 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnlocking Robust Semantic Segmentation Performance via Label-only Elastic Deformations against Implicit Label Noise
Aug 14, 2025



While previous studies on image segmentation focus on handling severe (or explicit) label noise, real-world datasets also exhibit subtle (or implicit) label imperfections. These arise from inherent challenges, such as ambiguous object boundaries and annotator variability. Although not explicitly present, such mild and latent noise can still impair model performance. Typical data augmentation methods, which apply identical transformations to the image and its label, risk amplifying these subtle imperfections and limiting the model's generalization capacity. In this paper, we introduce NSegment+, a novel augmentation framework that decouples image and label transformations to address such realistic noise for semantic segmentation. By introducing controlled elastic deformations only to segmentation labels while preserving the original images, our method encourages models to focus on learning robust representations of object structures despite minor label inconsistencies. Extensive experiments demonstrate that NSegment+ consistently improves performance, achieving mIoU gains of up to +2.29, +2.38, +1.75, and +3.39 in average on Vaihingen, LoveDA, Cityscapes, and PASCAL VOC, respectively-even without bells and whistles, highlighting the importance of addressing implicit label noise. These gains can be further amplified when combined with other training tricks, including CutMix and Label Smoothing.
ARTSeg: Employing Attention for Thermal images Semantic Segmentation
Nov 30, 2021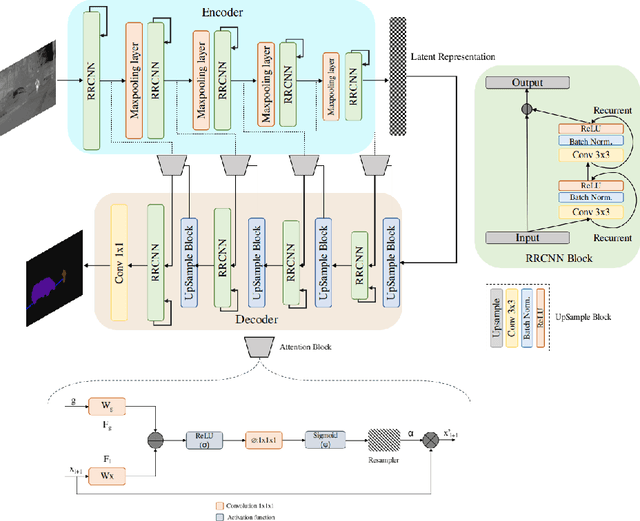
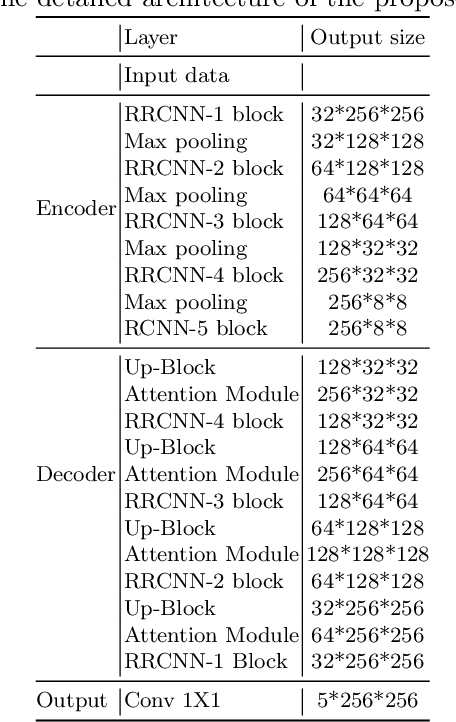
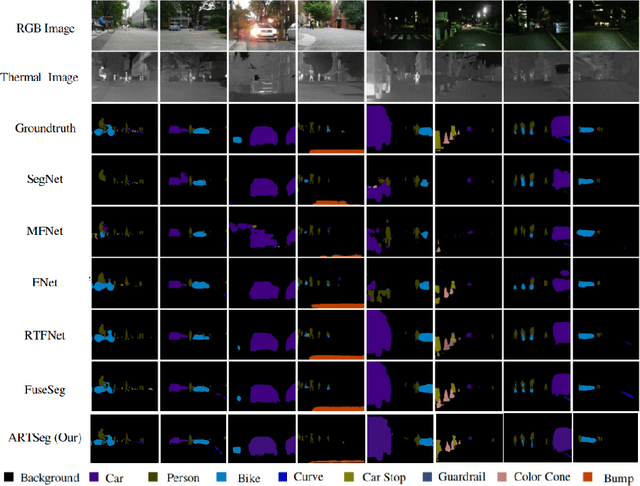
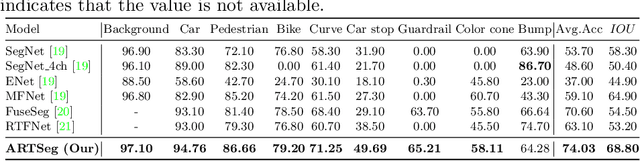
The research advancements have made the neural network algorithms deployed in the autonomous vehicle to perceive the surrounding. The standard exteroceptive sensors that are utilized for the perception of the environment are cameras and Lidar. Therefore, the neural network algorithms developed using these exteroceptive sensors have provided the necessary solution for the autonomous vehicle's perception. One major drawback of these exteroceptive sensors is their operability in adverse weather conditions, for instance, low illumination and night conditions. The useability and affordability of thermal cameras in the sensor suite of the autonomous vehicle provide the necessary improvement in the autonomous vehicle's perception in adverse weather conditions. The semantics of the environment benefits the robust perception, which can be achieved by segmenting different objects in the scene. In this work, we have employed the thermal camera for semantic segmentation. We have designed an attention-based Recurrent Convolution Network (RCNN) encoder-decoder architecture named ARTSeg for thermal semantic segmentation. The main contribution of this work is the design of encoder-decoder architecture, which employ units of RCNN for each encoder and decoder block. Furthermore, additive attention is employed in the decoder module to retain high-resolution features and improve the localization of features. The efficacy of the proposed method is evaluated on the available public dataset, showing better performance with other state-of-the-art methods in mean intersection over union (IoU).