 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeoReg: Weight-Constrained Few-Shot Regression for Socio-Economic Estimation using LLM
Jul 17, 2025



Socio-economic indicators like regional GDP, population, and education levels, are crucial to shaping policy decisions and fostering sustainable development. This research introduces GeoReg a regression model that integrates diverse data sources, including satellite imagery and web-based geospatial information, to estimate these indicators even for data-scarce regions such as developing countries. Our approach leverages the prior knowledge of large language model (LLM) to address the scarcity of labeled data, with the LLM functioning as a data engineer by extracting informative features to enable effective estimation in few-shot settings. Specifically, our model obtains contextual relationships between data features and the target indicator, categorizing their correlations as positive, negative, mixed, or irrelevant. These features are then fed into the linear estimator with tailored weight constraints for each category. To capture nonlinear patterns, the model also identifies meaningful feature interactions and integrates them, along with nonlinear transformations. Experiments across three countries at different stages of development demonstrate that our model outperforms baselines in estimating socio-economic indicators, even for low-income countries with limited data availability.
Lightweight and Robust Representation of Economic Scales from Satellite Imagery
Dec 18, 2019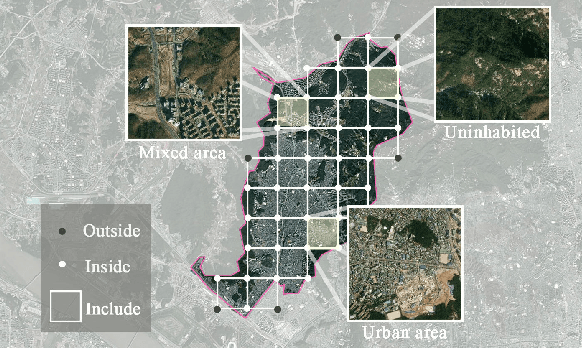

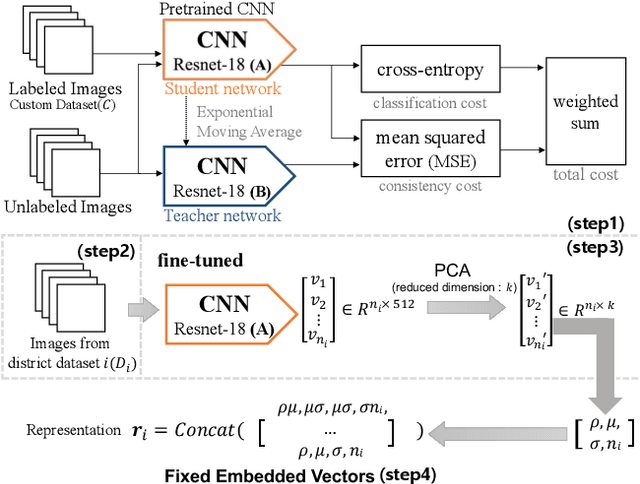
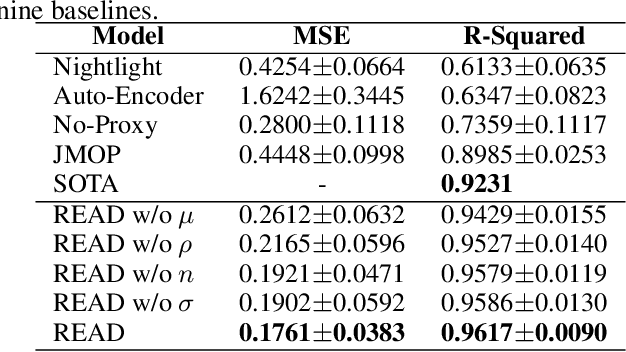
Satellite imagery has long been an attractive data source that provides a wealth of information on human-inhabited areas. While super resolution satellite images are rapidly becoming available, little study has focused on how to extract meaningful information about human habitation patterns and economic scales from such data. We present READ, a new approach for obtaining essential spatial representation for any given district from high-resolution satellite imagery based on deep neural networks. Our method combines transfer learning and embedded statistics to efficiently learn critical spatial characteristics of arbitrary size areas and represent them into a fixed-length vector with minimal information loss. Even with a small set of labels, READ can distinguish subtle differences between rural and urban areas and infer the degree of urbanization. An extensive evaluation demonstrates the model outperforms the state-of-the-art in predicting economic scales, such as population density for South Korea (R^2=0.9617), and shows a high potential use for developing countries where district-level economic scales are not known.