 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAIM-SLAM: Dense Monocular SLAM via Adaptive and Informative Multi-View Keyframe Prioritization with Foundation Model
Mar 05, 2026Recent advances in geometric foundation models have emerged as a promising alternative for addressing the challenge of dense reconstruction in monocular visual simultaneous localization and mapping (SLAM). Although geometric foundation models enable SLAM to leverage variable input views, the previous methods remain confined to two-view pairs or fixed-length inputs without sufficient deliberation of geometric context for view selection. To tackle this problem, we propose AIM-SLAM, a dense monocular SLAM framework that exploits an adaptive and informative multi-view keyframe prioritization with dense pointmap predictions from visual geometry grounded transformer (VGGT). Specifically, we introduce the selective information- and geometric-aware multi-view adaptation (SIGMA) module, which employs voxel overlap and information gain to retrieve a candidate set of keyframes and adaptively determine its size. Furthermore, we formulate a joint multi-view Sim(3) optimization that enforces consistent alignment across selected views, substantially improving pose estimation accuracy. The effectiveness of AIM-SLAM is demonstrated on real-world datasets, where it achieves state-of-the-art performance in both pose estimation and dense reconstruction. Our system supports ROS integration, with code is available at https://aimslam.github.io/.
PaGO-LOAM: Robust Ground-Optimized LiDAR Odometry
Jun 01, 2022



Numerous researchers have conducted studies to achieve fast and robust ground-optimized LiDAR odometry methods for terrestrial mobile platforms. In particular, ground-optimized LiDAR odometry usually employs ground segmentation as a preprocessing method. This is because most of the points in a 3D point cloud captured by a 3D LiDAR sensor on a terrestrial platform are from the ground. However, the effect of the performance of ground segmentation on LiDAR odometry is still not closely examined. In this paper, a robust ground-optimized LiDAR odometry framework is proposed to facilitate the study to check the effect of ground segmentation on LiDAR SLAM based on the state-of-the-art (SOTA) method. By using our proposed odometry framework, it is easy and straightforward to test whether ground segmentation algorithms help extract well-described features and thus improve SLAM performance. In addition, by leveraging the SOTA ground segmentation method called Patchwork, which shows robust ground segmentation even in complex and uneven urban environments with little performance perturbation, a novel ground-optimized LiDAR odometry is proposed, called PaGO-LOAM. The methods were tested using the KITTI odometry dataset. \textit{PaGO-LOAM} shows robust and accurate performance compared with the baseline method. Our code is available at https://github.com/url-kaist/AlterGround-LeGO-LOAM.
Struct-MDC: Mesh-Refined Unsupervised Depth Completion Leveraging Structural Regularities from Visual SLAM
Apr 29, 2022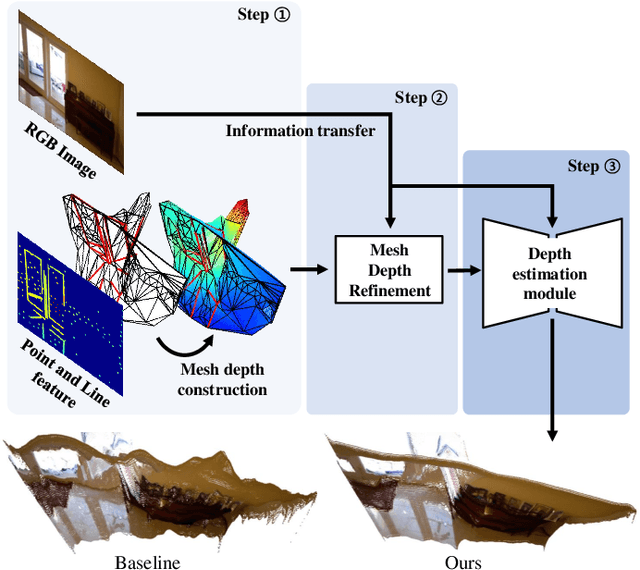

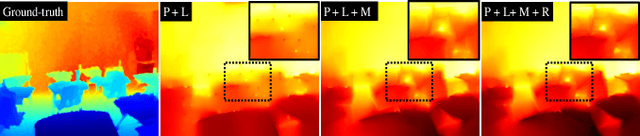
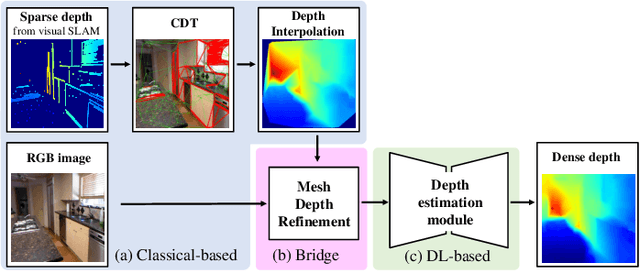
Feature-based visual simultaneous localization and mapping (SLAM) methods only estimate the depth of extracted features, generating a sparse depth map. To solve this sparsity problem, depth completion tasks that estimate a dense depth from a sparse depth have gained significant importance in robotic applications like exploration. Existing methodologies that use sparse depth from visual SLAM mainly employ point features. However, point features have limitations in preserving structural regularities owing to texture-less environments and sparsity problems. To deal with these issues, we perform depth completion with visual SLAM using line features, which can better contain structural regularities than point features. The proposed methodology creates a convex hull region by performing constrained Delaunay triangulation with depth interpolation using line features. However, the generated depth includes low-frequency information and is discontinuous at the convex hull boundary. Therefore, we propose a mesh depth refinement (MDR) module to address this problem. The MDR module effectively transfers the high-frequency details of an input image to the interpolated depth and plays a vital role in bridging the conventional and deep learning-based approaches. The Struct-MDC outperforms other state-of-the-art algorithms on public and our custom datasets, and even outperforms supervised methodologies for some metrics. In addition, the effectiveness of the proposed MDR module is verified by a rigorous ablation study.