 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImage Matching across Wide Baselines: From Paper to Practice
Mar 03, 2020
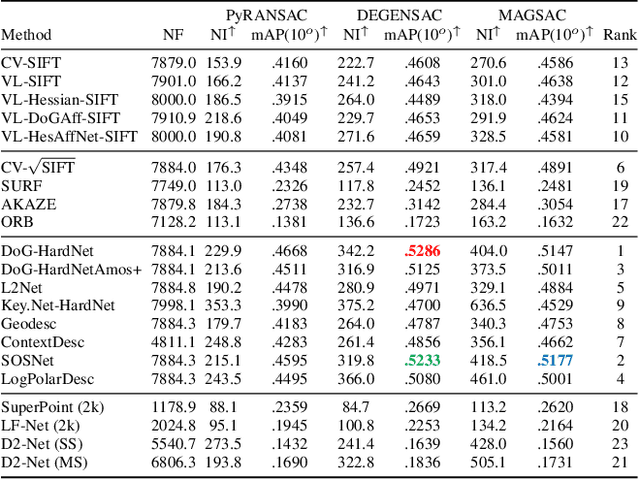

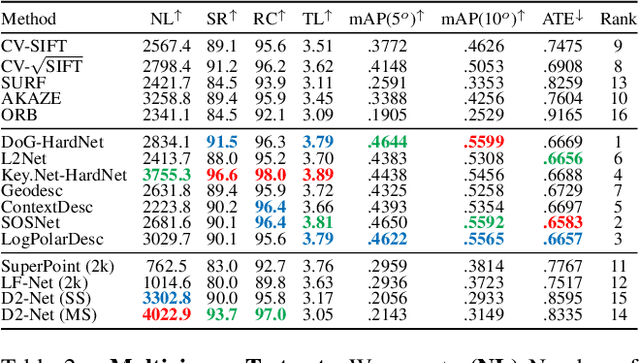
We introduce a comprehensive benchmark for local features and robust estimation algorithms, focusing on the downstream task -- the accuracy of the reconstructed camera pose -- as our primary metric. Our pipeline's modular structure allows us to easily integrate, configure, and combine methods and heuristics. We demonstrate this by embedding dozens of popular algorithms and evaluating them, from seminal works to the cutting edge of machine learning research. We show that with proper settings, classical solutions may still outperform the perceived state of the art. Besides establishing the actual state of the art, the experiments conducted in this paper reveal unexpected properties of SfM pipelines that can be exploited to help improve their performance, for both algorithmic and learned methods. Data and code are online https://github.com/vcg-uvic/image-matching-benchmark, providing an easy-to-use and flexible framework for the benchmarking of local feature and robust estimation methods, both alongside and against top-performing methods. This work provides the basis for an open challenge on wide-baseline image matching https://vision.uvic.ca/image-matching-challenge .
Kornia: an Open Source Differentiable Computer Vision Library for PyTorch
Oct 09, 2019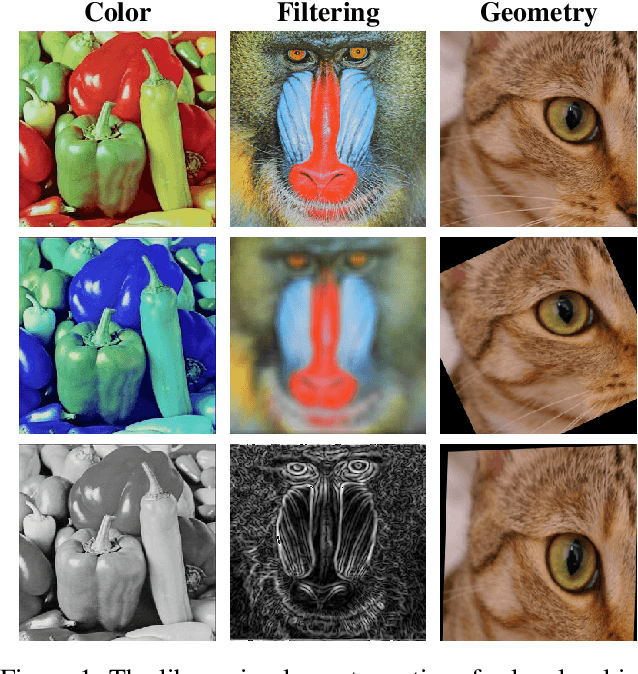

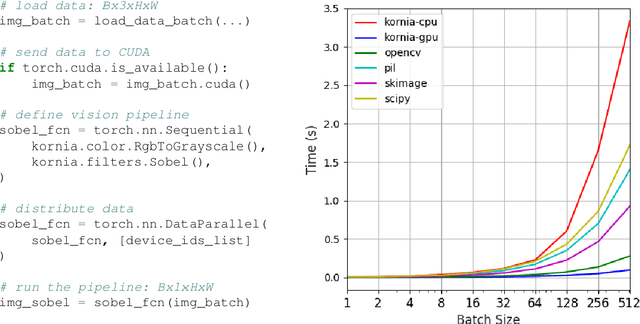
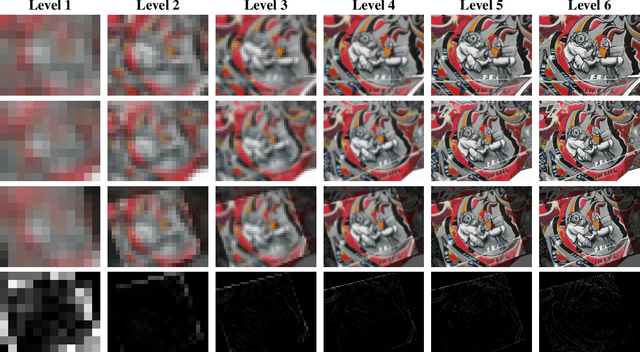
This work presents Kornia -- an open source computer vision library which consists of a set of differentiable routines and modules to solve generic computer vision problems. The package uses PyTorch as its main backend both for efficiency and to take advantage of the reverse-mode auto-differentiation to define and compute the gradient of complex functions. Inspired by OpenCV, Kornia is composed of a set of modules containing operators that can be inserted inside neural networks to train models to perform image transformations, camera calibration, epipolar geometry, and low level image processing techniques, such as filtering and edge detection that operate directly on high dimensional tensor representations. Examples of classical vision problems implemented using our framework are provided including a benchmark comparing to existing vision libraries.
Benchmarking Classic and Learned Navigation in Complex 3D Environments
Mar 28, 2019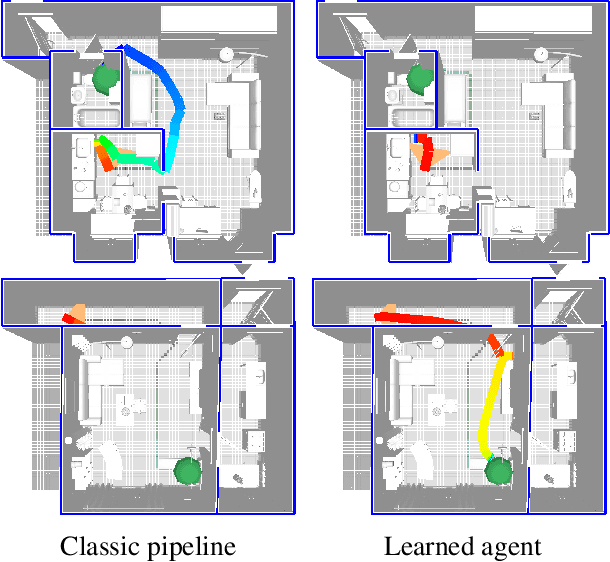
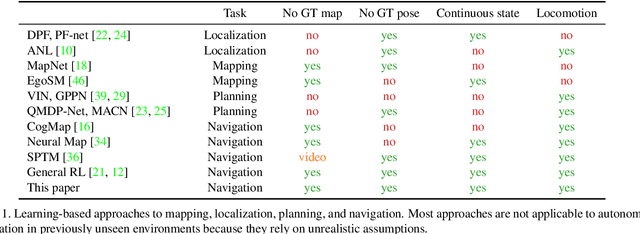
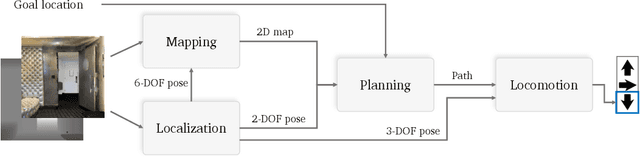
Navigation research is attracting renewed interest with the advent of learning-based methods. However, this new line of work is largely disconnected from well-established classic navigation approaches. In this paper, we take a step towards coordinating these two directions of research. We set up classic and learning-based navigation systems in common simulated environments and thoroughly evaluate them in indoor spaces of varying complexity, with access to different sensory modalities. Additionally, we measure human performance in the same environments. We find that a classic pipeline, when properly tuned, can perform very well in complex cluttered environments. On the other hand, learned systems can operate more robustly with a limited sensor suite. Overall, both approaches are still far from human-level performance.
Leveraging Outdoor Webcams for Local Descriptor Learning
Jan 28, 2019

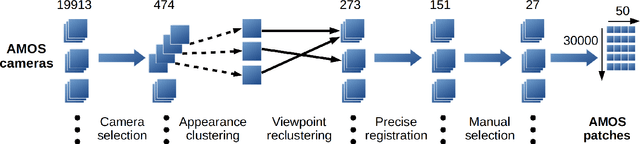

We present AMOS Patches, a large set of image cut-outs, intended primarily for the robustification of trainable local feature descriptors to illumination and appearance changes. Images contributing to AMOS Patches originate from the AMOS dataset of recordings from a large set of outdoor webcams. The semiautomatic method used to generate AMOS Patches is described. It includes camera selection, viewpoint clustering and patch selection. For training, we provide both the registered full source images as well as the patches. A new descriptor, trained on the AMOS Patches and 6Brown datasets, is introduced. It achieves state-of-the-art in matching under illumination changes on standard benchmarks.
Repeatability Is Not Enough: Learning Affine Regions via Discriminability
Aug 28, 2018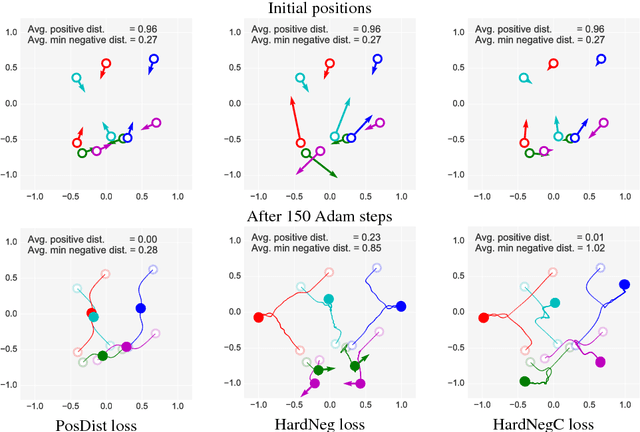
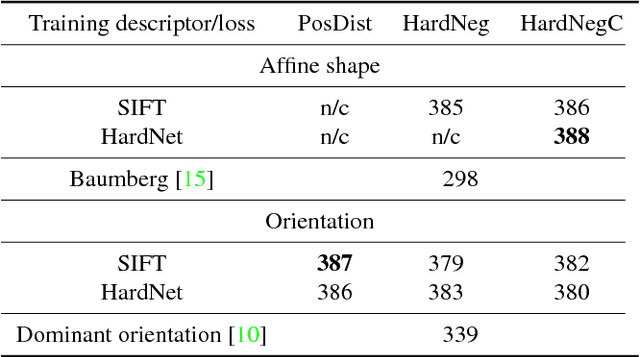
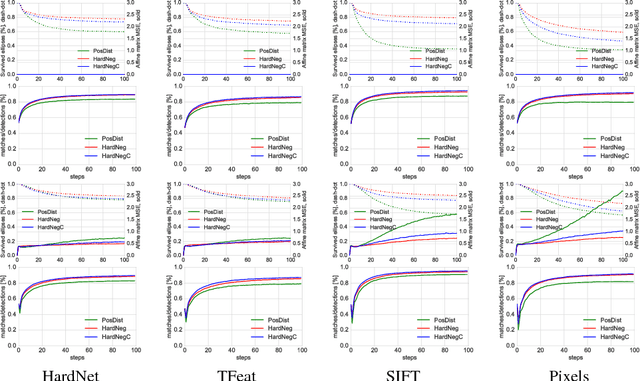
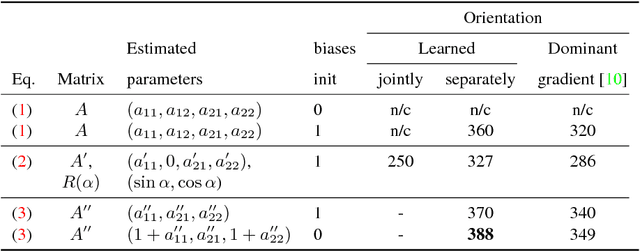
A method for learning local affine-covariant regions is presented. We show that maximizing geometric repeatability does not lead to local regions, a.k.a features,that are reliably matched and this necessitates descriptor-based learning. We explore factors that influence such learning and registration: the loss function, descriptor type, geometric parametrization and the trade-off between matchability and geometric accuracy and propose a novel hard negative-constant loss function for learning of affine regions. The affine shape estimator -- AffNet -- trained with the hard negative-constant loss outperforms the state-of-the-art in bag-of-words image retrieval and wide baseline stereo. The proposed training process does not require precisely geometrically aligned patches.The source codes and trained weights are available at https://github.com/ducha-aiki/affnet
DeblurGAN: Blind Motion Deblurring Using Conditional Adversarial Networks
Apr 03, 2018
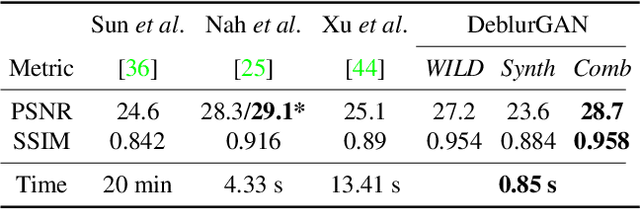


We present DeblurGAN, an end-to-end learned method for motion deblurring. The learning is based on a conditional GAN and the content loss . DeblurGAN achieves state-of-the art performance both in the structural similarity measure and visual appearance. The quality of the deblurring model is also evaluated in a novel way on a real-world problem -- object detection on (de-)blurred images. The method is 5 times faster than the closest competitor -- DeepDeblur. We also introduce a novel method for generating synthetic motion blurred images from sharp ones, allowing realistic dataset augmentation. The model, code and the dataset are available at https://github.com/KupynOrest/DeblurGAN
Working hard to know your neighbor's margins: Local descriptor learning loss
Jan 12, 2018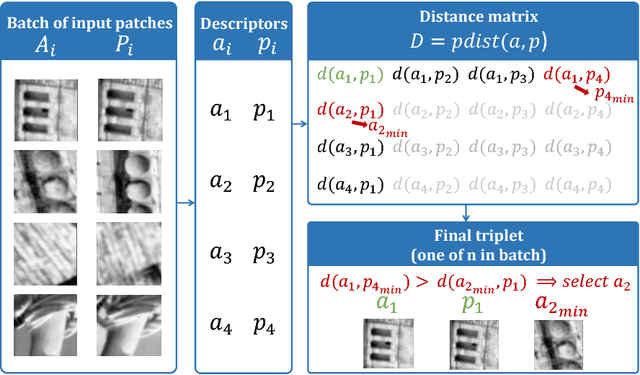
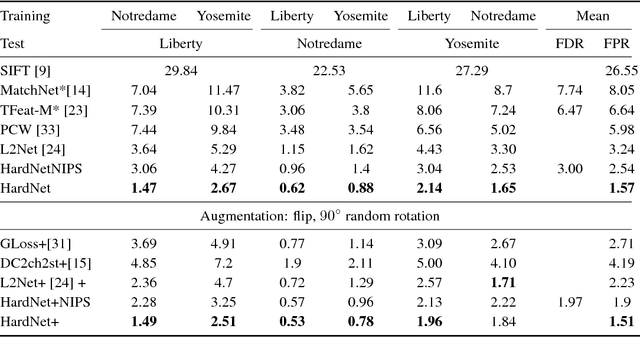
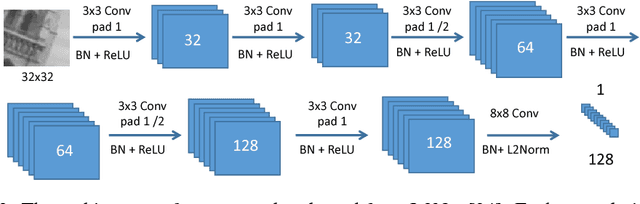
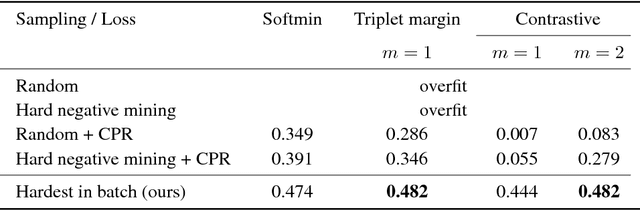
We introduce a novel loss for learning local feature descriptors which is inspired by the Lowe's matching criterion for SIFT. We show that the proposed loss that maximizes the distance between the closest positive and closest negative patch in the batch is better than complex regularization methods; it works well for both shallow and deep convolution network architectures. Applying the novel loss to the L2Net CNN architecture results in a compact descriptor -- it has the same dimensionality as SIFT (128) that shows state-of-art performance in wide baseline stereo, patch verification and instance retrieval benchmarks. It is fast, computing a descriptor takes about 1 millisecond on a low-end GPU.
In the Saddle: Chasing Fast and Repeatable Features
Aug 24, 2016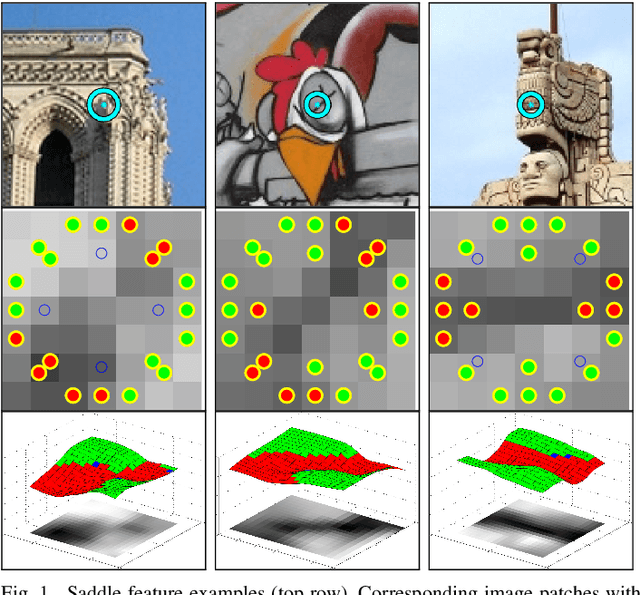
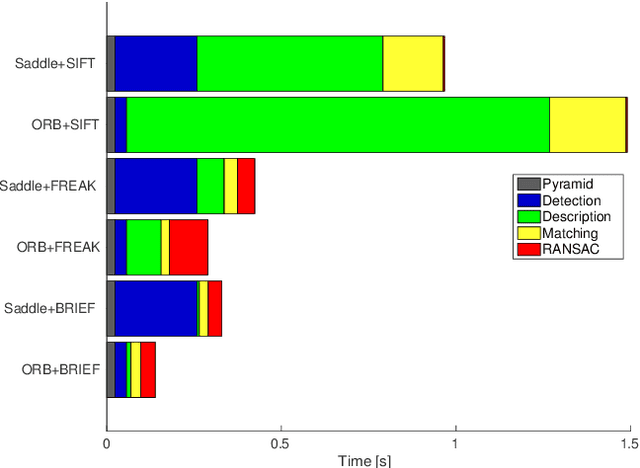

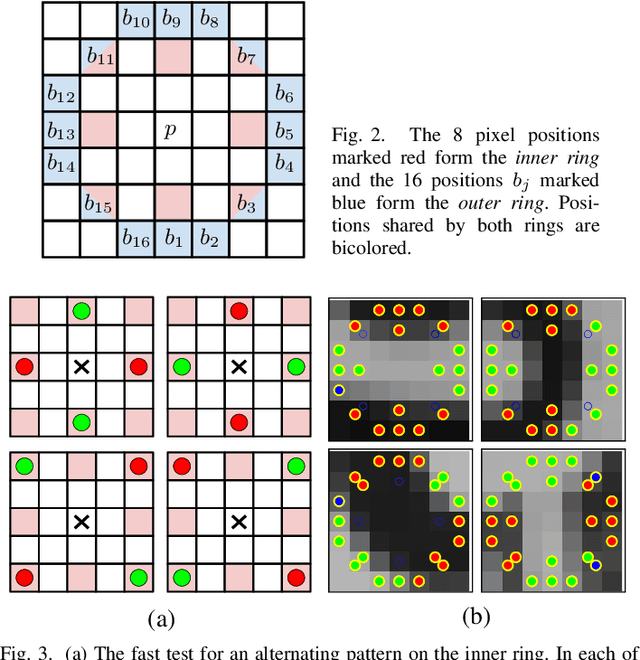
A novel similarity-covariant feature detector that extracts points whose neighbourhoods, when treated as a 3D intensity surface, have a saddle-like intensity profile. The saddle condition is verified efficiently by intensity comparisons on two concentric rings that must have exactly two dark-to-bright and two bright-to-dark transitions satisfying certain geometric constraints. Experiments show that the Saddle features are general, evenly spread and appearing in high density in a range of images. The Saddle detector is among the fastest proposed. In comparison with detector with similar speed, the Saddle features show superior matching performance on number of challenging datasets.
Systematic evaluation of CNN advances on the ImageNet
Jun 13, 2016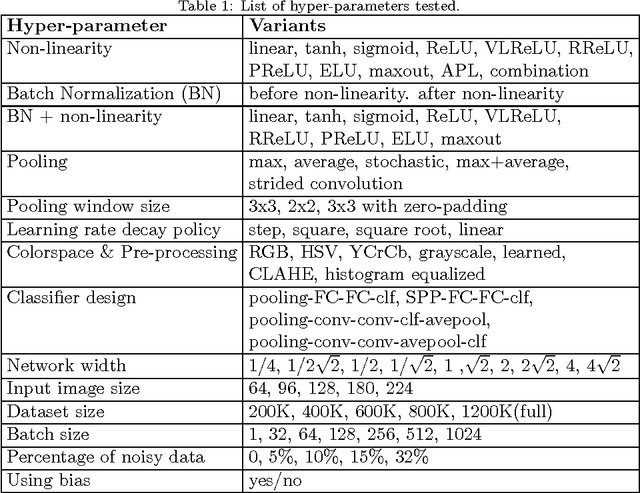
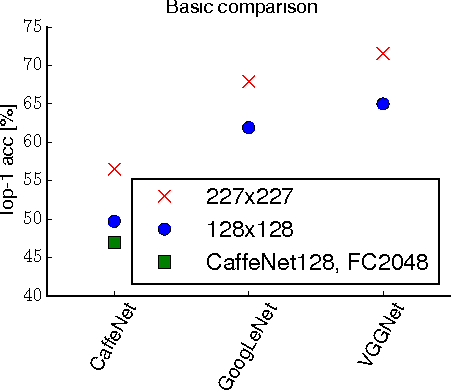
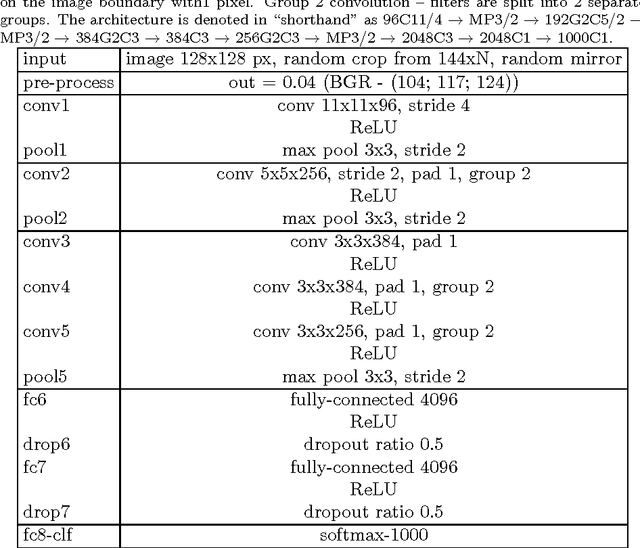
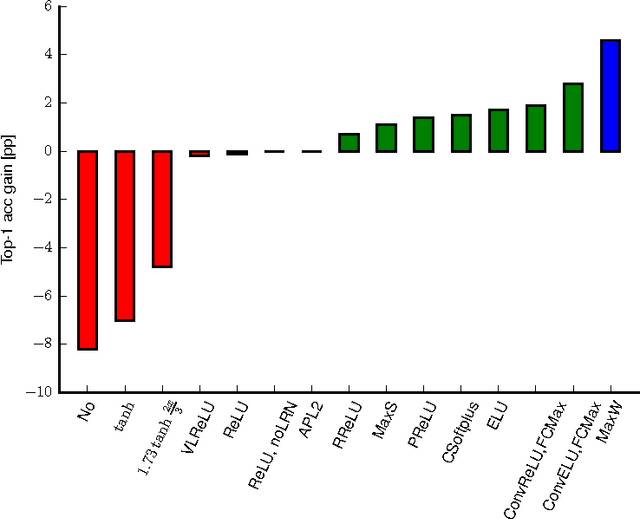
The paper systematically studies the impact of a range of recent advances in CNN architectures and learning methods on the object categorization (ILSVRC) problem. The evalution tests the influence of the following choices of the architecture: non-linearity (ReLU, ELU, maxout, compatibility with batch normalization), pooling variants (stochastic, max, average, mixed), network width, classifier design (convolutional, fully-connected, SPP), image pre-processing, and of learning parameters: learning rate, batch size, cleanliness of the data, etc. The performance gains of the proposed modifications are first tested individually and then in combination. The sum of individual gains is bigger than the observed improvement when all modifications are introduced, but the "deficit" is small suggesting independence of their benefits. We show that the use of 128x128 pixel images is sufficient to make qualitative conclusions about optimal network structure that hold for the full size Caffe and VGG nets. The results are obtained an order of magnitude faster than with the standard 224 pixel images.
MODS: Fast and Robust Method for Two-View Matching
May 01, 2016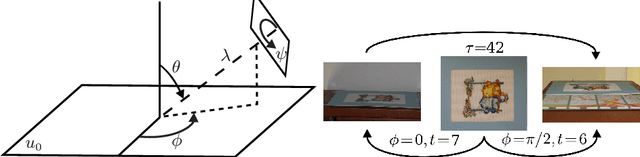

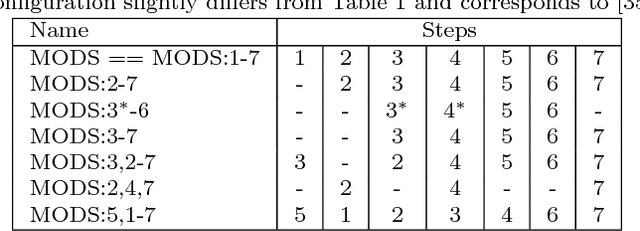

A novel algorithm for wide-baseline matching called MODS - Matching On Demand with view Synthesis - is presented. The MODS algorithm is experimentally shown to solve a broader range of wide-baseline problems than the state of the art while being nearly as fast as standard matchers on simple problems. The apparent robustness vs. speed trade-off is finessed by the use of progressively more time-consuming feature detectors and by on-demand generation of synthesized images that is performed until a reliable estimate of geometry is obtained. We introduce an improved method for tentative correspondence selection, applicable both with and without view synthesis. A modification of the standard first to second nearest distance rule increases the number of correct matches by 5-20% at no additional computational cost. Performance of the MODS algorithm is evaluated on several standard publicly available datasets, and on a new set of geometrically challenging wide baseline problems that is made public together with the ground truth. Experiments show that the MODS outperforms the state-of-the-art in robustness and speed. Moreover, MODS performs well on other classes of difficult two-view problems like matching of images from different modalities, with wide temporal baseline or with significant lighting changes.