoders have had tremendous success in learning latent representations. However, existing VAEs are currently still bound by limitations imposed by the assumed Gaussianity of the underlying probability distributions in the latent space. In this work, we are extending the Gaussian model for the VAE to a Student-$t$ model, which allows for an independent control of the "heaviness" of the respective tails of the implied probability densities. Experiments over an Amazon review dataset indicate superior performance of the proposed method.
Detecting Adversarial Examples for Speech Recognition via Uncertainty Quantification
May 24, 2020
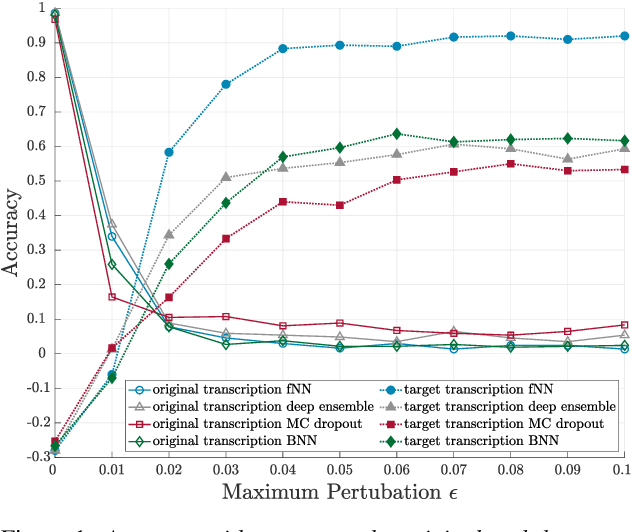
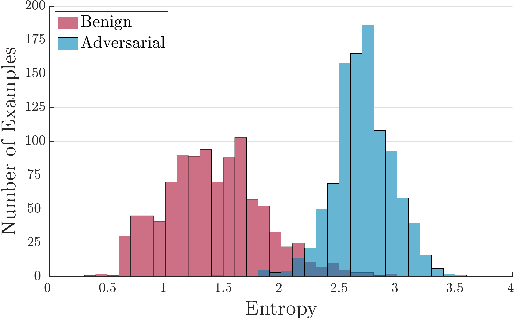
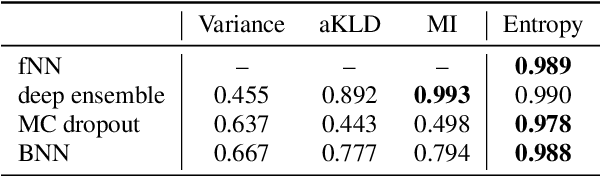
Machine learning systems and also, specifically, automatic speech recognition (ASR) systems are vulnerable against adversarial attacks, where an attacker maliciously changes the input. In the case of ASR systems, the most interesting cases are targeted attacks, in which an attacker aims to force the system into recognizing given target transcriptions in an arbitrary audio sample. The increasing number of sophisticated, quasi imperceptible attacks raises the question of countermeasures. In this paper, we focus on hybrid ASR systems and compare four acoustic models regarding their ability to indicate uncertainty under attack: a feed-forward neural network and three neural networks specifically designed for uncertainty quantification, namely a Bayesian neural network, Monte Carlo dropout, and a deep ensemble. We employ uncertainty measures of the acoustic model to construct a simple one-class classification model for assessing whether inputs are benign or adversarial. Based on this approach, we are able to detect adversarial examples with an area under the receiving operator curve score of more than 0.99. The neural networks for uncertainty quantification simultaneously diminish the vulnerability to the attack, which is reflected in a lower recognition accuracy of the malicious target text in comparison to a standard hybrid ASR system.
Leveraging Frequency Analysis for Deep Fake Image Recognition
Mar 20, 2020
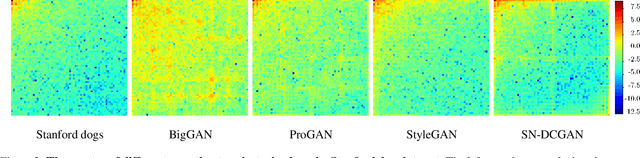
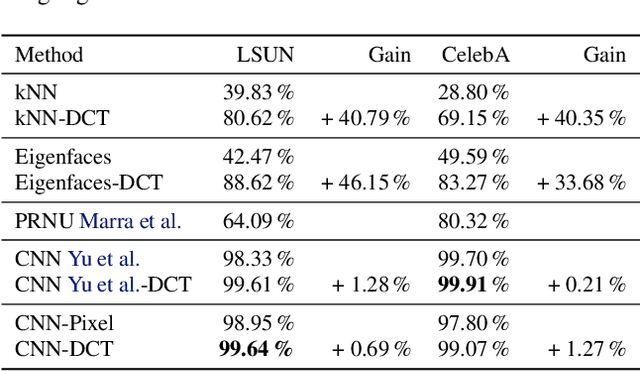
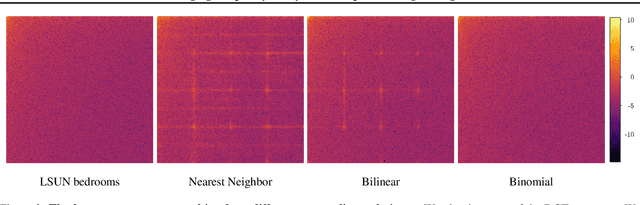
Deep neural networks can generate images that are astonishingly realistic, so much so that it is often hard for humans to distinguish them from actual photos. These achievements have been largely made possible by Generative Adversarial Networks (GANs). While these deep fake images have been thoroughly investigated in the image domain-a classical approach from the area of image forensics-an analysis in the frequency domain has been missing so far. In this paper, we address this shortcoming and our results reveal that in frequency space, GAN-generated images exhibit severe artifacts that can be easily identified. We perform a comprehensive analysis, showing that these artifacts are consistent across different neural network architectures, data sets, and resolutions. In a further investigation, we demonstrate that these artifacts are caused by upsampling operations found in all current GAN architectures, indicating a structural and fundamental problem in the way images are generated via GANs. Based on this analysis, we demonstrate how the frequency representation can be used to identify deep fake images in an automated way, surpassing state-of-the-art methods.
On Neural Phone Recognition of Mixed-Source ECoG Signals
Dec 12, 2019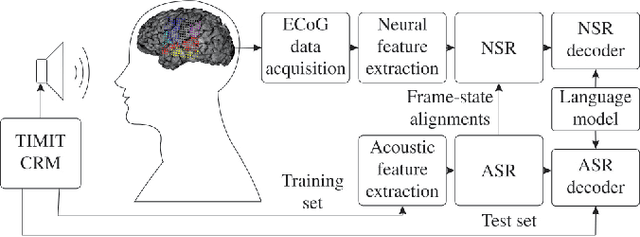

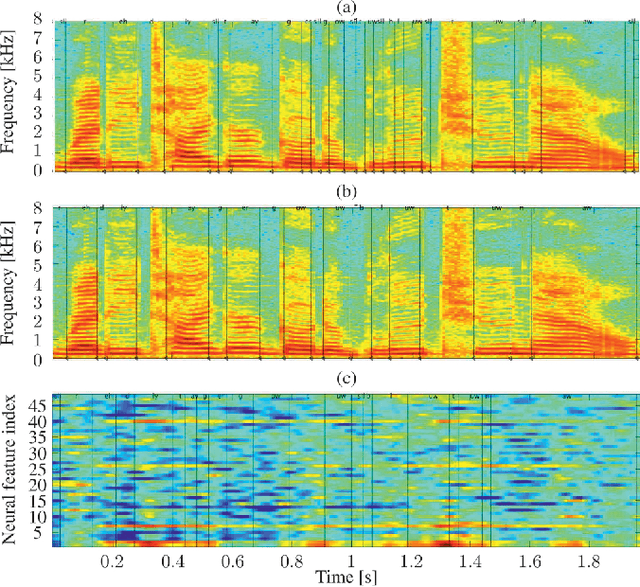
The emerging field of neural speech recognition (NSR) using electrocorticography has recently attracted remarkable research interest for studying how human brains recognize speech in quiet and noisy surroundings. In this study, we demonstrate the utility of NSR systems to objectively prove the ability of human beings to attend to a single speech source while suppressing the interfering signals in a simulated cocktail party scenario. The experimental results show that the relative degradation of the NSR system performance when tested in a mixed-source scenario is significantly lower than that of automatic speech recognition (ASR). In this paper, we have significantly enhanced the performance of our recently published framework by using manual alignments for initialization instead of the flat start technique. We have also improved the NSR system performance by accounting for the possible transcription mismatch between the acoustic and neural signals.
Explainable Authorship Verification in Social Media via Attention-based Similarity Learning
Nov 19, 2019
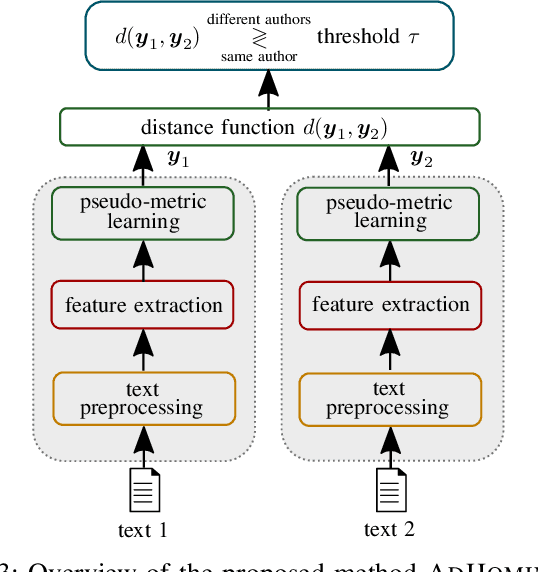
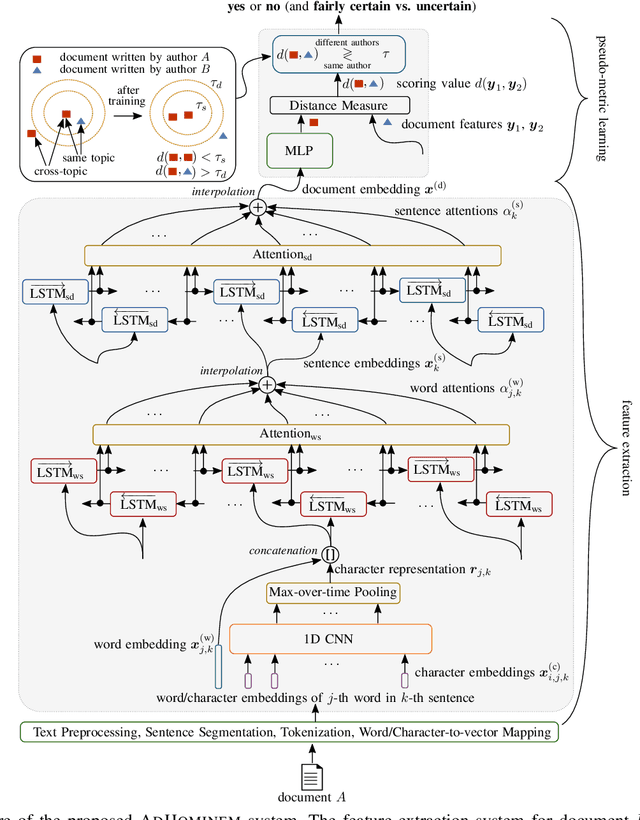
Authorship verification is the task of analyzing the linguistic patterns of two or more texts to determine whether they were written by the same author or not. The analysis is traditionally performed by experts who consider linguistic features, which include spelling mistakes, grammatical inconsistencies, and stylistics for example. Machine learning algorithms, on the other hand, can be trained to accomplish the same, but have traditionally relied on so-called stylometric features. The disadvantage of such features is that their reliability is greatly diminished for short and topically varied social media texts. In this interdisciplinary work, we propose a substantial extension of a recently published hierarchical Siamese neural network approach, with which it is feasible to learn neural features and to visualize the decision-making process. For this purpose, a new large-scale corpus of short Amazon reviews for text comparison research is compiled and we show that the Siamese network topologies outperform state-of-the-art approaches that were built up on stylometric features. Our linguistic analysis of the internal attention weights of the network shows that the proposed method is indeed able to latch on to some traditional linguistic categories.
Imperio: Robust Over-the-Air Adversarial Examples for Automatic Speech Recognition Systems
Sep 09, 2019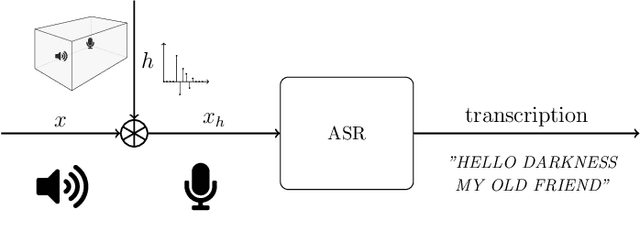
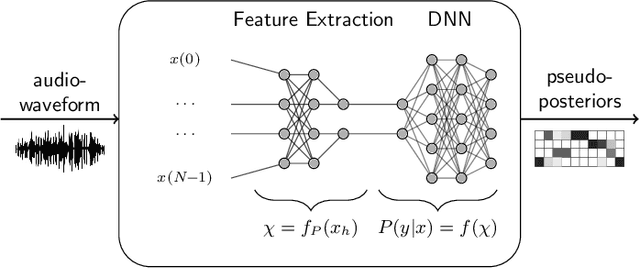
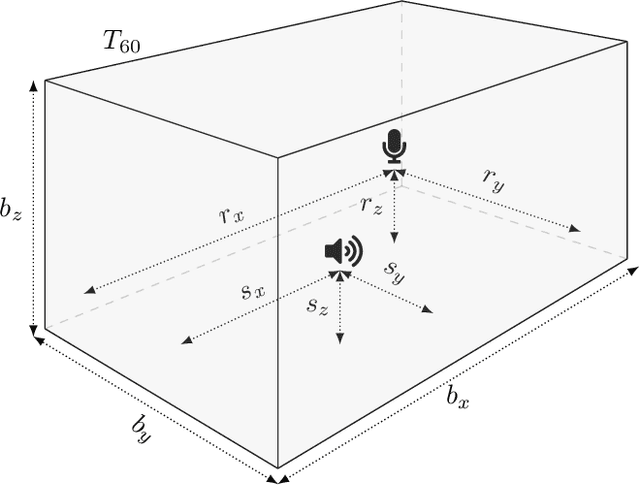
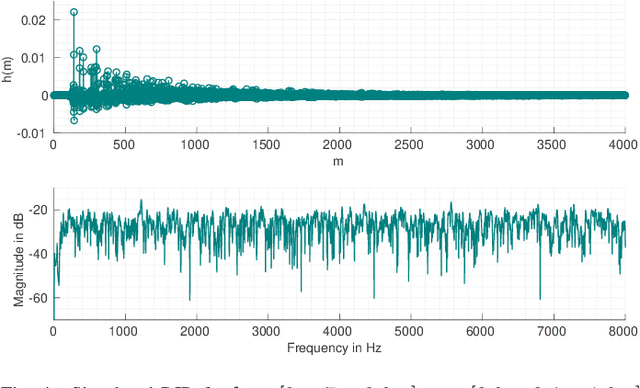
Automatic speech recognition (ASR) systems are possible to fool via targeted adversarial examples. These can induce the ASR to produce arbitrary transcriptions in response to any type of audio signal, be it speech, environmental sounds, or music. However, in general, those adversarial examples did not work in a real-world setup, where the examples are played over the air but have to be fed into the ASR system directly. In some cases, where the adversarial examples could be successfully played over the air, the attacks require precise information about the room where the attack takes place in order to tailor the adversarial examples to a specific setup and are not transferable to other rooms. Other attacks, which are robust in an over-the-air attack, are either handcrafted examples or human listeners can easily recognize the target transcription, once they have been alerted to its content. In this paper, we demonstrate the first generic algorithm that produces adversarial examples which remain robust in an over-the-air attack such that the ASR system transcribes the target transcription after actually being replayed. For the proposed algorithm, guessing a rough approximation of the room characteristics is enough and no actual access to the room is required. We use the ASR system Kaldi to demonstrate the attack and employ a room-impulse-response simulator to harden the adversarial examples against varying room characteristics. Further, the algorithm can also utilize psychoacoustics to hide changes of the original audio signal below the human thresholds of hearing. We show that the adversarial examples work for varying room setups, but also can be tailored to specific room setups. As a result, an attacker can optimize adversarial examples for any target transcription and to arbitrary rooms. Additionally, the adversarial examples remain transferable to varying rooms with a high probability.
Similarity Learning for Authorship Verification in Social Media
Aug 20, 2019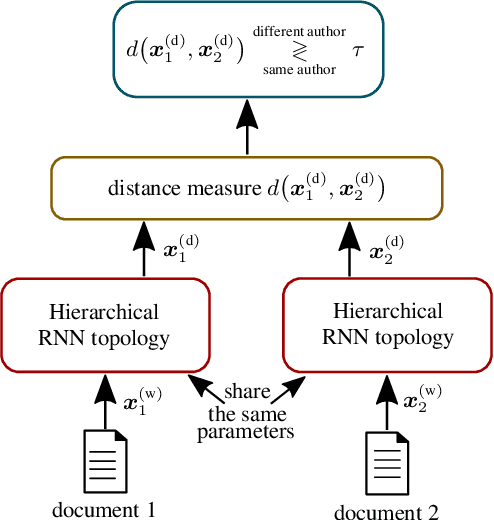
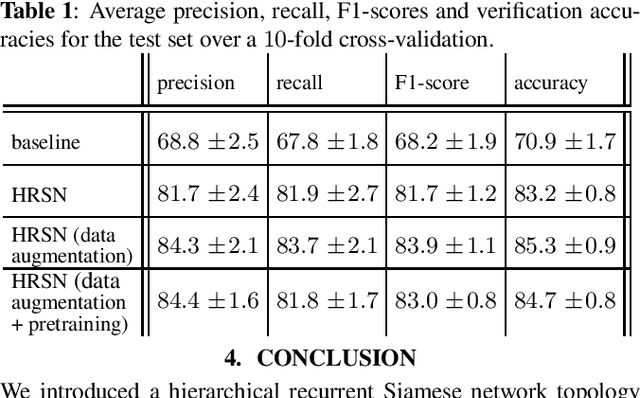
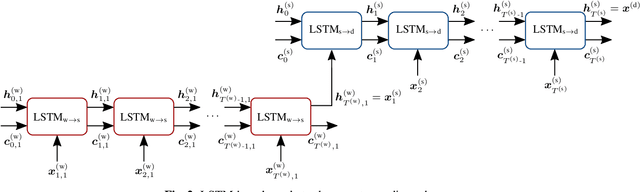
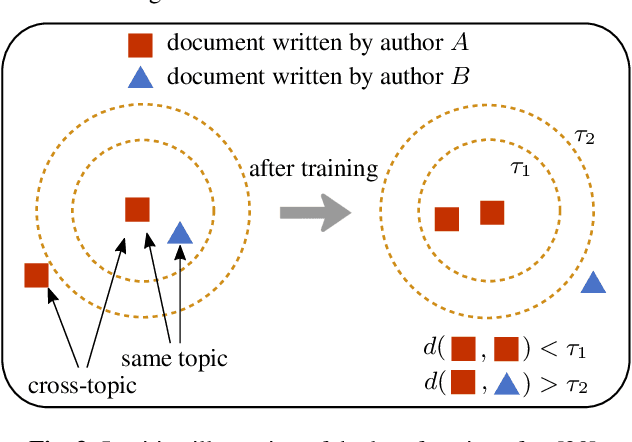
Authorship verification tries to answer the question if two documents with unknown authors were written by the same author or not. A range of successful technical approaches has been proposed for this task, many of which are based on traditional linguistic features such as n-grams. These algorithms achieve good results for certain types of written documents like books and novels. Forensic authorship verification for social media, however, is a much more challenging task since messages tend to be relatively short, with a large variety of different genres and topics. At this point, traditional methods based on features like n-grams have had limited success. In this work, we propose a new neural network topology for similarity learning that significantly improves the performance on the author verification task with such challenging data sets.
Audiovisual Speaker Tracking using Nonlinear Dynamical Systems with Dynamic Stream Weights
Mar 14, 2019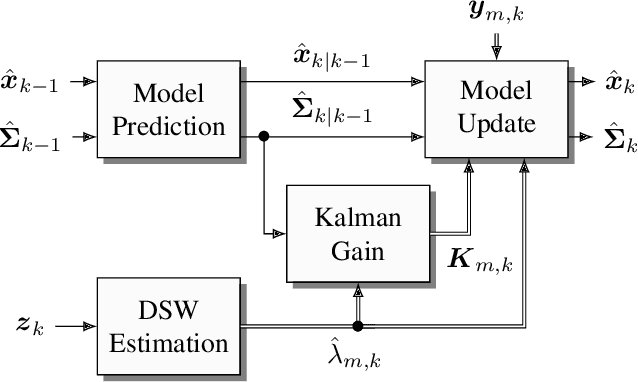
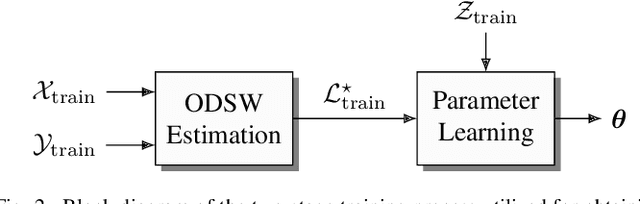

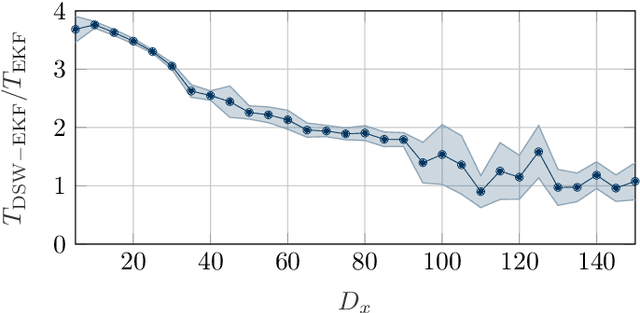
Data fusion plays an important role in many technical applications that require efficient processing of multimodal sensory observations. A prominent example is audiovisual signal processing, which has gained increasing attention in automatic speech recognition, speaker localization and related tasks. If appropriately combined with acoustic information, additional visual cues can help to improve the performance in these applications, especially under adverse acoustic conditions. A dynamic weighting of acoustic and visual streams based on instantaneous sensor reliability measures is an efficient approach to data fusion in this context. This paper presents a framework that extends the well-established theory of nonlinear dynamical systems with the notion of dynamic stream weights for an arbitrary number of sensory observations. It comprises a recursive state estimator based on the Gaussian filtering paradigm, which incorporates dynamic stream weights into a framework closely related to the extended Kalman filter. Additionally, a convex optimization approach to estimate oracle dynamic stream weights in fully observed dynamical systems utilizing a Dirichlet prior is presented. This serves as a basis for a generic parameter learning framework of dynamic stream weight estimators. The proposed system is application-independent and can be easily adapted to specific tasks and requirements. A study using audiovisual speaker tracking tasks is considered as an exemplary application in this work. An improved tracking performance of the dynamic stream weight-based estimation framework over state-of-the-art methods is demonstrated in the experiments.