 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResource Utilization of Differentiable Logic Gate Networks Deployed on FPGAs
May 04, 2026On-edge machine learning (ML) often strives to maximize the intelligence of small models while miniaturizing the circuit size and power needed to perform inference. Meeting these needs, differentiable Logic Gate Networks (LGN) have demonstrated nanosecond-scale prediction speeds while reducing the required resources as compares to traditional binary neural networks. Despite these benefits, the trade-offs between LGN parameters and resulting hardware synthesis characteristics are not well characterized. This paper therefore studies the tradeoffs between power, resource utilization, inference speed, and model accuracy when varying the depth and width of LGNs synthesized for Field Programmable Gate Arrays (FPGA). Results reveal that the final layer of an LGN is critical to minimize timing and resource usage (i.e. 28\% decrease), as this layer dictates the logic size of summing operations. Subject to timing and routing constraints, deeper and wider LGNs can be synthesized for FPGA when the final layer is narrow. Further tradeoffs are presented to help ML engineers select baseline LGN architectures for FPGAs with a set number of Look Up Tables (LUT).
Causal AI For AMS Circuit Design: Interpretable Parameter Effects Analysis
Mar 24, 2026Analog-mixed-signal (AMS) circuits are highly non-linear and operate on continuous real-world signals, making them far more difficult to model with data-driven AI than digital blocks. To close the gap between structured design data (device dimensions, bias voltages, etc.) and real-world performance, we propose a causal-inference framework that first discovers a directed-acyclic graph (DAG) from SPICE simulation data and then quantifies parameter impact through Average Treatment Effect (ATE) estimation. The approach yields human-interpretable rankings of design knobs and explicit 'what-if' predictions, enabling designers to understand trade-offs in sizing and topology. We evaluate the pipeline on three operational-amplifier families (OTA, telescopic, and folded-cascode) implemented in TSMC 65nm and benchmark it against a baseline neural-network (NN) regressor. Across all circuits the causal model reproduces simulation-based ATEs with an average absolute error of less than 25%, whereas the neural network deviates by more than 80% and frequently predicts the wrong sign. These results demonstrate that causal AI provides both higher accuracy and explainability, paving the way for more efficient, trustworthy AMS design automation.
eXpLogic: Explaining Logic Types and Patterns in DiffLogic Networks
Mar 13, 2025Constraining deep neural networks (DNNs) to learn individual logic types per node, as performed using the DiffLogic network architecture, opens the door to model-specific explanation techniques that quell the complexity inherent to DNNs. Inspired by principles of circuit analysis from computer engineering, this work presents an algorithm (eXpLogic) for producing saliency maps which explain input patterns that activate certain functions. The eXpLogic explanations: (1) show the exact set of inputs responsible for a decision, which helps interpret false negative and false positive predictions, (2) highlight common input patterns that activate certain outputs, and (3) help reduce the network size to improve class-specific inference. To evaluate the eXpLogic saliency map, we introduce a metric that quantifies how much an input changes before switching a model's class prediction (the SwitchDist) and use this metric to compare eXpLogic against the Vanilla Gradients (VG) and Integrated Gradient (IG) methods. Generally, we show that eXpLogic saliency maps are better at predicting which inputs will change the class score. These maps help reduce the network size and inference times by 87\% and 8\%, respectively, while having a limited impact (-3.8\%) on class-specific predictions. The broader value of this work to machine learning is in demonstrating how certain DNN architectures promote explainability, which is relevant to healthcare, defense, and law.
Programmable EM Sensor Array for Golden-Model Free Run-time Trojan Detection and Localization
Jan 22, 2024



Side-channel analysis has been proven effective at detecting hardware Trojans in integrated circuits (ICs). However, most detection techniques rely on large external probes and antennas for data collection and require a long measurement time to detect Trojans. Such limitations make these techniques impractical for run-time deployment and ineffective in detecting small Trojans with subtle side-channel signatures. To overcome these challenges, we propose a Programmable Sensor Array (PSA) for run-time hardware Trojan detection, localization, and identification. PSA is a tampering-resilient integrated on-chip magnetic field sensor array that can be re-programmed to change the sensors' shape, size, and location. Using PSA, EM side-channel measurement results collected from sensors at different locations on an IC can be analyzed to localize and identify the Trojan. The PSA has better performance than conventional external magnetic probes and state-of-the-art on-chip single-coil magnetic field sensors. We fabricated an AES-128 test chip with four AES Hardware Trojans. They were successfully detected, located, and identified with the proposed on-chip PSA within 10 milliseconds using our proposed cross-domain analysis.
A Survey and Perspective on Artificial Intelligence for Security-Aware Electronic Design Automation
Apr 21, 2022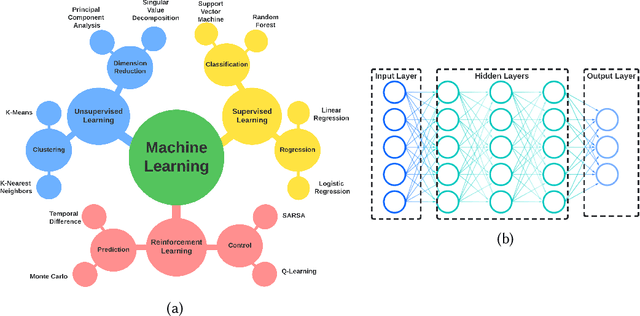
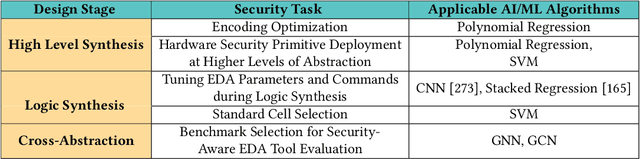
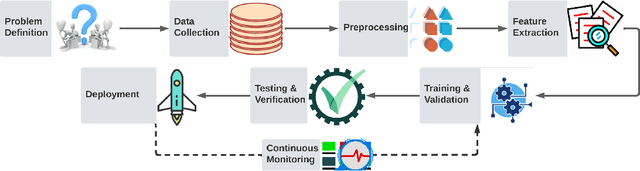
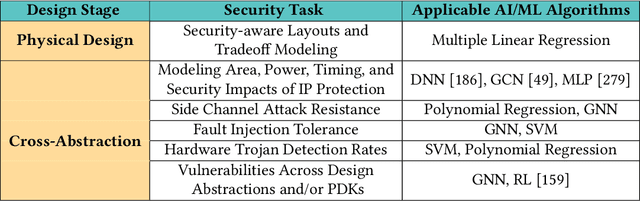
Artificial intelligence (AI) and machine learning (ML) techniques have been increasingly used in several fields to improve performance and the level of automation. In recent years, this use has exponentially increased due to the advancement of high-performance computing and the ever increasing size of data. One of such fields is that of hardware design; specifically the design of digital and analog integrated circuits~(ICs), where AI/ ML techniques have been extensively used to address ever-increasing design complexity, aggressive time-to-market, and the growing number of ubiquitous interconnected devices (IoT). However, the security concerns and issues related to IC design have been highly overlooked. In this paper, we summarize the state-of-the-art in AL/ML for circuit design/optimization, security and engineering challenges, research in security-aware CAD/EDA, and future research directions and needs for using AI/ML for security-aware circuit design.
Histogram-based Auto Segmentation: A Novel Approach to Segmenting Integrated Circuit Structures from SEM Images
Apr 28, 2020
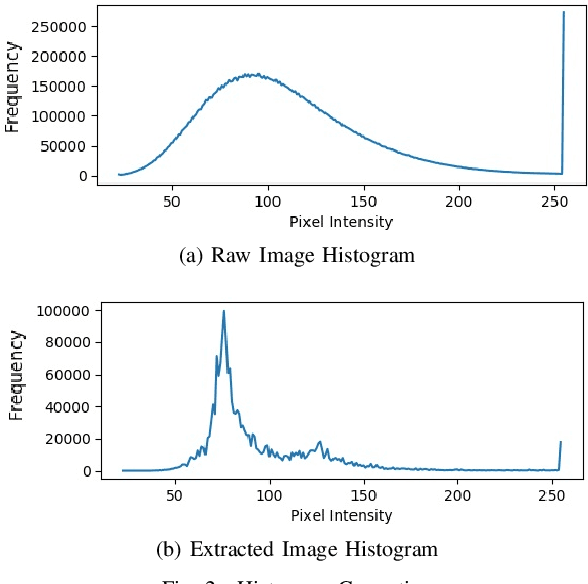
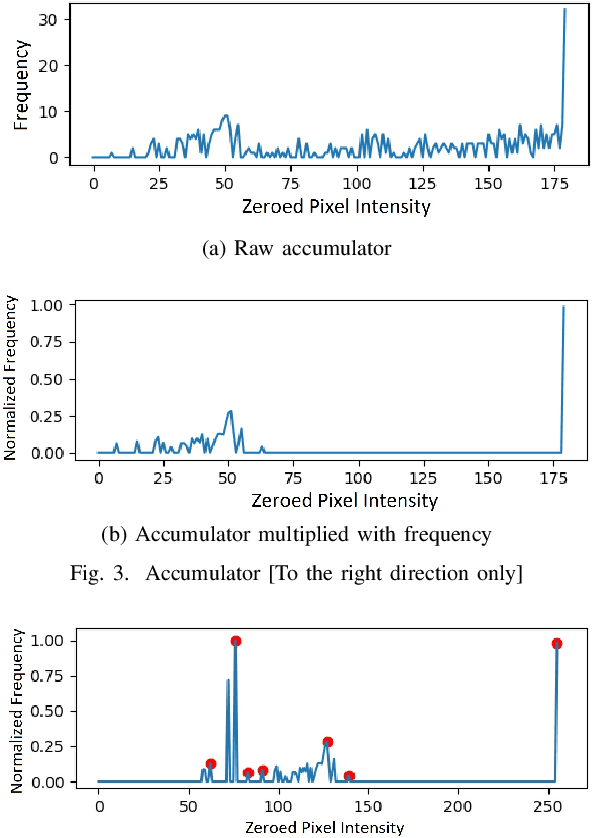

In the Reverse Engineering and Hardware Assurance domain, a majority of the data acquisition is done through electron microscopy techniques such as Scanning Electron Microscopy (SEM). However, unlike its counterparts in optical imaging, only a limited number of techniques are available to enhance and extract information from the raw SEM images. In this paper, we introduce an algorithm to segment out Integrated Circuit (IC) structures from the SEM image. Unlike existing algorithms discussed in this paper, this algorithm is unsupervised, parameter-free and does not require prior information on the noise model or features in the target image making it effective in low quality image acquisition scenarios as well. Furthermore, the results from the application of the algorithm on various structures and layers in the IC are reported and discussed.
Attack of the Genes: Finding Keys and Parameters of Locked Analog ICs Using Genetic Algorithm
Mar 31, 2020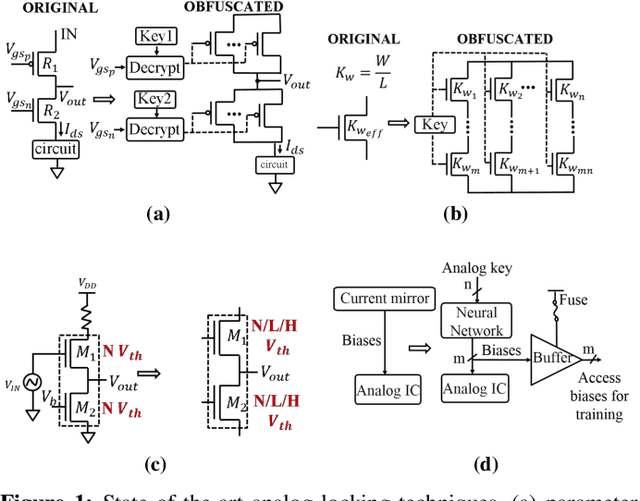
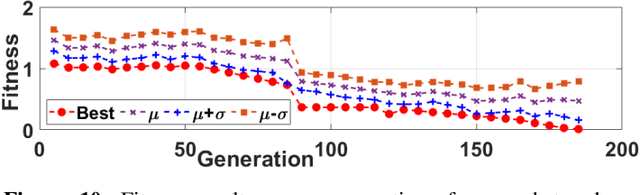
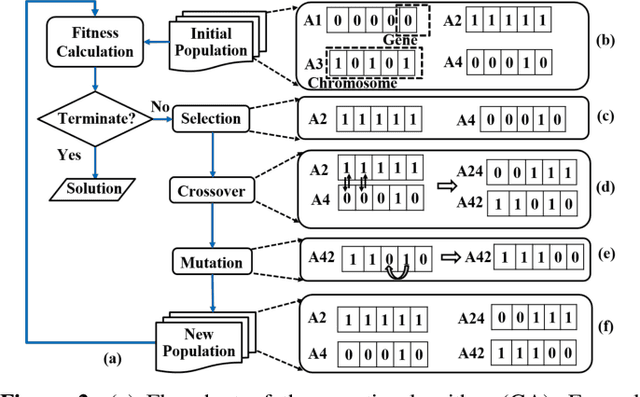
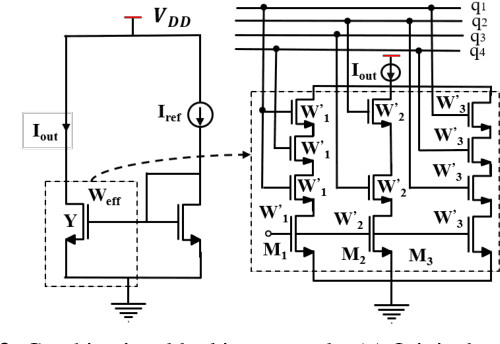
Hardware intellectual property (IP) theft is a major issue in today's globalized supply chain. To address it, numerous logic locking and obfuscation techniques have been proposed. While locking initially focused on digital integrated circuits (ICs), there have been recent attempts to extend it to analog ICs, which are easier to reverse engineer and to copy than digital ICs. In this paper, we use algorithms based on evolutionary strategies to investigate the security of analog obfuscation/locking techniques. We present a genetic algorithm (GA) approach which is capable of completely breaking a locked analog circuit by finding either its obfuscation key or its obfuscated parameters. We implement both the GA attack as well as a more naive satisfiability modulo theory (SMT)-based attack on common analog benchmark circuits obfuscated by combinational locking and parameter biasing. We find that GA attack can unlock all the circuits using only the locked netlist and an unlocked chip in minutes. On the other hand, while the SMT attack converges faster, it requires circuit specification to execute and it also returns multiple keys that need to be brute-forced by a post-processing step. We also discuss how the GA attack can generalize to other recent analog locking techniques not tested in the paper