 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSmall Towers Make Big Differences
Aug 13, 2020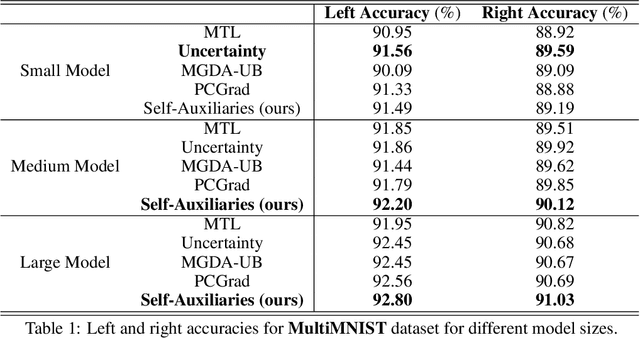
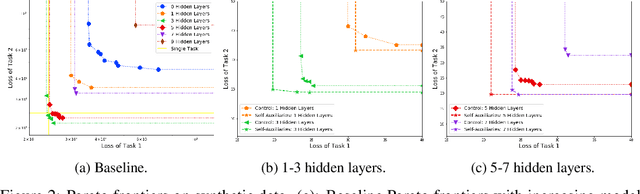
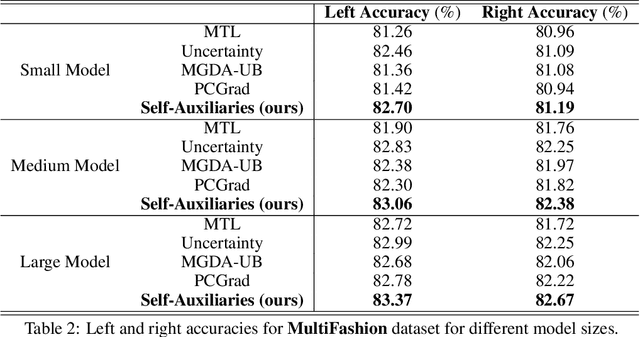
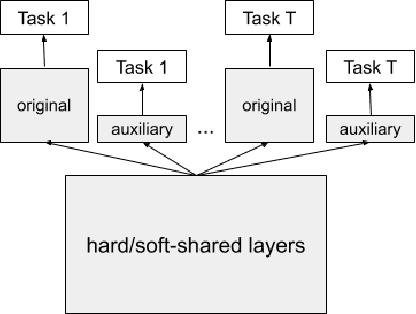
Multi-task learning aims at solving multiple machine learning tasks at the same time. A good solution to a multi-task learning problem should be generalizable in addition to being Pareto optimal. In this paper, we provide some insights on understanding the trade-off between Pareto efficiency and generalization as a result of parameterization in multi-task deep learning models. As a multi-objective optimization problem, enough parameterization is needed for handling task conflicts in a constrained solution space; however, from a multi-task generalization perspective, over-parameterization undermines the benefit of learning a shared representation which helps harder tasks or tasks with limited training examples. A delicate balance between multi-task generalization and multi-objective optimization is therefore needed for finding a better trade-off between efficiency and generalization. To this end, we propose a method of under-parameterized self-auxiliaries for multi-task models to achieve the best of both worlds. It is task-agnostic and works with other multi-task learning algorithms. Empirical results show that small towers of under-parameterized self-auxiliaries can make big differences in improving Pareto efficiency in various multi-task applications.
Understanding and Improving Knowledge Distillation
Feb 10, 2020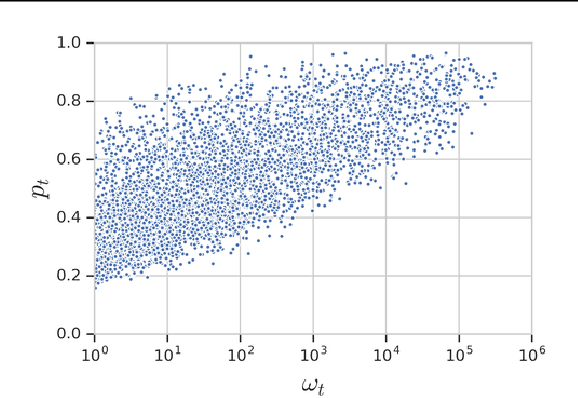
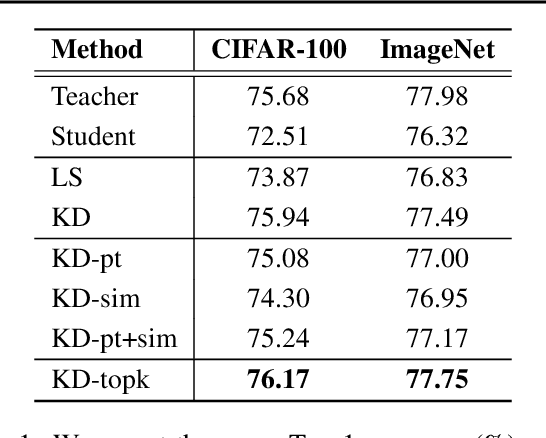
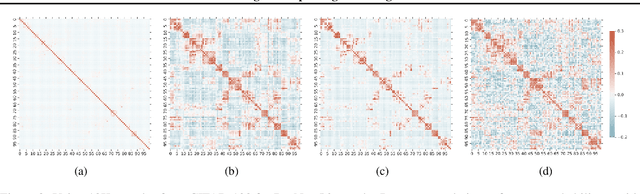
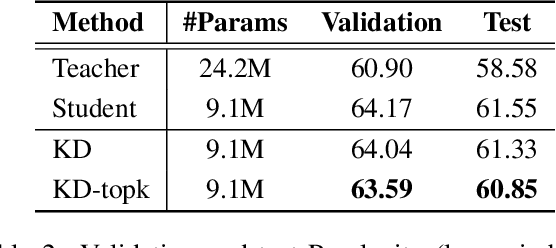
Knowledge distillation is a model-agnostic technique to improve model quality while having a fixed capacity budget. It is a commonly used technique for model compression, where a higher capacity teacher model with better quality is used to train a more compact student model with better inference efficiency. Through distillation, one hopes to benefit from student's compactness, without sacrificing too much on model quality. Despite the large success of knowledge distillation, better understanding of how it benefits student model's training dynamics remains under-explored. In this paper, we dissect the effects of knowledge distillation into three main factors: (1) benefits inherited from label smoothing, (2) example re-weighting based on teacher's confidence on ground-truth, and (3) prior knowledge of optimal output (logit) layer geometry. Using extensive systematic analyses and empirical studies on synthetic and real-world datasets, we confirm that the aforementioned three factors play a major role in knowledge distillation. Furthermore, based on our findings, we propose a simple, yet effective technique to improve knowledge distillation empirically.