 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePHUMA: Physically-Grounded Humanoid Locomotion Dataset
Oct 30, 2025



Motion imitation is a promising approach for humanoid locomotion, enabling agents to acquire humanlike behaviors. Existing methods typically rely on high-quality motion capture datasets such as AMASS, but these are scarce and expensive, limiting scalability and diversity. Recent studies attempt to scale data collection by converting large-scale internet videos, exemplified by Humanoid-X. However, they often introduce physical artifacts such as floating, penetration, and foot skating, which hinder stable imitation. In response, we introduce PHUMA, a Physically-grounded HUMAnoid locomotion dataset that leverages human video at scale, while addressing physical artifacts through careful data curation and physics-constrained retargeting. PHUMA enforces joint limits, ensures ground contact, and eliminates foot skating, producing motions that are both large-scale and physically reliable. We evaluated PHUMA in two sets of conditions: (i) imitation of unseen motion from self-recorded test videos and (ii) path following with pelvis-only guidance. In both cases, PHUMA-trained policies outperform Humanoid-X and AMASS, achieving significant gains in imitating diverse motions. The code is available at https://davian-robotics.github.io/PHUMA.
SimBa: Simplicity Bias for Scaling Up Parameters in Deep Reinforcement Learning
Oct 13, 2024



Recent advances in CV and NLP have been largely driven by scaling up the number of network parameters, despite traditional theories suggesting that larger networks are prone to overfitting. These large networks avoid overfitting by integrating components that induce a simplicity bias, guiding models toward simple and generalizable solutions. However, in deep RL, designing and scaling up networks have been less explored. Motivated by this opportunity, we present SimBa, an architecture designed to scale up parameters in deep RL by injecting a simplicity bias. SimBa consists of three components: (i) an observation normalization layer that standardizes inputs with running statistics, (ii) a residual feedforward block to provide a linear pathway from the input to output, and (iii) a layer normalization to control feature magnitudes. By scaling up parameters with SimBa, the sample efficiency of various deep RL algorithms-including off-policy, on-policy, and unsupervised methods-is consistently improved. Moreover, solely by integrating SimBa architecture into SAC, it matches or surpasses state-of-the-art deep RL methods with high computational efficiency across DMC, MyoSuite, and HumanoidBench. These results demonstrate SimBa's broad applicability and effectiveness across diverse RL algorithms and environments.
Adapting Pretrained ViTs with Convolution Injector for Visuo-Motor Control
Jun 10, 2024



Vision Transformers (ViT), when paired with large-scale pretraining, have shown remarkable performance across various computer vision tasks, primarily due to their weak inductive bias. However, while such weak inductive bias aids in pretraining scalability, this may hinder the effective adaptation of ViTs for visuo-motor control tasks as a result of the absence of control-centric inductive biases. Such absent inductive biases include spatial locality and translation equivariance bias which convolutions naturally offer. To this end, we introduce Convolution Injector (CoIn), an add-on module that injects convolutions which are rich in locality and equivariance biases into a pretrained ViT for effective adaptation in visuo-motor control. We evaluate CoIn with three distinct types of pretrained ViTs (CLIP, MVP, VC-1) across 12 varied control tasks within three separate domains (Adroit, MetaWorld, DMC), and demonstrate that CoIn consistently enhances control task performance across all experimented environments and models, validating the effectiveness of providing pretrained ViTs with control-centric biases.
Investigating Pre-Training Objectives for Generalization in Vision-Based Reinforcement Learning
Jun 10, 2024



Recently, various pre-training methods have been introduced in vision-based Reinforcement Learning (RL). However, their generalization ability remains unclear due to evaluations being limited to in-distribution environments and non-unified experimental setups. To address this, we introduce the Atari Pre-training Benchmark (Atari-PB), which pre-trains a ResNet-50 model on 10 million transitions from 50 Atari games and evaluates it across diverse environment distributions. Our experiments show that pre-training objectives focused on learning task-agnostic features (e.g., identifying objects and understanding temporal dynamics) enhance generalization across different environments. In contrast, objectives focused on learning task-specific knowledge (e.g., identifying agents and fitting reward functions) improve performance in environments similar to the pre-training dataset but not in varied ones. We publicize our codes, datasets, and model checkpoints at https://github.com/dojeon-ai/Atari-PB.
Do's and Don'ts: Learning Desirable Skills with Instruction Videos
Jun 01, 2024



Unsupervised skill discovery is a learning paradigm that aims to acquire diverse behaviors without explicit rewards. However, it faces challenges in learning complex behaviors and often leads to learning unsafe or undesirable behaviors. For instance, in various continuous control tasks, current unsupervised skill discovery methods succeed in learning basic locomotions like standing but struggle with learning more complex movements such as walking and running. Moreover, they may acquire unsafe behaviors like tripping and rolling or navigate to undesirable locations such as pitfalls or hazardous areas. In response, we present DoDont (Do's and Don'ts), an instruction-based skill discovery algorithm composed of two stages. First, in an instruction learning stage, DoDont leverages action-free instruction videos to train an instruction network to distinguish desirable transitions from undesirable ones. Then, in the skill learning stage, the instruction network adjusts the reward function of the skill discovery algorithm to weight the desired behaviors. Specifically, we integrate the instruction network into a distance-maximizing skill discovery algorithm, where the instruction network serves as the distance function. Empirically, with less than 8 instruction videos, DoDont effectively learns desirable behaviors and avoids undesirable ones across complex continuous control tasks. Code and videos are available at https://mynsng.github.io/dodont/
SARDINE: A Simulator for Automated Recommendation in Dynamic and Interactive Environments
Nov 28, 2023Simulators can provide valuable insights for researchers and practitioners who wish to improve recommender systems, because they allow one to easily tweak the experimental setup in which recommender systems operate, and as a result lower the cost of identifying general trends and uncovering novel findings about the candidate methods. A key requirement to enable this accelerated improvement cycle is that the simulator is able to span the various sources of complexity that can be found in the real recommendation environment that it simulates. With the emergence of interactive and data-driven methods - e.g., reinforcement learning or online and counterfactual learning-to-rank - that aim to achieve user-related goals beyond the traditional accuracy-centric objectives, adequate simulators are needed. In particular, such simulators must model the various mechanisms that render the recommendation environment dynamic and interactive, e.g., the effect of recommendations on the user or the effect of biased data on subsequent iterations of the recommender system. We therefore propose SARDINE, a flexible and interpretable recommendation simulator that can help accelerate research in interactive and data-driven recommender systems. We demonstrate its usefulness by studying existing methods within nine diverse environments derived from SARDINE, and even uncover novel insights about them.
Learning to Discover Skills through Guidance
Nov 01, 2023In the field of unsupervised skill discovery (USD), a major challenge is limited exploration, primarily due to substantial penalties when skills deviate from their initial trajectories. To enhance exploration, recent methodologies employ auxiliary rewards to maximize the epistemic uncertainty or entropy of states. However, we have identified that the effectiveness of these rewards declines as the environmental complexity rises. Therefore, we present a novel USD algorithm, skill discovery with guidance (DISCO-DANCE), which (1) selects the guide skill that possesses the highest potential to reach unexplored states, (2) guides other skills to follow guide skill, then (3) the guided skills are dispersed to maximize their discriminability in unexplored states. Empirical evaluation demonstrates that DISCO-DANCE outperforms other USD baselines in challenging environments, including two navigation benchmarks and a continuous control benchmark. Qualitative visualizations and code of DISCO-DANCE are available at https://mynsng.github.io/discodance.
Towards Validating Long-Term User Feedbacks in Interactive Recommendation Systems
Aug 22, 2023



Interactive Recommender Systems (IRSs) have attracted a lot of attention, due to their ability to model interactive processes between users and recommender systems. Numerous approaches have adopted Reinforcement Learning (RL) algorithms, as these can directly maximize users' cumulative rewards. In IRS, researchers commonly utilize publicly available review datasets to compare and evaluate algorithms. However, user feedback provided in public datasets merely includes instant responses (e.g., a rating), with no inclusion of delayed responses (e.g., the dwell time and the lifetime value). Thus, the question remains whether these review datasets are an appropriate choice to evaluate the long-term effects of the IRS. In this work, we revisited experiments on IRS with review datasets and compared RL-based models with a simple reward model that greedily recommends the item with the highest one-step reward. Following extensive analysis, we can reveal three main findings: First, a simple greedy reward model consistently outperforms RL-based models in maximizing cumulative rewards. Second, applying higher weighting to long-term rewards leads to a degradation of recommendation performance. Third, user feedbacks have mere long-term effects on the benchmark datasets. Based on our findings, we conclude that a dataset has to be carefully verified and that a simple greedy baseline should be included for a proper evaluation of RL-based IRS approaches.
On the Importance of Feature Decorrelation for Unsupervised Representation Learning in Reinforcement Learning
Jun 09, 2023



Recently, unsupervised representation learning (URL) has improved the sample efficiency of Reinforcement Learning (RL) by pretraining a model from a large unlabeled dataset. The underlying principle of these methods is to learn temporally predictive representations by predicting future states in the latent space. However, an important challenge of this approach is the representational collapse, where the subspace of the latent representations collapses into a low-dimensional manifold. To address this issue, we propose a novel URL framework that causally predicts future states while increasing the dimension of the latent manifold by decorrelating the features in the latent space. Through extensive empirical studies, we demonstrate that our framework effectively learns predictive representations without collapse, which significantly improves the sample efficiency of state-of-the-art URL methods on the Atari 100k benchmark. The code is available at https://github.com/dojeon-ai/SimTPR.
DraftRec: Personalized Draft Recommendation for Winning in Multi-Player Online Battle Arena Games
Apr 27, 2022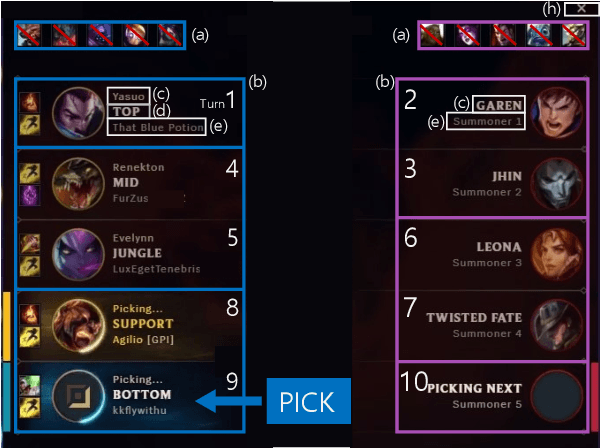

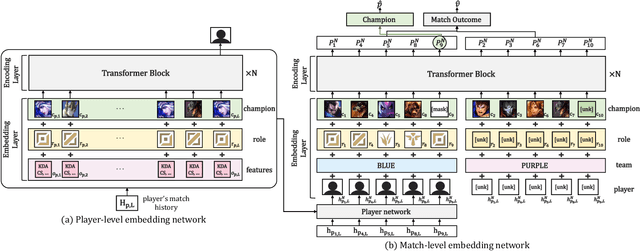
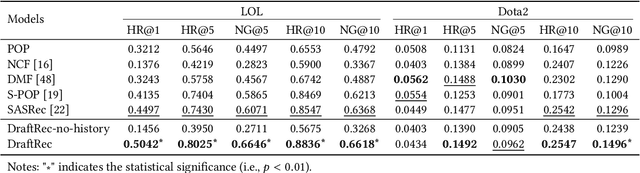
This paper presents a personalized character recommendation system for Multiplayer Online Battle Arena (MOBA) games which are considered as one of the most popular online video game genres around the world. When playing MOBA games, players go through a draft stage, where they alternately select a virtual character to play. When drafting, players select characters by not only considering their character preferences, but also the synergy and competence of their team's character combination. However, the complexity of drafting induces difficulties for beginners to choose the appropriate characters based on the characters of their team while considering their own champion preferences. To alleviate this problem, we propose DraftRec, a novel hierarchical model which recommends characters by considering each player's champion preferences and the interaction between the players. DraftRec consists of two networks: the player network and the match network. The player network captures the individual player's champion preference, and the match network integrates the complex relationship between the players and their respective champions. We train and evaluate our model from a manually collected 280,000 matches of League of Legends and a publicly available 50,000 matches of Dota2. Empirically, our method achieved state-of-the-art performance in character recommendation and match outcome prediction task. Furthermore, a comprehensive user survey confirms that DraftRec provides convincing and satisfying recommendations. Our code and dataset are available at https://github.com/dojeon-ai/DraftRec.