 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnlocking Robust Semantic Segmentation Performance via Label-only Elastic Deformations against Implicit Label Noise
Aug 14, 2025



While previous studies on image segmentation focus on handling severe (or explicit) label noise, real-world datasets also exhibit subtle (or implicit) label imperfections. These arise from inherent challenges, such as ambiguous object boundaries and annotator variability. Although not explicitly present, such mild and latent noise can still impair model performance. Typical data augmentation methods, which apply identical transformations to the image and its label, risk amplifying these subtle imperfections and limiting the model's generalization capacity. In this paper, we introduce NSegment+, a novel augmentation framework that decouples image and label transformations to address such realistic noise for semantic segmentation. By introducing controlled elastic deformations only to segmentation labels while preserving the original images, our method encourages models to focus on learning robust representations of object structures despite minor label inconsistencies. Extensive experiments demonstrate that NSegment+ consistently improves performance, achieving mIoU gains of up to +2.29, +2.38, +1.75, and +3.39 in average on Vaihingen, LoveDA, Cityscapes, and PASCAL VOC, respectively-even without bells and whistles, highlighting the importance of addressing implicit label noise. These gains can be further amplified when combined with other training tricks, including CutMix and Label Smoothing.
DiVa: An Accelerator for Differentially Private Machine Learning
Aug 26, 2022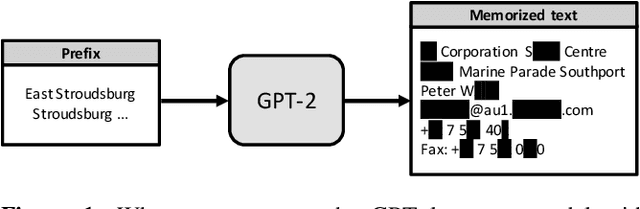
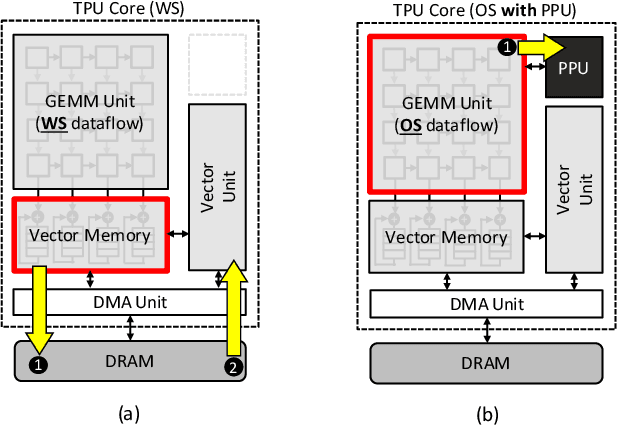
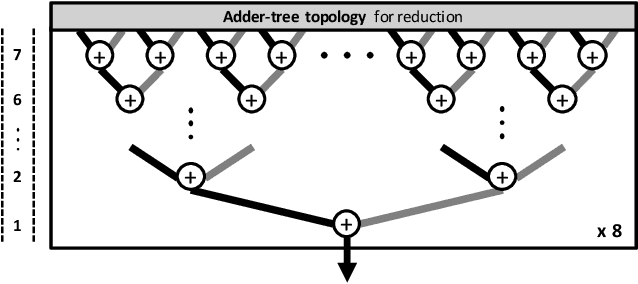
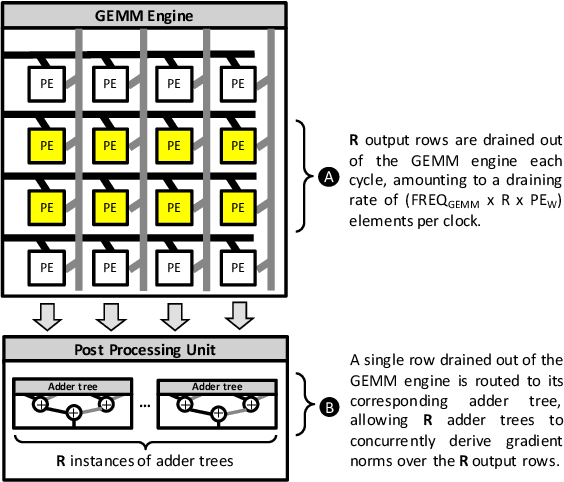
The widespread deployment of machine learning (ML) is raising serious concerns on protecting the privacy of users who contributed to the collection of training data. Differential privacy (DP) is rapidly gaining momentum in the industry as a practical standard for privacy protection. Despite DP's importance, however, little has been explored within the computer systems community regarding the implication of this emerging ML algorithm on system designs. In this work, we conduct a detailed workload characterization on a state-of-the-art differentially private ML training algorithm named DP-SGD. We uncover several unique properties of DP-SGD (e.g., its high memory capacity and computation requirements vs. non-private ML), root-causing its key bottlenecks. Based on our analysis, we propose an accelerator for differentially private ML named DiVa, which provides a significant improvement in compute utilization, leading to 2.6x higher energy-efficiency vs. conventional systolic arrays.