 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralization of Graph Neural Networks through the Lens of Homomorphism
Mar 10, 2024



Despite the celebrated popularity of Graph Neural Networks (GNNs) across numerous applications, the ability of GNNs to generalize remains less explored. In this work, we propose to study the generalization of GNNs through a novel perspective - analyzing the entropy of graph homomorphism. By linking graph homomorphism with information-theoretic measures, we derive generalization bounds for both graph and node classifications. These bounds are capable of capturing subtleties inherent in various graph structures, including but not limited to paths, cycles and cliques. This enables a data-dependent generalization analysis with robust theoretical guarantees. To shed light on the generality of of our proposed bounds, we present a unifying framework that can characterize a broad spectrum of GNN models through the lens of graph homomorphism. We validate the practical applicability of our theoretical findings by showing the alignment between the proposed bounds and the empirically observed generalization gaps over both real-world and synthetic datasets.
Problem-Solving Guide: Predicting the Algorithm Tags and Difficulty for Competitive Programming Problems
Oct 09, 2023



The recent program development industries have required problem-solving abilities for engineers, especially application developers. However, AI-based education systems to help solve computer algorithm problems have not yet attracted attention, while most big tech companies require the ability to solve algorithm problems including Google, Meta, and Amazon. The most useful guide to solving algorithm problems might be guessing the category (tag) of the facing problems. Therefore, our study addresses the task of predicting the algorithm tag as a useful tool for engineers and developers. Moreover, we also consider predicting the difficulty levels of algorithm problems, which can be used as useful guidance to calculate the required time to solve that problem. In this paper, we present a real-world algorithm problem multi-task dataset, AMT, by mainly collecting problem samples from the most famous and large competitive programming website Codeforces. To the best of our knowledge, our proposed dataset is the most large-scale dataset for predicting algorithm tags compared to previous studies. Moreover, our work is the first to address predicting the difficulty levels of algorithm problems. We present a deep learning-based novel method for simultaneously predicting algorithm tags and the difficulty levels of an algorithm problem given. All datasets and source codes are available at https://github.com/sronger/PSG_Predicting_Algorithm_Tags_and_Difficulty.
Test Time Embedding Normalization for Popularity Bias Mitigation
Sep 01, 2023



Popularity bias is a widespread problem in the field of recommender systems, where popular items tend to dominate recommendation results. In this work, we propose 'Test Time Embedding Normalization' as a simple yet effective strategy for mitigating popularity bias, which surpasses the performance of the previous mitigation approaches by a significant margin. Our approach utilizes the normalized item embedding during the inference stage to control the influence of embedding magnitude, which is highly correlated with item popularity. Through extensive experiments, we show that our method combined with the sampled softmax loss effectively reduces popularity bias compare to previous approaches for bias mitigation. We further investigate the relationship between user and item embeddings and find that the angular similarity between embeddings distinguishes preferable and non-preferable items regardless of their popularity. The analysis explains the mechanism behind the success of our approach in eliminating the impact of popularity bias. Our code is available at https://github.com/ml-postech/TTEN.
EPIC: Graph Augmentation with Edit Path Interpolation via Learnable Cost
Jun 02, 2023



Graph-based models have become increasingly important in various domains, but the limited size and diversity of existing graph datasets often limit their performance. To address this issue, we propose EPIC (Edit Path Interpolation via learnable Cost), a novel interpolation-based method for augmenting graph datasets. Our approach leverages graph edit distance to generate new graphs that are similar to the original ones but exhibit some variation in their structures. To achieve this, we learn the graph edit distance through a comparison of labeled graphs and utilize this knowledge to create graph edit paths between pairs of original graphs. With randomly sampled graphs from a graph edit path, we enrich the training set to enhance the generalization capability of classification models. We demonstrate the effectiveness of our approach on several benchmark datasets and show that it outperforms existing augmentation methods in graph classification tasks.
Hierarchical Graph Generation with $K^2$-trees
Jun 01, 2023



Generating graphs from a target distribution is a significant challenge across many domains, including drug discovery and social network analysis. In this work, we introduce a novel graph generation method leveraging $K^2$-tree representation which was originally designed for lossless graph compression. Our motivation stems from the ability of the $K^2$-trees to enable compact generation while concurrently capturing the inherent hierarchical structure of a graph. In addition, we make further contributions by (1) presenting a sequential $K^2$-tree representation that incorporates pruning, flattening, and tokenization processes and (2) introducing a Transformer-based architecture designed to generate the sequence by incorporating a specialized tree positional encoding scheme. Finally, we extensively evaluate our algorithm on four general and two molecular graph datasets to confirm its superiority for graph generation.
Robust Evaluation of Diffusion-Based Adversarial Purification
Mar 16, 2023We question the current evaluation practice on diffusion-based purification methods. Diffusion-based purification methods aim to remove adversarial effects from an input data point at test time. The approach gains increasing attention as an alternative to adversarial training due to the disentangling between training and testing. Well-known white-box attacks are often employed to measure the robustness of the purification. However, it is unknown whether these attacks are the most effective for the diffusion-based purification since the attacks are often tailored for adversarial training. We analyze the current practices and provide a new guideline for measuring the robustness of purification methods against adversarial attacks. Based on our analysis, we further propose a new purification strategy showing competitive results against the state-of-the-art adversarial training approaches.
Feature Unlearning for Generative Models via Implicit Feedback
Mar 10, 2023



We tackle the problem of feature unlearning from a pretrained image generative model. Unlike a common unlearning task where an unlearning target is a subset of the training set, we aim to unlearn a specific feature, such as hairstyle from facial images, from the pretrained generative models. As the target feature is only presented in a local region of an image, unlearning the entire image from the pretrained model may result in losing other details in the remaining region of the image. To specify which features to unlearn, we develop an implicit feedback mechanism where a user can select images containing the target feature. From the implicit feedback, we identify a latent representation corresponding to the target feature and then use the representation to unlearn the generative model. Our framework is generalizable for the two well-known families of generative models: GANs and VAEs. Through experiments on MNIST and CelebA datasets, we show that target features are successfully removed while keeping the fidelity of the original models.
SpReME: Sparse Regression for Multi-Environment Dynamic Systems
Feb 12, 2023



Learning dynamical systems is a promising avenue for scientific discoveries. However, capturing the governing dynamics in multiple environments still remains a challenge: model-based approaches rely on the fidelity of assumptions made for a single environment, whereas data-driven approaches based on neural networks are often fragile on extrapolating into the future. In this work, we develop a method of sparse regression dubbed SpReME to discover the major dynamics that underlie multiple environments. Specifically, SpReME shares a sparse structure of ordinary differential equation (ODE) across different environments in common while allowing each environment to keep the coefficients of ODE terms independently. We demonstrate that the proposed model captures the correct dynamics from multiple environments over four different dynamic systems with improved prediction performance.
Item-based Variational Auto-encoder for Fair Music Recommendation
Oct 24, 2022We present our solution for the EvalRS DataChallenge. The EvalRS DataChallenge aims to build a more realistic recommender system considering accuracy, fairness, and diversity in evaluation. Our proposed system is based on an ensemble between an item-based variational auto-encoder (VAE) and a Bayesian personalized ranking matrix factorization (BPRMF). To mitigate the bias in popularity, we use an item-based VAE for each popularity group with an additional fairness regularization. To make a reasonable recommendation even the predictions are inaccurate, we combine the recommended list of BPRMF and that of item-based VAE. Through the experiments, we demonstrate that the item-based VAE with fairness regularization significantly reduces popularity bias compared to the user-based VAE. The ensemble between the item-based VAE and BPRMF makes the top-1 item similar to the ground truth even the predictions are inaccurate. Finally, we propose a `Coefficient Variance based Fairness' as a novel evaluation metric based on our reflections from the extensive experiments.
Substructure-Atom Cross Attention for Molecular Representation Learning
Oct 15, 2022
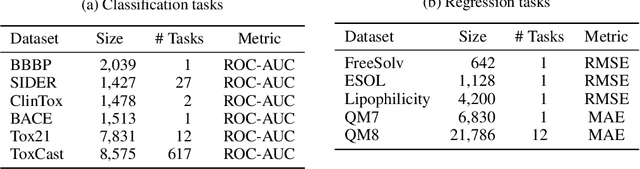
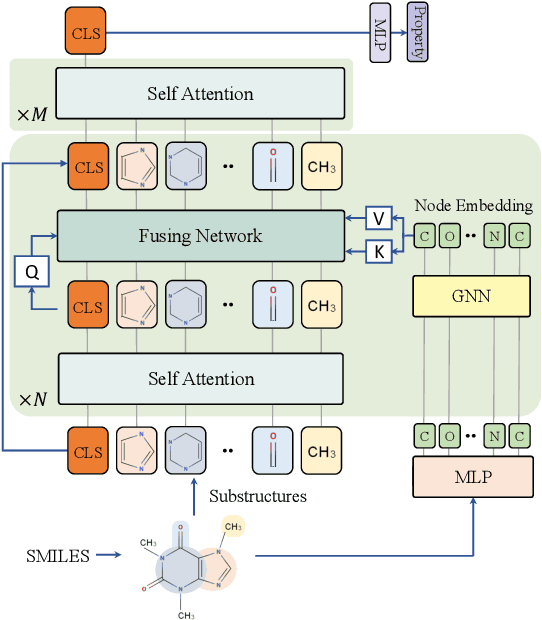
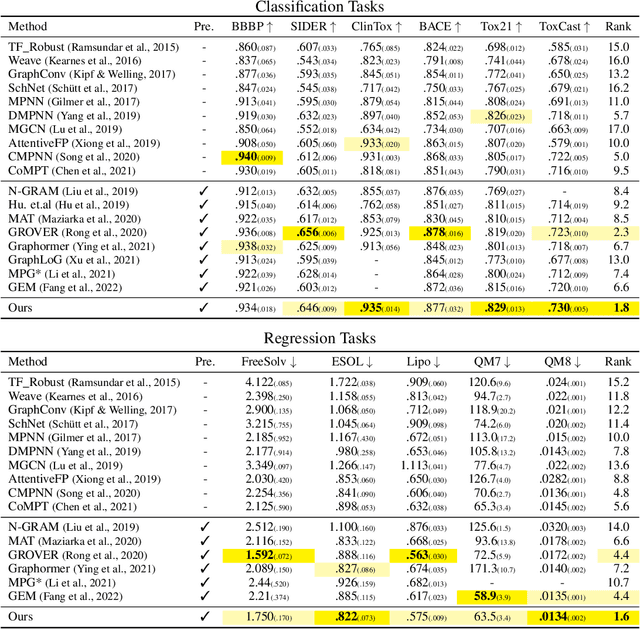
Designing a neural network architecture for molecular representation is crucial for AI-driven drug discovery and molecule design. In this work, we propose a new framework for molecular representation learning. Our contribution is threefold: (a) demonstrating the usefulness of incorporating substructures to node-wise features from molecules, (b) designing two branch networks consisting of a transformer and a graph neural network so that the networks fused with asymmetric attention, and (c) not requiring heuristic features and computationally-expensive information from molecules. Using 1.8 million molecules collected from ChEMBL and PubChem database, we pretrain our network to learn a general representation of molecules with minimal supervision. The experimental results show that our pretrained network achieves competitive performance on 11 downstream tasks for molecular property prediction.